Command Palette
Search for a command to run...
SWE-chat : Interactions entre agents de codage et utilisateurs réels dans la nature
SWE-chat : Interactions entre agents de codage et utilisateurs réels dans la nature
Joachim Baumann Vishakh Padmakumar Xiang Li John Yang Diyi Yang Sanmi Koyejo
Résumé
Les agents de codage alimentés par l’IA sont adoptés à grande échelle, pourtant nous disposons de peu de preuves empiriques sur la manière dont les utilisateurs s’en servent réellement et sur l’utilité concrète de leurs sorties. Nous présentons SWE-chat, le premier jeu de données à grande échelle de sessions réelles d’agents de codage, collectées auprès de développeurs open source en situation réelle. Le jeu de données comprend actuellement 6 000 sessions, soit plus de 63 000 prompts utilisateur et 355 000 appels d’outils par l’agent. SWE-chat est un jeu de données vivant : notre pipeline de collecte découvre et traite automatiquement et continuellement les sessions issues de dépôts publics. À l’aide de SWE-chat, nous offrons une caractérisation empirique initiale de l’usage des agents de codage dans le monde réel et de leurs modes d’échec. Nous constatons que les schémas de codage présentent une bimodalité : dans 41 % des sessions, l’agent génère quasi intégralement le code finalement validé (ce que l’on appelle le « vibe coding »), tandis que dans 23 % des cas, les humains écrivent l’intégralité du code eux-mêmes. Malgré des capacités en amélioration rapide, les agents de codage restent inefficaces dans des contextes naturels. Seulement 44 % du code produit par les agents survive jusqu’aux validations effectuées par les utilisateurs, et le code rédigé par les agents introduit davantage de vulnérabilités de sécurité que celui rédigé par des humains. Par ailleurs, les utilisateurs rejettent les sorties des agents — via des corrections, des rapports d’échec et des interruptions — dans 44 % de tous les tours d’interaction.
One-sentence Summary
SWE-chat is the first large-scale dataset of real coding agent sessions from open-source developers in the wild, comprising 6,000 sessions with more than 63,000 user prompts and 355,000 agent tool calls, that reveals bimodal coding patterns where 41% of sessions involve agents authoring virtually all committed code ("vibe coding") while 23% involve humans writing all code themselves, alongside findings that only 44% of agent-produced code survives into user commits and introduces more security vulnerabilities than human-authored code, while users push back against agent outputs in 44% of all turns.
Key Contributions
- The paper introduces SWE-chat, a large-scale dataset of 6,000 real-world coding agent sessions collected from open-source developers that includes over 63,000 user prompts and 355,000 agent tool calls. SWE-chat functions as a living dataset where a collection pipeline automatically and continually discovers and processes sessions from public repositories.
- This work provides an initial empirical characterization of real-world usage and failure modes. The analysis reveals that coding patterns are bimodal, with agents authoring virtually all code in 41% of sessions while humans write all code in 23%.
- Results show that coding agents remain inefficient in natural settings, as only 44% of agent-produced code survives into user commits and introduces more security vulnerabilities than code authored by humans. Furthermore, users push back against agent outputs through corrections, failure reports, and interruptions in 44% of all turns.
Introduction
AI coding agents are transforming software development by autonomously executing complex tasks through tool calls, yet their integration into real workflows remains poorly understood. Current benchmarks rely on curated problems with fixed solutions and fail to capture the iterative nature of human-agent collaboration or how developers steer and correct agent outputs. The authors address this by introducing SWE-chat, a dataset derived from real user interactions that documents how developers prompt, override, and evaluate coding agents in actual workflows.
Dataset

-
Dataset Composition and Sources
- The authors present SWE-chat, a continually growing dataset of real human-coding agent interactions collected from public GitHub repositories.
- Data is sourced from developers who opt into Entire.io's CLI checkpoint logging, which records session transcripts on dedicated branches linked to code commits.
- The collection spans 200+ repositories and includes interactions with five widely used coding agents such as Claude Code, OpenCode, Gemini CLI, Cursor, and Factory AI Droid.
