Command Palette
Search for a command to run...
LLaDA2.0-Uni : Unifier la compréhension et la génération multimodales avec un Large Language Model de diffusion
LLaDA2.0-Uni : Unifier la compréhension et la génération multimodales avec un Large Language Model de diffusion
Résumé
Nous présentons LLaDA2.0-Uni, un grand modèle de langage à diffusion discrète (dLLM) unifié qui prend en charge la compréhension et la génération multimodales au sein d'un cadre nativement intégré. Son architecture combine un tokenizer discret entièrement sémantique, un backbone dLLM basé sur une architecture MoE (Mixture-of-Experts), et un décodeur de diffusion. En discrétisant les entrées visuelles continues via SigLIP-VQ, le modèle permet une diffusion masquée au niveau des blocs (block-level masked diffusion) pour les entrées textuelles et visuelles au sein du backbone, tandis que le décodeur reconstruit les tokens visuels en images de haute fidélité.L'efficacité de l'inférence est améliorée au-delà du simple décodage parallèle grâce à des optimisations sensibles au préfixe (prefix-aware) dans le backbone et une distillation en quelques étapes (few-step distillation) dans le décodeur. S'appuyant sur des données à grande échelle soigneusement sélectionnées et un pipeline d'entraînement multi-étapes sur mesure, LLaDA2.0-Uni égale les performances des VLM (Vision-Language Models) spécialisés en matière de compréhension multimodale, tout en offrant des performances robustes en génération et édition d'images. Son support natif pour la génération et le raisonnement entrelacés (interleaved generation and reasoning) établit un paradigme prometteur et évolutif pour la prochaine génération de modèles de fondation unifiés.Le code et les modèles sont disponibles à l'adresse suivante : https://github.com/inclusionAI/LLaDA2.0-Uni.
One-sentence Summary
LLaDA2.0-Uni is a unified discrete diffusion large language model that integrates multimodal understanding and generation within a single framework by combining a MoE-based backbone and a diffusion decoder, utilizing SigLIP-VQ for visual discretization and block-level masked diffusion to enable interleaved reasoning and high-fidelity image synthesis.
Key Contributions
- The paper introduces LLaDA2.0-Uni, a unified architecture that integrates a fully semantic tokenizer, a 16B MoE discrete large language model backbone, and a diffusion decoder to enable multimodal understanding and generation through a shared block-wise mask prediction objective.
- The method enables interleaved generation and reasoning by using a SigLIP-VQ tokenizer to map visual inputs into semantically rich discrete tokens, allowing text and images to be modeled within a single shared space.
- The framework enhances inference efficiency by combining prefix-aware optimizations in the backbone with few-step distillation in the decoder, achieving strong performance across multimodal understanding, image generation, and editing benchmarks.
Introduction
Multimodal models aim to bridge the gap between visual understanding and image generation to achieve more efficient deployment and advanced reasoning capabilities. While current unified models often rely on autoregressive architectures or hybrid paradigms, existing masked diffusion approaches struggle with poor semantic understanding, loss of visual quality due to excessive compression, and unreliable text modeling. The authors leverage a 16B Mixture-of-Experts diffusion large language model (dLLM) backbone to introduce LLaDA2.0-Uni, a framework that unifies both modalities through a shared block-level masked diffusion objective. By utilizing a novel SigLIP-VQ tokenizer to convert visual inputs into discrete semantic tokens, the authors enable seamless interleaved generation and reasoning while maintaining high performance across understanding and generation benchmarks.
Dataset
The authors utilize a diverse array of datasets to train the model across several specialized capabilities:
- Multimodal Understanding: Pre-training involves extensive image-captioning data from open-source sources, supplemented by specialized subsets. This includes OCR data produced via a coarse-to-fine pipeline using PaddleOCR and Qwen3-VL, as well as grounding and counting data derived from Objects365 and RefCOCO. For the latter, the authors apply detection confidence filtering and verification via Qwen3-VL-235B-A22B, normalizing coordinates to a [0, 1000] range. SFT data consists of 60 million samples with a 1:5 ratio of text-only to multimodal data, covering various tasks like VQA and mathematical reasoning. Quality is maintained through a two-stage pipeline that uses Qwen3-VL for query auditing and GPT-OSS for response semantic filtering.
