Command Palette
Search for a command to run...
TEMPO : Mise à l'échelle de l'entraînement au moment du test (Test-time Training) pour les grands modèles de raisonnement
TEMPO : Mise à l'échelle de l'entraînement au moment du test (Test-time Training) pour les grands modèles de raisonnement
Qingyang Zhang Xinke Kong Haitao Wu Qinghua Hu Minghao Wu Baosong Yang Yu Cheng Yun Luo Ganqu Cui Changqing Zhang
Résumé
Voici la traduction de votre texte en français, respectant les standards de la communication scientifique :L'entraînement au moment du test (Test-time training, TTT) adapte les paramètres du modèle sur des instances de test non étiquetées pendant la phase d'inférence, ce qui permet d'étendre continuellement les capacités du modèle au-delà de ce qui est possible lors de l'entraînement hors ligne (offline training). Malgré des gains initiaux, les méthodes TTT existantes pour les modèles de raisonnement à grande échelle (LRM) stagnent rapidement et ne bénéficient pas d'un calcul supplémentaire au moment du test (test-time compute). En l'absence de calibration externe, le signal de récompense auto-généré dérive progressivement à mesure que le modèle de politique (policy model) évolue, entraînant à la fois un plateau de performance et un effondrement de la diversité (diversity collapse).Nous proposons TEMPO, un cadre TTT qui entrelace l'affinement de la politique sur des questions non étiquetées avec une recalibration périodique du critique (critic) sur un ensemble de données étiquetées. En formalisant cette procédure alternée via l'algorithme Expectation-Maximization (EM), nous démontrons que les méthodes précédentes peuvent être interprétées comme des variantes incomplètes omettant l'étape cruciale de la recalibration. La réintroduction de cette étape resserre la borne inférieure de l'espérance (ELBO, evidence lower bound) et permet une amélioration continue. Sur diverses familles de modèles (Qwen3 et OLMO3) et diverses tâches de raisonnement, TEMPO améliore les performances d'OLMO3-7B sur AIME 2024, passant de 33,0 % à 51,1 %, et celles de Qwen3-14B, passant de 42,3 % à 65,8 %, tout en maintenant une diversité élevée.
One-sentence Summary
By formalizing an alternating procedure of policy refinement and periodic critic recalibration through the Expectation-Maximization algorithm, the TEMPO framework prevents reward drift and diversity collapse to scale test-time training for large reasoning models, improving OLMO3-7B on AIME 2024 from 33.0% to 51.1% and Qwen3-14B from 42.3% to 65.8%.
Key Contributions
- The paper introduces TEMPO, a test-time training framework that utilizes an alternating actor-critic optimization to prevent reward drift and diversity collapse in large reasoning models.
- This work formalizes the test-time training process through the Expectation-Maximization (EM) algorithm, identifying that prior methods fail because they omit the crucial E-step of periodic critic recalibration on labeled data.
- Experimental results demonstrate that TEMPO enables sustained performance improvements across diverse model families, such as increasing OLMO3-7B accuracy from 33.0% to 51.1% on the AIME 2024 benchmark while maintaining high output diversity.
Introduction
Large reasoning models (LRMs) often rely on static parameters that cannot incorporate new knowledge acquired during inference. Test-time training (TTT) attempts to solve this by adapting model parameters on unlabeled test data to extend reasoning capabilities. However, existing TTT methods rely on heuristic, self-generated reward signals that cause performance to plateau and output diversity to collapse as the model's internal rewards drift from true correctness. The authors leverage an Expectation-Maximization (EM) framework to propose TEMPO, a TTT method that interleaves policy refinement on unlabeled questions with periodic critic recalibration on a labeled dataset. By reintroducing this crucial recalibration step, TEMPO provides a stable training signal that enables sustained performance gains and maintains high output diversity across various reasoning tasks.
Method
The authors propose Test-time Expectation-Maximization Policy Optimization (TEMP0), a framework that enables large reasoning models (LRMs) to continuously self-improve during the test phase by alternating between two core modules: critic calibration and policy refinement, inspired by the Expectation-Maximization (EM) algorithm. The overall architecture operates in an iterative loop where the model leverages both labeled and unlabeled data to refine its behavior.
The process begins with the initialization of both the policy and critic models using a reinforcement learning with verification and reward (RLVR) procedure on the labeled dataset DL. The framework then proceeds to iteratively alternate between two distinct steps. In the E-step, referred to as critic calibration, the critic model is updated to ensure its reward predictions remain grounded in external supervision. This is achieved by training the critic model Vϕ(x,yt) on the labeled data DL, where it learns to predict the correctness of generated responses at the token level. The critic is optimized by minimizing the mean squared error (MSE) between its predictions and the ground-truth binary correctness indicators, ensuring it provides a reliable and calibrated measure of response quality. The resulting critic serves as a surrogate for the posterior distribution over correct responses, enabling the model to reweight its own generations.
