Command Palette
Search for a command to run...
Exploration de l'intelligence spatiale d'un point de vue génératif
Exploration de l'intelligence spatiale d'un point de vue génératif
Résumé
L'intelligence spatiale est essentielle pour les grands modèles de langage multimodaux, pourtant, les benchmarks actuels l'évaluent largement sous un angle purement compréhensif. Nous nous demandons si les modèles multimodaux génératifs ou unifiés modernes possèdent également une intelligence spatiale générative (GSI — Generative Spatial Intelligence), c'est-à-dire la capacité de respecter et de manipuler des contraintes spatiales 3D lors de la génération d'images, et si une telle capacité peut être mesurée ou améliorée. Nous introduisons GSI-Bench, le premier benchmark conçu pour quantifier la GSI via l'édition d'images spatialement ancrée (spatially grounded image editing). Il se compose de deux éléments complémentaires : GSI-Real, un ensemble de données réelles de haute qualité construit via un pipeline de génération et de filtrage guidé par des prioris 3D, et GSI-Syn, un benchmark synthétique à grande échelle doté d'opérations spatiales contrôlables et d'un étiquetage entièrement automatisé. Accompagné d'un protocole d'évaluation unifié, GSI-Bench permet une évaluation évolutive et agnostique du modèle concernant la conformité spatiale et la fidélité de l'édition. Les expériences démontrent que l'ajustement fin (fine-tuning) de modèles multimodaux unifiés sur GSI-Syn produit des gains substantiels tant sur les tâches synthétiques que réelles et, de manière frappante, améliore également la compréhension spatiale en aval (downstream spatial understanding). Cela constitue la première preuve claire que l'entraînement génératif peut renforcer concrètement le raisonnement spatial, établissant ainsi une nouvelle voie pour faire progresser l'intelligence spatiale dans les modèles multimodaux.
One-sentence Summary
To quantify generative spatial intelligence through spatially grounded image editing, the authors introduce GSI-Bench, a benchmark comprising the real-world GSI-Real dataset and the synthetic GSI-Syn dataset that enables scalable assessment of spatial compliance and demonstrates that generative training significantly enhances both image manipulation fidelity and downstream spatial reasoning.
Key Contributions
- The paper introduces GSI-Bench, a novel benchmark designed to quantify Generative Spatial Intelligence (GSI) through spatially grounded image editing. This framework consists of GSI-Real, a high-quality real-world dataset created via a 3D-prior-guided pipeline, and GSI-Syn, a large-scale synthetic dataset featuring controllable spatial operations and automated labeling.
- The research establishes a unified evaluation protocol that enables scalable and model-agnostic assessment of spatial compliance and editing fidelity. This approach connects generative and understanding aspects of spatial reasoning by requiring models to manipulate spatial structures according to specific instructions.
- Experiments demonstrate that fine-tuning unified multimodal models on the GSI-Syn dataset significantly improves spatial compliance in both synthetic and real-world tasks. Results further show that this generative training process provides a transfer effect that enhances downstream spatial understanding capabilities.
Introduction
Spatial intelligence is a foundational requirement for multimodal large language models to interact with the physical world, governing tasks from robotic manipulation to 3D scene understanding. While existing research has focused heavily on spatial understanding through recognition and question answering, the ability of models to actively manipulate spatial constraints during image generation remains largely unexplored. The authors address this gap by introducing GSI-Bench, a novel benchmark designed to quantify Generative Spatial Intelligence (GSI) through spatially grounded image editing. This framework includes GSI-Real, a high-quality real-world dataset, and GSI-Syn, a large-scale synthetic dataset with controllable spatial operations. Through this work, the authors demonstrate that fine-tuning unified models on generative spatial tasks not only improves image editing fidelity but also enhances downstream spatial reasoning and understanding capabilities.
Dataset

The authors introduce two complementary benchmarks, GSI-Syn and GSI-Real, designed to evaluate generative spatial intelligence through synthetic and real-world data.