- Image Generation: The authors collect over 200 million web images, specifically increasing the proportion of images featuring human bodies and rendered text. A three-stage cleaning process filters for resolution (minimum 512 pixels), compression levels, aesthetics (ArtiMuse score > 60), and quality (DeQA-Score > 4.0), resulting in 140 million high-quality images. Captions are generated by Qwen3-VL-235B-22B, which incorporates informative original web text to ensure descriptive accuracy.
- Image Editing: This subset combines multiple open-source datasets with synthesized pairs created from the generation dataset. The authors use Qwen3-VL-235B-22B to refine instructions and filter out failed samples where edits produce artifacts or no observable change.
- Interleaved Data: The authors construct interleaved sequences from the Koala36M video corpus. Filtering criteria include duration (10 to 30 seconds), aesthetic score (> 4.0), clarity (> 0.7), and motion score (> 4). This process retains 6 million clips, from which frames are sampled every 5 seconds to create sequences of 2 to 6 frames. Qwen3-VL-235B-A22B is then used to generate detailed descriptions of actions and scene changes.
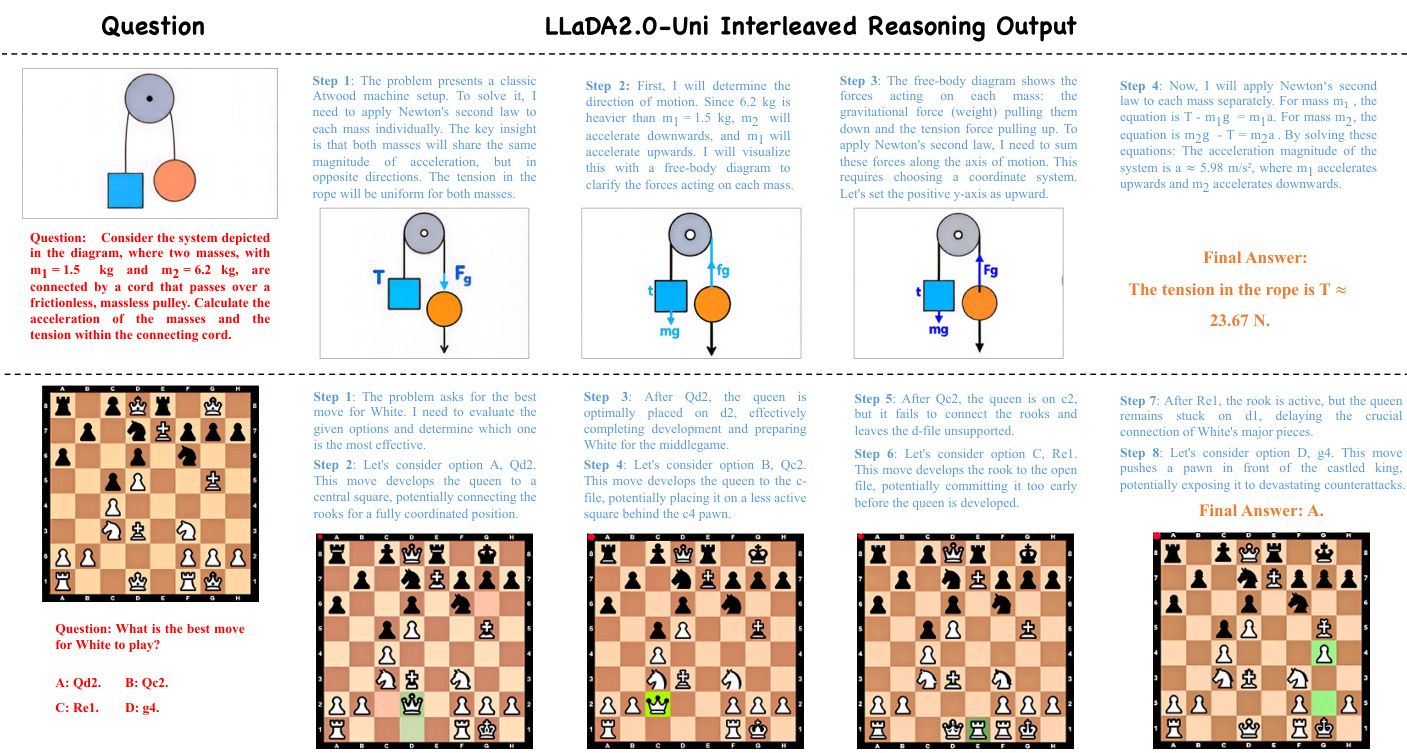
- Reasoning-Augmented Data: To support chain-of-thought capabilities, the authors incorporate approximately 8 million SFT samples from Flux-6M, Zebra-CoT, and Weave. This data focuses on reasoning-based image generation and interleaved reasoning.