-
Key Details and Subsets
- As of April 2026, the dataset contains 6,000 sessions comprising more than 63,000 user prompts and 355,000 agent tool calls.
- The full corpus includes 2.7 million logged events covering streamed progress events, tool return values, and a subset of 200 sessions with extended thinking traces.
- Data is filtered to include only repositories with licenses allowing redistribution and sessions where developers actively opted into public checkpoint logging.
-
Data Usage and Analysis
- The paper utilizes the data for empirical characterization of real-world coding agent usage and failure modes rather than for model training.
- Researchers analyze interaction behavior and failure responses to address research questions regarding user intent and agent efficiency.
- Metrics are computed to quantify code survival rates, token costs per committed line, and security vulnerabilities introduced by agent output.
-
Processing and Metadata Construction
- The authors apply privacy filters by removing personally identifiable information using Microsoft Presidio and stripping credentials with TruffleHog.
- Line-level code authorship attribution is constructed using temporary checkpoints on shadow branches to distinguish between human and agent-written lines.
- Session logs are enriched with annotations for prompt intent, user persona, and pushback using LLM judges validated against human expert gold labels.
- Topic clustering is performed on English prompts after stripping code blocks and reducing embedding dimensionality with UMAP to identify software engineering activities.
Method
The system employs a multi-stage framework for analyzing coding agent interactions, comprising session-level persona classification, prompt-level intent classification, and a structured evaluation procedure.
The Session Persona Classifier is designed to categorize user behavior patterns across an entire interaction. It processes a chronological timeline of a coding session, which encompasses user prompts, model responses, AI agent coding actions like file edits and tool calls, commits, and visible user reactions. As shown in the figure below, the timeline captures the turn-based exchange between the user and the agent.

Based on evidence such as constraint specificity, goal stability, and revision behavior, the model assigns the user to one of four categories: Expert Nitpickler, Vague Requester, Mind Changer, or Other.
Complementing this, the Prompt Intent Classifier operates at the granularity of individual prompts. Utilizing a model such as Qwen/Qwen3.5-27B with decoding parameters temperature=0.7 and top_p=0.8, this module assigns a primary intent label to each prompt. The labels include create new code, refactor, debug, understand, connect, git, test, or other, allowing for precise tracking of user objectives throughout the session.
Finally, the framework incorporates an Evaluation Procedure to assess session quality across five dimensions. These dimensions include goal completion, final session state, agent efficiency, code and commit quality, and user experience. The evaluation relies on concrete evidence from the transcript to judge whether requests were resolved, if the session ended naturally, and if the agent demonstrated steady progress without unnecessary retries.
Experiment
This research analyzes real-world coding agent sessions by classifying interactions into human-only, collaborative, and vibe coding modes to evaluate success rates, efficiency, and security implications. Results demonstrate that while most requests are fulfilled, fully autonomous vibe coding proves costlier and slower while introducing security vulnerabilities at a rate substantially higher than human-only development. Additionally, interaction patterns reveal a disconnect between rising agent autonomy and user oversight, as agents rarely seek clarification despite frequent human interruptions and corrections.