-
Dataset Composition and Sources
- GSI-Syn (Synthetic): Built using open-source simulators AI2-THOR and Mesa-Task to provide perfect ground-truth data, including 3D scene representations, geometric transformations, and rendered target images.
- GSI-Real (Real-world): Curated from ScanNet++, a large-scale indoor RGB-D dataset, to evaluate models on natural images where perfect 3D ground truth is unavailable.
-
Subset Details
- GSI-Syn-Room: Contains 593 samples covering six operation types, sourced from AI2-THOR.
- GSI-Syn-Tabletop: Contains 600 samples covering three operation types, sourced from Mesa-Task.
- GSI-Syn-Bathroom: A specialized subset of 200 samples featuring randomized viewpoints to test cross-view generalization.
- GSI-Real: Contains 441 samples from 211 diverse indoor scenes, spanning three operation types.
- GSI-Syn-Train: A large-scale fine-tuning set totaling 10,500 samples, consisting of 1,500 samples per operation type per environment.
-
Data Processing and Quality Control
- Synthetic Pipeline: The authors use DBSCAN clustering on floor plans for viewpoint curation and prioritize actionable views with manipulable objects. Actions are validated through 3D geometric checks and physics-enabled simulation. A two-stage filter is applied: first, removing samples with negligible pixel changes, and second, using an MLLM (Qwen3-VL-235B) to discard simulation artifacts or physically implausible outcomes.
- Real-world Pipeline: Images are sampled every 20 frames from ScanNet++ and filtered for sharpness and object density. The authors use DetAny3D to reconstruct 3D scene structures and bounding boxes. To ensure quality, they employ a visualization-based verification where an MLLM identifies collisions or occlusions, corrects annotation errors, and rewrites template captions into natural language. A final manual human review is conducted to refine all instructions.
-
Usage and Evaluation
- Training: The GSI-Syn-Train subset is used for model fine-tuning, with strict scene separation maintained between training and test sets to prevent data leakage.
- Evaluation: GSI-Syn provides unambiguous automated validation via ground-truth triplets. For GSI-Real, the authors use an alternative protocol that evaluates success by analyzing the spatial consistency between the model's predicted edit and the specified 3D transformation.
Method
The authors leverage a unified framework for grounded spatial image editing (GSI), which operates through a structured pipeline that integrates 3D scene understanding, spatial reasoning, and multimodal generation. The core methodology begins with a 3D scene representation, where each scene S is modeled as a collection of objects Oi=(ci,si,Ri) and a camera C=(Rc,tc,K), enabling precise geometric transformations. This representation underpins a taxonomy of seven quantitative spatial operations, including object rotation, movement, scaling, removal, and perspective control, as illustrated in the figure below. These operations are grounded in explicit 3D transformations, allowing for physically consistent and controllable image editing.
Refer to the framework diagram to understand the overall architecture of GSI-Bench, which consists of three main components: GSI-Real, GSI-Syn, and GSI-Bench. GSI-Real provides real-world data from 211 scenes, including camera-relative movement, object rotation, and spatial removal. GSI-Syn generates synthetic data, with subsets for bathroom (200 samples), tabletop (600 samples), and room (593 samples) environments, along with a training set of 10,500 samples. The GSI-Bench integrates these data sources to evaluate model performance across various spatial tasks. The framework supports multiple training and evaluation modules, including GSI-Syn-Train, GSI-Syn-Tabletop, and GSI-Syn-Room, each tailored to specific spatial manipulation scenarios.
The GSI-Syn pipeline, as shown in the figure below, is designed to automate the synthesis of high-quality training data. It begins with scene initialization and viewpoint curation, where maximally dispersed viewpoints are sampled to ensure diverse coverage. A 3D geometric checks module then verifies constraints such as non-occlusion, stability, and collision avoidance before generating an instruction. The action is executed in a simulator, and the resulting state is validated against the ideal state. If the actual state matches the expected outcome, the output is retained; otherwise, the process is rolled back. Post-generation filtering ensures quality by applying instance segmentation and multimodal language models to discard anomalies such as severe occlusion or object clipping.