Method
The architecture of LLaDA2.0-Uni is designed as a unified framework for multimodal understanding and generation, built upon a core pipeline that integrates a discrete tokenizer, a diffusion language model backbone, and a diffusion decoder. This design enables end-to-end training and inference for both comprehension and synthesis tasks using a shared discrete token representation. The model processes inputs through a modular framework where visual data is first converted into semantic tokens, processed within a multimodal language model, and then reconstructed into high-fidelity images.
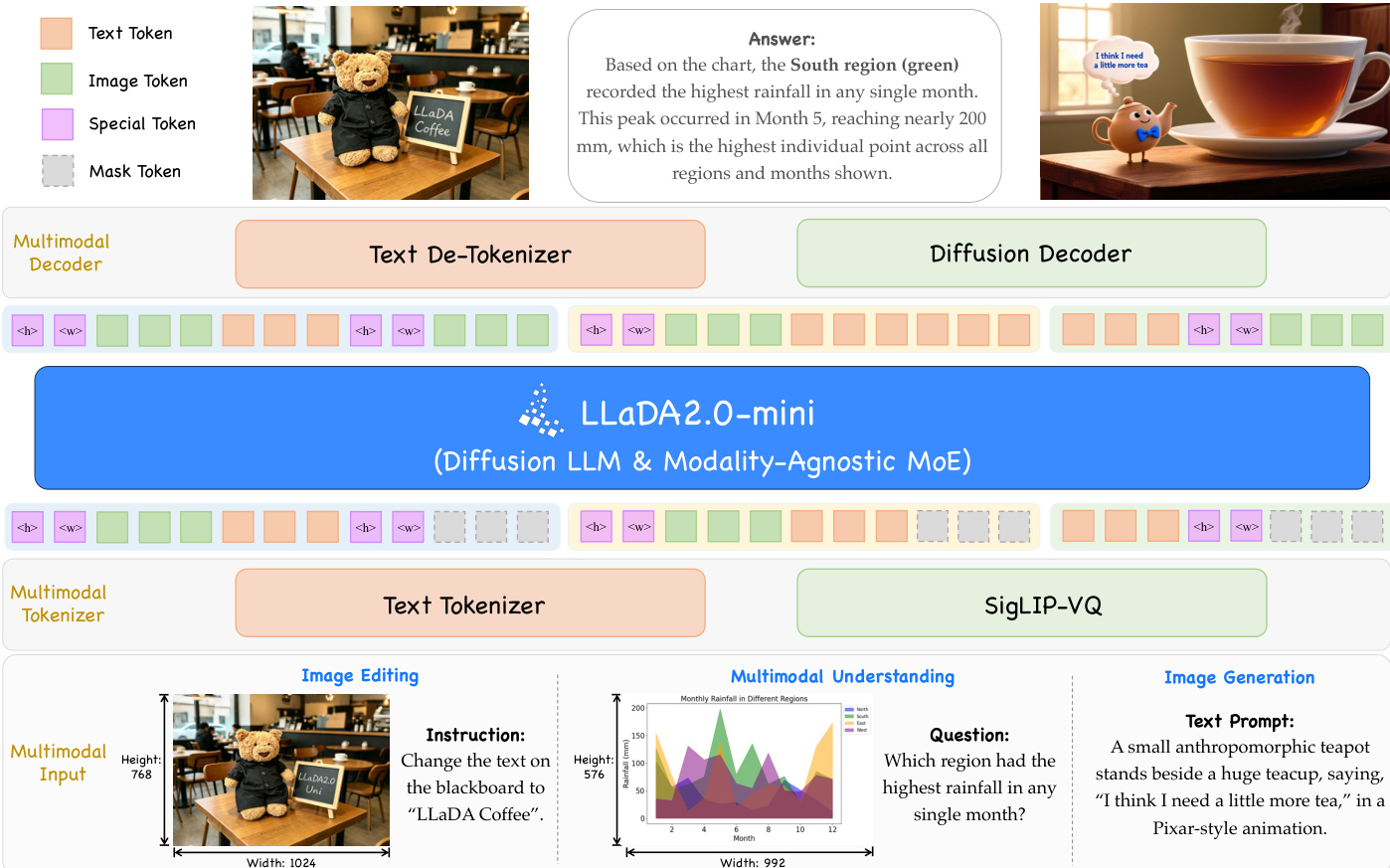
The process begins with the SigLIP-VQ tokenizer, which converts continuous image inputs into discrete semantic tokens. This tokenizer leverages a pre-trained SigLIP2-g ViT as a visual feature extractor, followed by a vector quantizer that maps the features to a codebook with a vocabulary size of 16,384 and a dimensionality of 2,048. Unlike reconstruction-based VQ-VAEs, SigLIP-VQ is trained directly on understanding tasks, prioritizing semantic fidelity over pixel-level accuracy. This results in a token representation that is highly suitable for multimodal reasoning but lacks a native mechanism for image reconstruction. To address this limitation, a custom diffusion decoder is employed, which operates on the discrete token sequence to generate high-resolution images. The tokenizer's ability to handle arbitrary resolutions is supported by incorporating special <height> and <width> tokens into the flattened 1D visual sequence, allowing the model to process images of varying dimensions without architectural modifications.
The core processing unit is a 16B Mixture-of-Experts (MoE) diffusion language model, built upon the LLaDA-2.0-mini architecture. This backbone is designed to handle both text and visual tokens under a unified mask prediction objective. To integrate visual information, the model's vocabulary is expanded