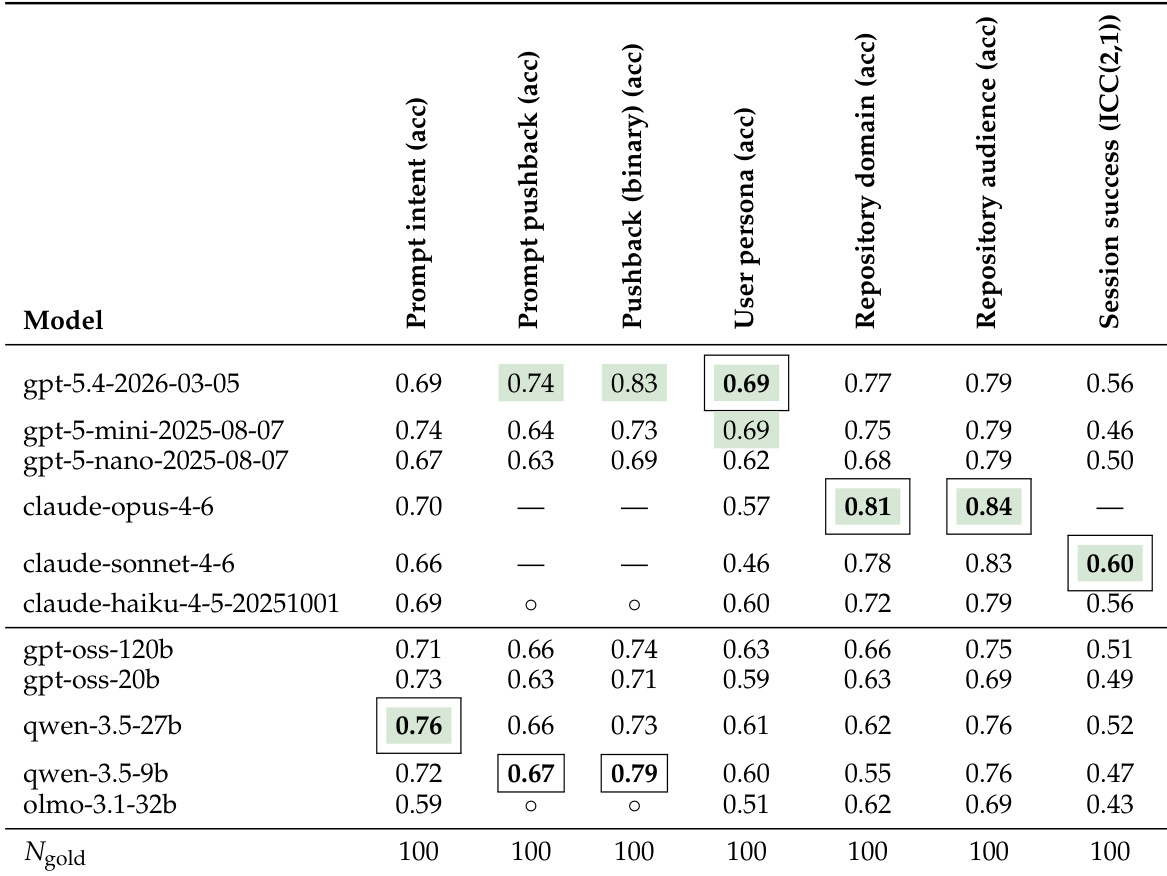
The authors evaluate multiple LLMs against a human gold standard dataset of 100 samples across seven annotation tasks. The results show that model performance is task-dependent, with specific models excelling in interaction analysis, repository classification, or session scoring. The gpt-5.4-2026-03-05 model achieved the highest accuracy for interaction metrics including prompt pushback and user persona. The claude-opus-4-6 model demonstrated superior performance in classifying repository domain and target audience. Task-specific leaders emerged, with qwen-3.5-27b performing best on prompt intent and claude-sonnet-4-6 achieving the highest session success correlation.
The authors validated the consistency of their annotation scheme for key interaction dimensions such as prompt intent, user pushback, and user personas. Two human annotators reviewed a sample of sessions to ensure the definitions for these categories were applied reliably. Classifying prompt pushback into binary categories resulted in the highest level of agreement between annotators. Identifying specific user personas proved the most difficult, yielding the lowest consistency scores. General categorization of prompt intent and pushback behaviors maintained strong alignment across the annotation team.