In the second stage, the pipeline transitions to 3D scene reconstruction and operation generation. Candidate frames are selected based on frequency-domain analysis to ensure clarity and minimize motion blur. DetAny3D reconstructs the 3D scene, extracting object bounding boxes, poses, and semantic labels. Spatial operations are then generated, and the results are validated through a before-and-after comparison. The final step involves human review and refinement, where annotators correct ambiguous instructions and identify residual errors. This iterative process ensures that the generated data is accurate and semantically consistent.
The fine-tuning of unified multimodal large language models (MLLMs) for GSI is conducted using BAGEL as the base model, which supports image editing through self-attention mechanisms that enable deep interaction between perception and generation modules. The training set is constructed from GSI-Syn, incorporating diverse operations such as move, rotate, resize, remove, scaling, and view change. This approach allows the model to learn spatial relationships directly from generative data, enhancing its ability to understand and execute complex spatial instructions. The evaluation protocol assesses performance across instruction compliance, spatial accuracy, edit locality, and appearance consistency, providing a comprehensive benchmark for spatial intelligence.
Experiment
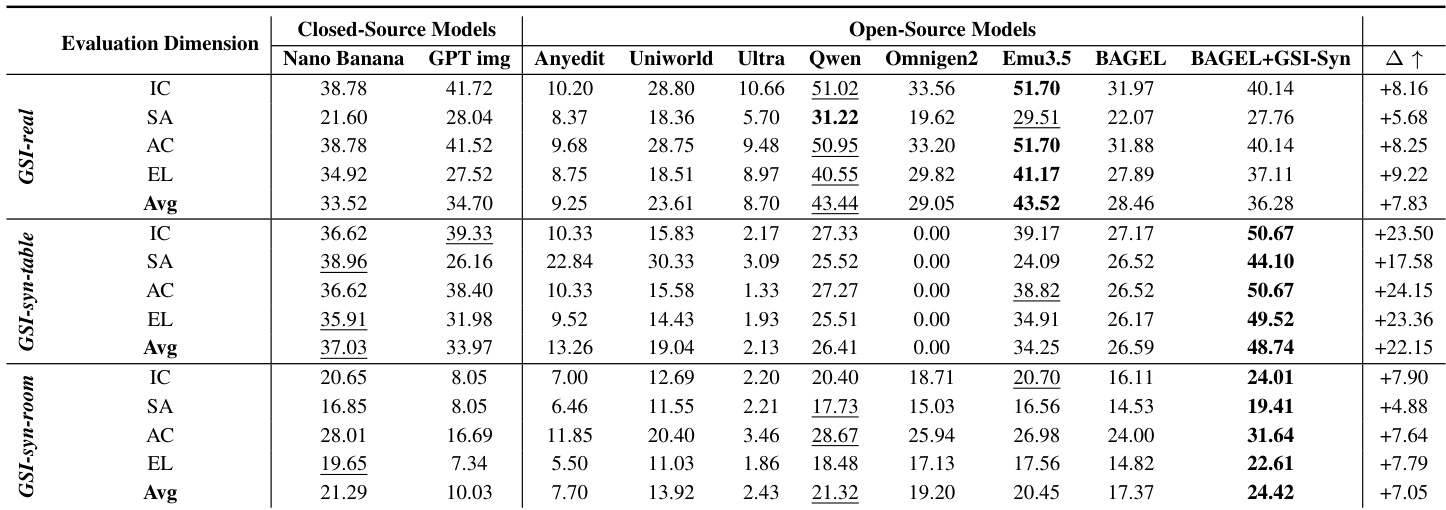
The evaluation protocol assesses generative spatial intelligence through instruction compliance, spatial accuracy, edit locality, and appearance consistency across synthetic and real-world datasets. Benchmarking reveals that while closed-source models excel in general visual generation, they often struggle with the precise geometric manipulations required for fine-grained spatial reasoning compared to specialized open-source models like Emu3.5. Furthermore, fine-tuning on geometrically grounded synthetic data demonstrates effective sim-to-real transfer, significantly enhancing both spatial editing capabilities and fundamental spatial understanding without requiring real-world annotations.