to include tokens from the SigLIP-VQ codebook, along with custom special tokens for generation and understanding. The input embedding layer retains pre-trained language embeddings while initializing the new visual token embeddings randomly. The final prediction head is also expanded to accommodate the larger vocabulary, with the language-specific portion initialized from pre-trained weights to preserve linguistic proficiency. To ensure training stability and efficiency, the model employs a block-wise attention scheme, which constrains attention within predefined blocks and selectively enables it across blocks. This approach maintains the parallel decoding speed of full-attention models while mitigating the autoregressive bias introduced by the SigLIP-VQ tokens. The model utilizes 1D Rotary Position Embedding (RoPE) for positional encoding, with 2D spatial information encoded through the aforementioned <height> and <width> tokens.
The diffusion decoder is a 6B text-to-image model built upon Z-Image-Base, which takes the discrete visual tokens generated by the dLLM as its conditioning signal. This differs from existing methods that redundantly combine text prompts with visual tokens. The decoder performs 2× super-resolution, using the upsampled semantic tokens as the sole conditioning input. To reduce the computational cost of the standard 50-step sampling process, the decoder employs a lightweight consistency-based distillation framework. This method introduces a dual-output network that predicts both the standard velocity field and a consistency term. The distillation objective combines a flow matching loss with a consistency loss, enabling 8-step CFG-free inference while maintaining high image quality. This distillation process is trained in a three-stage manner: a warm-up stage to establish cross-modal alignment, a multi-domain generalization stage to improve robustness, and a high-fidelity refinement stage to enhance aesthetic details.