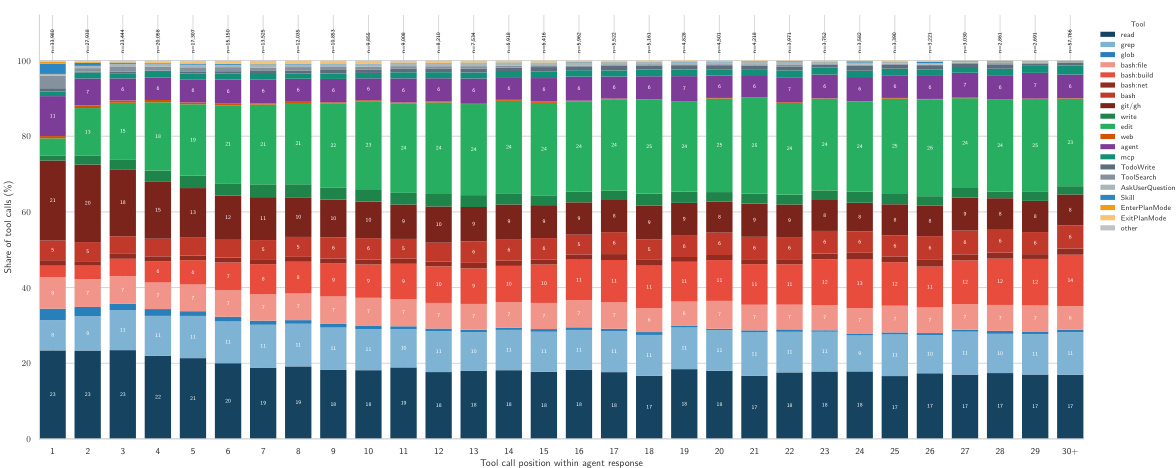
The chart visualizes the sequential distribution of tool usage throughout an agent's response trajectory. It highlights a distinct pattern where early interactions focus on information gathering while later interactions shift towards code modification and execution. Read operations dominate the earliest positions, indicating an initial phase of codebase exploration. The share of write and build tools increases significantly in later positions as the agent transitions to implementation. Research tools such as grep and git commands are most prominent at the beginning of the trajectory.
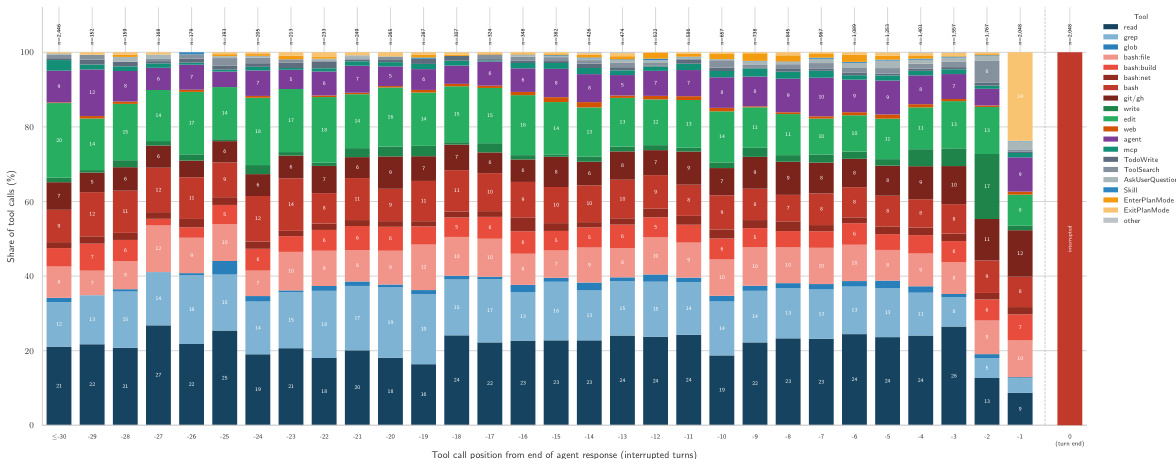
The chart illustrates the distribution of tool calls in agent trajectories that ended with hard user interruptions. It reveals a clear progression where agents start with research tools like read and grep to understand the codebase, then shift to action tools like edit and bash:build as the turn concludes. This trajectory pattern supports the finding that users often interrupt agents at the critical transition from planning to execution. Research tools dominate the initial positions of agent trajectories. Action tools become the primary activity as the turn approaches its end. Interruptions frequently occur during the transition from planning to execution.