The authors evaluate generative spatial intelligence across multiple models and datasets, focusing on instruction compliance, spatial accuracy, appearance consistency, and edit locality. The results show that open-source models, particularly Emu3.5 and fine-tuned BAGEL, achieve strong performance on real-world and synthetic benchmarks, with notable improvements in localized editing and spatial fidelity after fine-tuning on synthetic data. Closed-source models perform well on instruction compliance and appearance consistency but struggle with fine-grained spatial accuracy. Emu3.5 consistently leads among open-source models, while fine-tuning significantly enhances spatial reasoning capabilities, especially in edit locality and spatial accuracy. Open-source models like Emu3.5 and fine-tuned BAGEL show strong performance on spatial reasoning tasks, particularly in edit locality and spatial accuracy. Fine-tuning on synthetic data improves spatial understanding and transfer to real-world scenarios, with significant gains in edit locality and appearance consistency. Closed-source models excel in instruction compliance and appearance consistency but lag in spatial accuracy, indicating limitations in geometric reasoning.
The authors evaluate generative spatial intelligence using a multi-faceted protocol with metrics for instruction compliance, spatial accuracy, edit locality, and appearance consistency. Results show that fine-tuning on synthetic data improves spatial understanding and transfer to real-world tasks, with notable gains in edit locality and appearance consistency, while also enhancing performance on benchmarks measuring spatial interaction and perspective taking. Fine-tuning on synthetic data significantly improves edit locality and appearance consistency in real-world scenarios. Models trained on spatially grounded generative data show enhanced spatial understanding on benchmarks measuring interaction and perspective. Performance gains are most pronounced in localized edits and object identity preservation, with consistent improvements across multiple metrics.
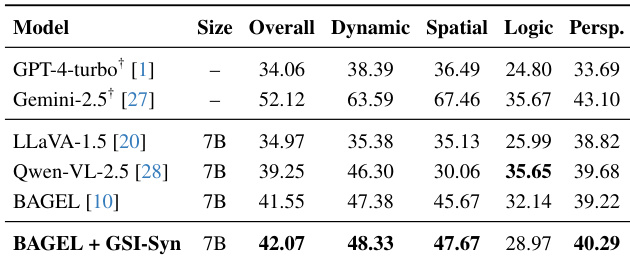
The authors evaluate generative spatial intelligence using a multi-faceted protocol that includes instruction compliance, spatial accuracy, edit locality, and appearance consistency. The results show that fine-tuning on synthetic data improves spatial reasoning and editing performance, particularly in localized edits and object preservation, with the best-performing model demonstrating significant gains across multiple dimensions. Fine-tuning on synthetic data improves spatial reasoning and editing performance across multiple dimensions. The best-performing model achieves higher scores in instruction compliance and spatial accuracy compared to baseline models. The results demonstrate robust transfer of spatial understanding from synthetic to real-world scenarios without requiring real-world annotations.
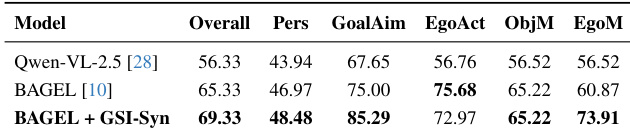
The authors evaluate generative spatial intelligence across various models and datasets to assess instruction compliance, spatial accuracy, appearance consistency, and edit locality. The experiments demonstrate that while closed-source models excel in instruction following, fine-tuning open-source models on synthetic data significantly enhances their spatial reasoning and localized editing capabilities. Ultimately, the results show that synthetic training enables robust transfer of spatial understanding to real-world scenarios, improving object preservation and geometric accuracy without the need for real-world annotations.