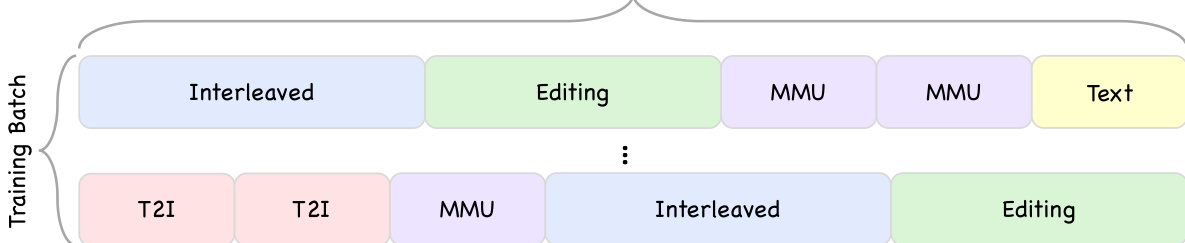
The training pipeline is composed of three distinct stages to progressively build the model's capabilities. The first stage, Vision-Language Alignment, focuses on aligning visual and linguistic representations within the dLLM backbone using high-quality image-caption pairs and visual knowledge datasets. A progressive arbitrary resolution scheme is adopted to handle long visual sequences, starting at 256×256 for generation and using 800×800 for understanding. The second stage, Multi-task Pre-training, expands the model's capabilities by training on diverse multimodal data, including image-text interleaved data, OCR, visual counting, and various generation tasks like image editing and style transfer. The final stage is Supervised Fine-Tuning (SFT), which is conducted in two phases: an initial 8k context length phase for instruction-following and a subsequent 16k context length phase for complex visual reasoning and generation.

Training optimization is achieved through several key strategies. The model uses the Block Diffusion Language Model (BDLM) objective, which operates on block-level masked regions to enable parallel decoding while maintaining coherent context. In MoE models, load balancing is crucial to prevent expert collapse, and the authors adopt an auxiliary-loss-free mechanism that promotes uniform workload distribution by updating a bias term based on the difference between current and ideal expert load. For SFT, a mask token reweighting loss is introduced to handle variable-length sequences, where the loss is weighted by the inverse square root of the number of masked tokens in each sample to equilibrate gradient contributions. Complementary masking is also employed to enhance data efficiency by constructing two antithetical training instances from a single sequence, ensuring every token position appears uncorrupted exactly once per pair. The model's training efficiency is further improved by pre-extracting image tokens offline, which eliminates repeated encoder passes, and by using a data packing strategy that concatenates multiple shorter samples into fixed-length sequences to minimize padding and improve GPU utilization.
Experiment
LLaDA2.0-Uni is evaluated across a wide range of benchmarks to validate its multimodal understanding, text-to-image generation, instruction-based image editing, and interleaved generation capabilities. The results demonstrate that the model effectively closes the gap between unified architectures and specialized models, achieving performance on par with top-tier experts in reasoning, OCR, and compositional image generation. Furthermore, the model shows strong proficiency in complex tasks such as multi-region text rendering and interleaved reasoning while maintaining high visual quality through accelerated decoding methods.