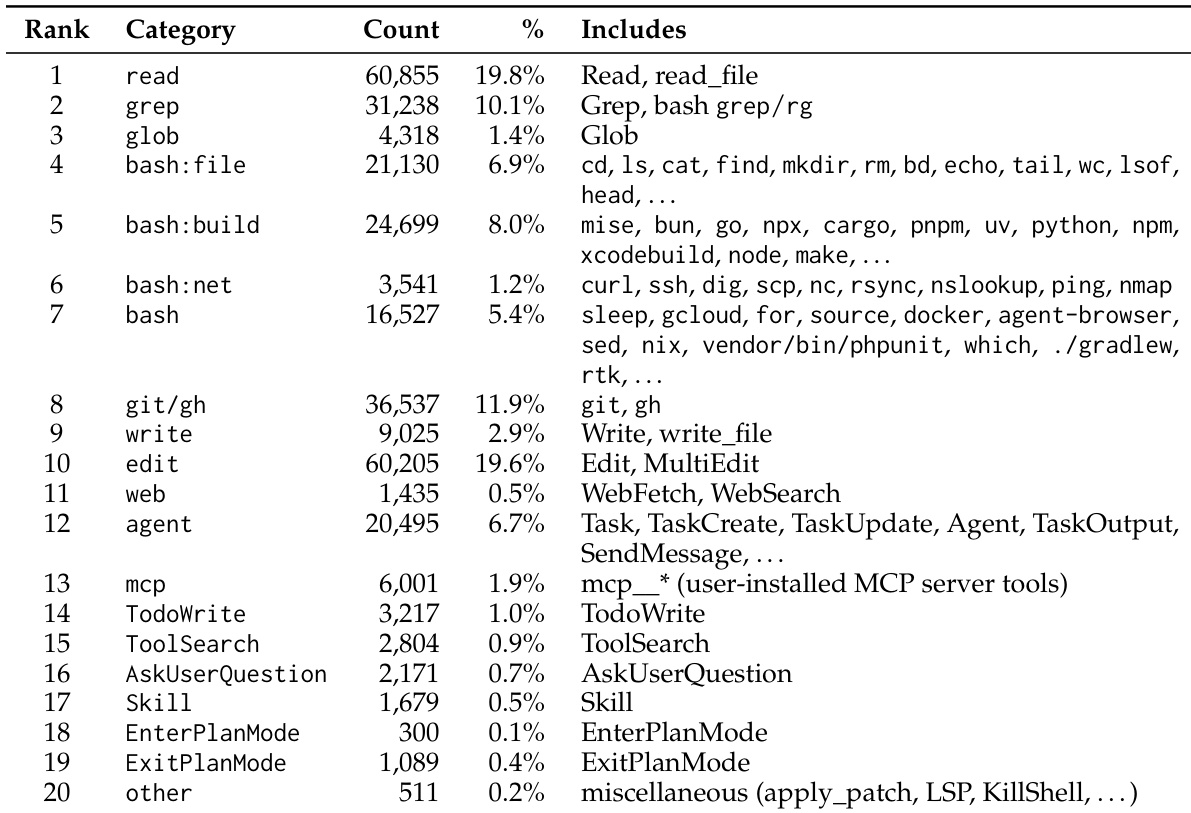
The the the table details the distribution of tool calls made by coding agents, showing that reading and editing files are the most common operations. Version control and text searching are also highly utilized, indicating a workflow focused on navigating and modifying codebases. Shell commands are further subdivided by function, with build operations occurring more frequently than file management or networking tasks. File reading and editing operations dominate the tool usage distribution, each comprising nearly one-fifth of the total volume. Version control and text searching commands are the next most common categories, highlighting the importance of code navigation and modification. Shell commands are segmented into specific functions, with build tasks appearing more often than file management or networking operations.
The study evaluates multiple large language models against a human gold standard across seven annotation tasks, revealing that performance is task-dependent with different models excelling in specific areas like interaction analysis or repository classification. Human annotator validation confirmed strong alignment for general categories such as prompt intent and pushback, while identifying specific user personas proved more challenging. Furthermore, analysis of agent trajectories indicates a clear progression from information gathering to code execution, with user interruptions frequently occurring during this critical transition phase.