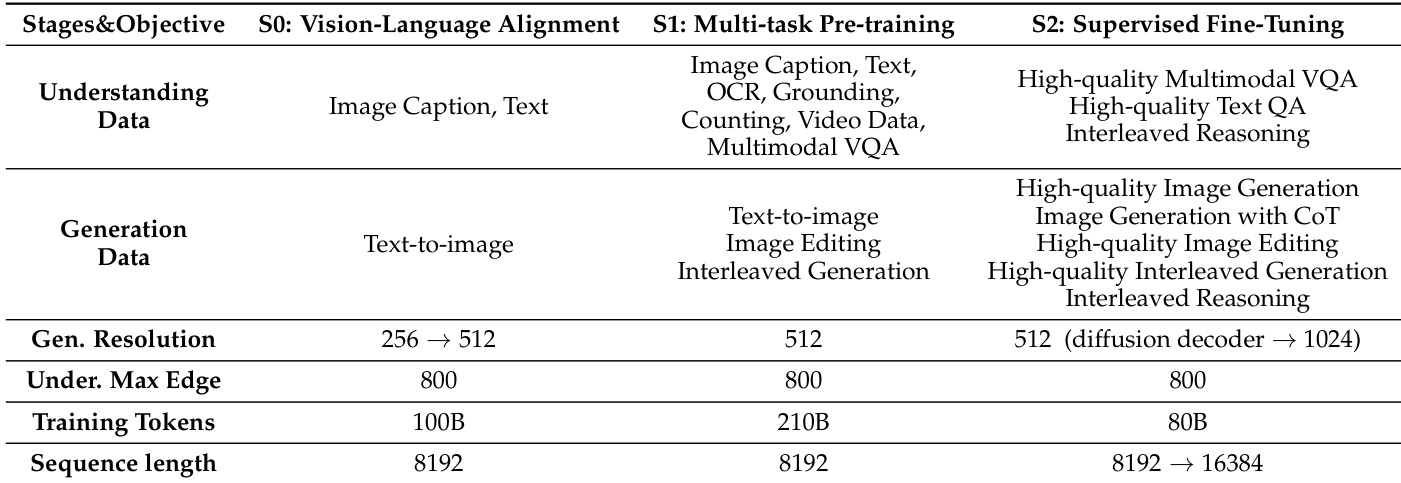
The the the table outlines the training stages and objectives of LLaDA2.0-Uni, detailing the progression from vision-language alignment to supervised fine-tuning. It highlights key training parameters such as data types, resolution, token count, and sequence length across different phases, emphasizing the model's development in both understanding and generation capabilities. LLaDA2.0-Uni progresses through three stages: vision-language alignment, multi-task pre-training, and supervised fine-tuning, each with distinct data types and objectives. The model's training resolution increases from 256 to 512 and then to 1024, indicating a focus on improving image generation quality. Training tokens and sequence length grow significantly across stages, reflecting the increasing complexity and scale of the model's pre-training and fine-tuning processes.
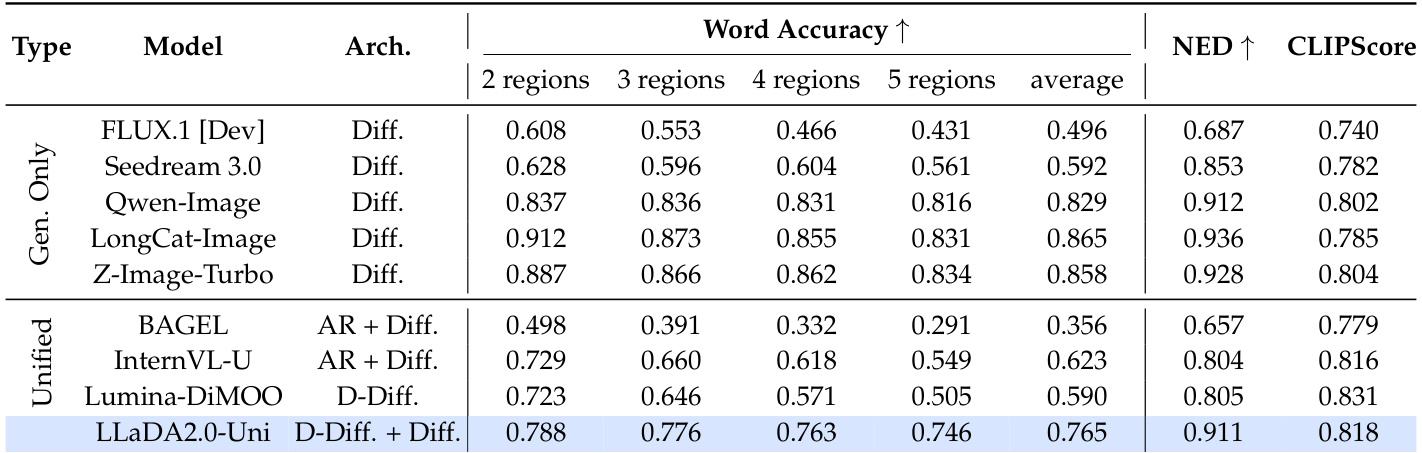
The the the table presents a comparison of text rendering performance across various models on the CVTG-2K benchmark, focusing on multi-region text generation. LLaDA2.0-Uni demonstrates superior stability as the number of regions increases, maintaining higher scores compared to other unified models. The results show that LLaDA2.0-Uni leads among unified models in overall performance and maintains strong consistency in text rendering across multiple regions. LLaDA2.0-Uni outperforms other unified models in multi-region text generation stability. LLaDA2.0-Uni achieves the highest overall score among unified models on the CVTG-2K benchmark. LLaDA2.0-Uni maintains consistent performance as the number of regions increases, unlike other models that show sharp declines.
The authors compare the performance and speed of a standard diffusion decoder with a turbo version that uses fewer steps. Results show that the turbo decoder achieves a significant speedup while maintaining competitive performance across multiple benchmarks, with minimal differences in scores and visual quality. The performance remains consistent across various tasks, including general generation, text-to-image generation, and reasoning-informed image generation. The turbo decoder achieves a substantial speedup while maintaining performance comparable to the standard decoder across multiple benchmarks. Performance metrics such as GenEval, DPG, and UniGenBench show minimal degradation with the turbo decoder, indicating robustness. The visual quality remains nearly indistinguishable between the standard and turbo decoders, confirming consistent output fidelity.

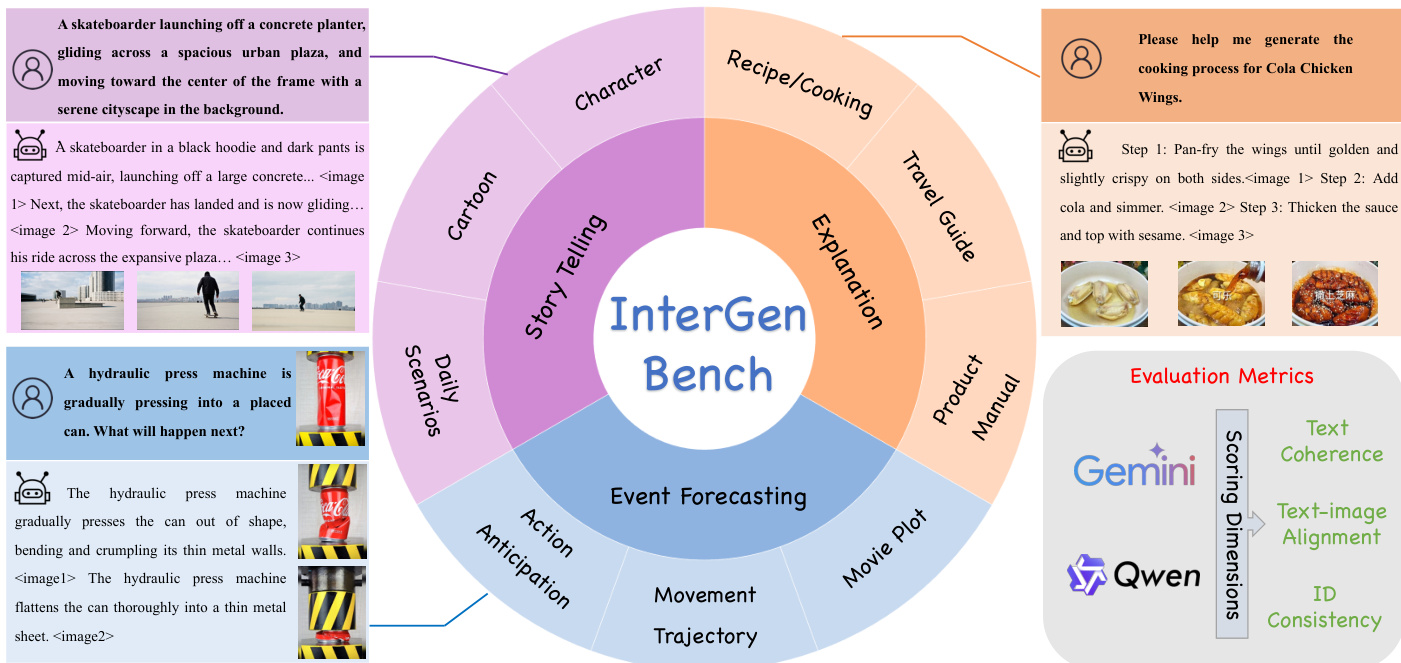
The authors evaluate LLaDA2.0-Uni on the InterGen benchmark, comparing it to Emu3.5 in interleaved generation tasks that require both text and image understanding. Results show that LLaDA2.0-Uni outperforms Emu3.5 in Story Telling and Event Forecasting, while achieving comparable performance in Explanation. The model demonstrates strong capabilities in generating coherent and aligned multimodal outputs across different reasoning and narrative tasks. LLaDA2.0-Uni achieves higher scores than Emu3.5 in Story Telling and Event Forecasting on the InterGen benchmark. LLaDA2.0-Uni performs comparably to Emu3.5 in Explanation tasks, indicating strong multimodal coherence. LLaDA2.0-Uni demonstrates robust interleaved generation capabilities, particularly in narrative and predictive reasoning contexts.

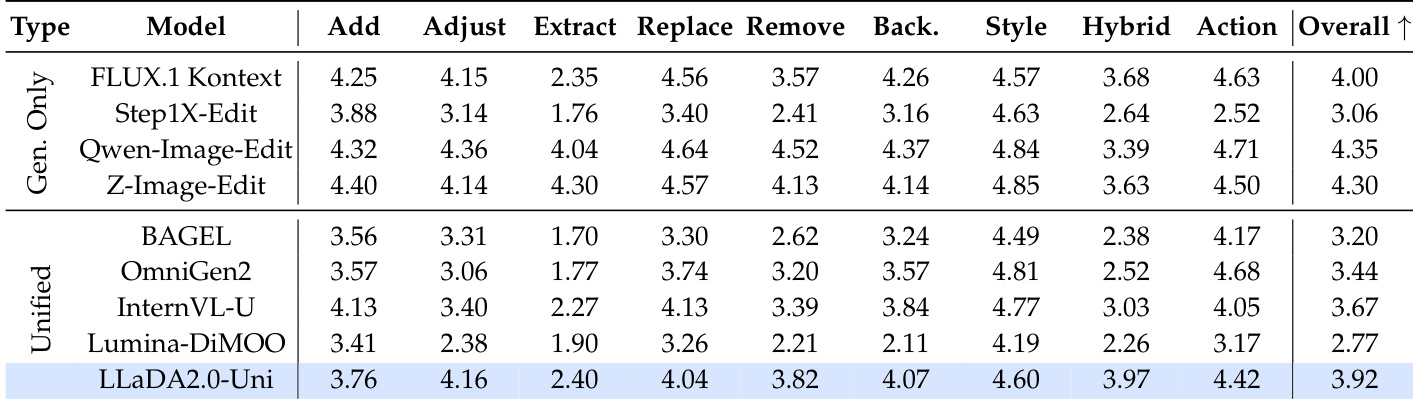
The authors evaluate LLaDA2.0-Uni on instruction-based image editing tasks, comparing it against specialized and unified models. Results show that LLaDA2.0-Uni achieves the highest overall score among unified models, outperforming baselines such as OmniGen2 and InternVL-U. It demonstrates particularly strong performance in Adjust and Hybrid editing tasks, indicating robust instruction comprehension and execution capabilities. LLaDA2.0-Uni achieves the highest overall score among unified models on the image editing benchmark. LLaDA2.0-Uni outperforms OmniGen2 and InternVL-U, ranking first in the unified category. LLaDA2.0-Uni excels in Adjust and Hybrid editing tasks, demonstrating strong capability in executing complex instructions.
LLaDA2.0-Uni is developed through a progressive three-stage training process that enhances vision-language alignment, multi-task pre-training, and supervised fine-tuning. Evaluations across various benchmarks demonstrate that the model excels in multi-region text rendering stability, interleaved multimodal generation, and complex instruction-based image editing. Furthermore, the implementation of a turbo decoder provides significant computational speedups while maintaining visual quality and performance comparable to the standard decoder.