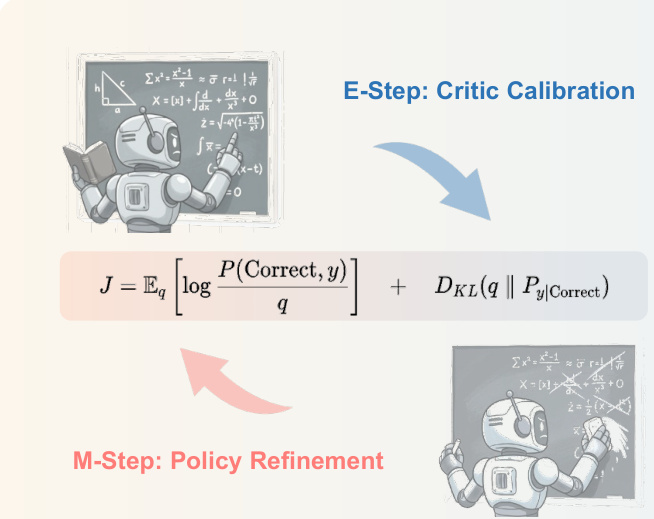
In the M-step, or policy refinement, the model uses the calibrated critic to guide its own self-improvement on unlabeled test data. The policy parameters θ are updated by maximizing a weighted maximum likelihood objective, where the weights are derived from the critic's predictions on the final token of the response, Vϕ(x,yT). This objective is implemented via a policy gradient framework, where the critic's final value serves as the ground-truth reward R for the entire response trajectory. To stabilize training, the critic's intermediate value predictions at each token y1:t are used as a baseline bt, and the advantage At for each token is computed as the difference between the final reward and the baseline, At=R−Vϕ(x,y1:t). This advantage signal is then used to update the policy, reinforcing actions that contribute to high-quality outputs.
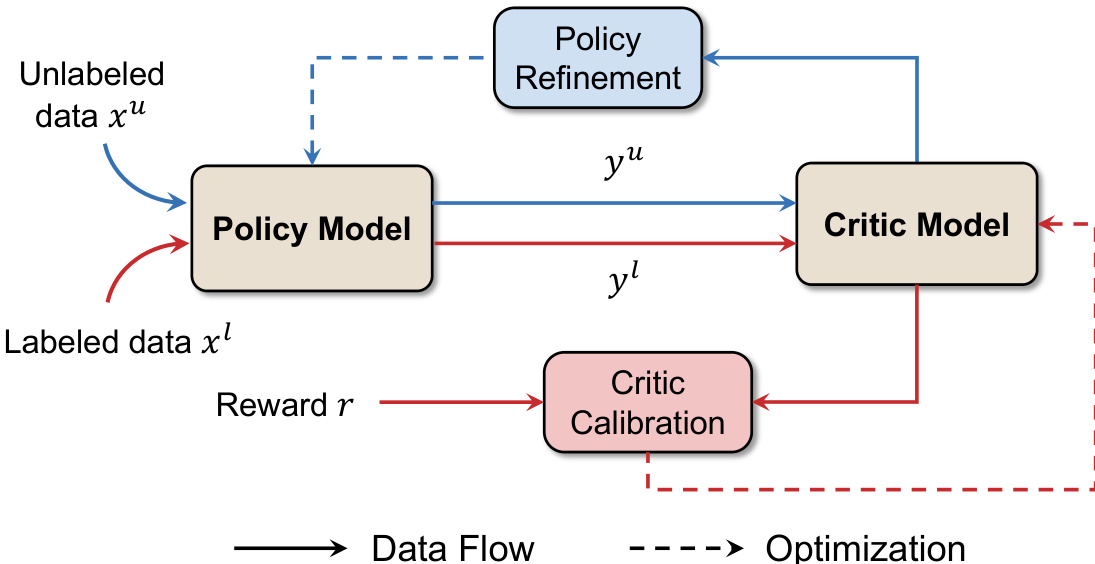
The data flow of the system is structured to support this alternating process. Unlabeled data xu is fed into the policy model to generate responses yu, which are then evaluated by the critic model. Labeled data xl is used to provide rewards r that directly inform the critic calibration process. The optimization flow, indicated by dashed lines, shows that the critic is periodically updated based on the labeled data, and the policy is refined based on the critic's evaluations of its own outputs. This continuous loop of calibration and refinement allows the model to achieve sustained self-improvement on open reasoning problems.
Experiment
TEMPO is evaluated across mathematical and general domain reasoning tasks using various base models and benchmarks to validate its effectiveness. The experiments demonstrate that TEMPO achieves sustained scalability beyond standard reinforcement learning ceilings and maintains high output diversity without the reasoning collapse seen in baseline methods. Furthermore, the results confirm the framework's versatility across different reasoning domains and validate that its alternating training design is essential for preventing critic misalignment during self-improvement.
The authors evaluate TEMPO across multiple models and benchmarks, demonstrating that it consistently outperforms baselines in both mathematical and general reasoning tasks. Results show that TEMPO achieves significant improvements over zero-RL baselines, maintains high output diversity, and sustains performance gains through test-time training without plateauing. The method's effectiveness is attributed to its alternating training design, which prevents reward signal drift and enables continuous self-improvement. TEMPO consistently outperforms baselines across model scales and benchmarks, achieving substantial gains in accuracy and pass@k metrics. TEMPO preserves output diversity during test-time training, avoiding the collapse seen in other methods that converge to narrow reasoning patterns. The alternating training design in TEMPO is essential for sustained improvement, as a frozen critic leads to performance stagnation over time.
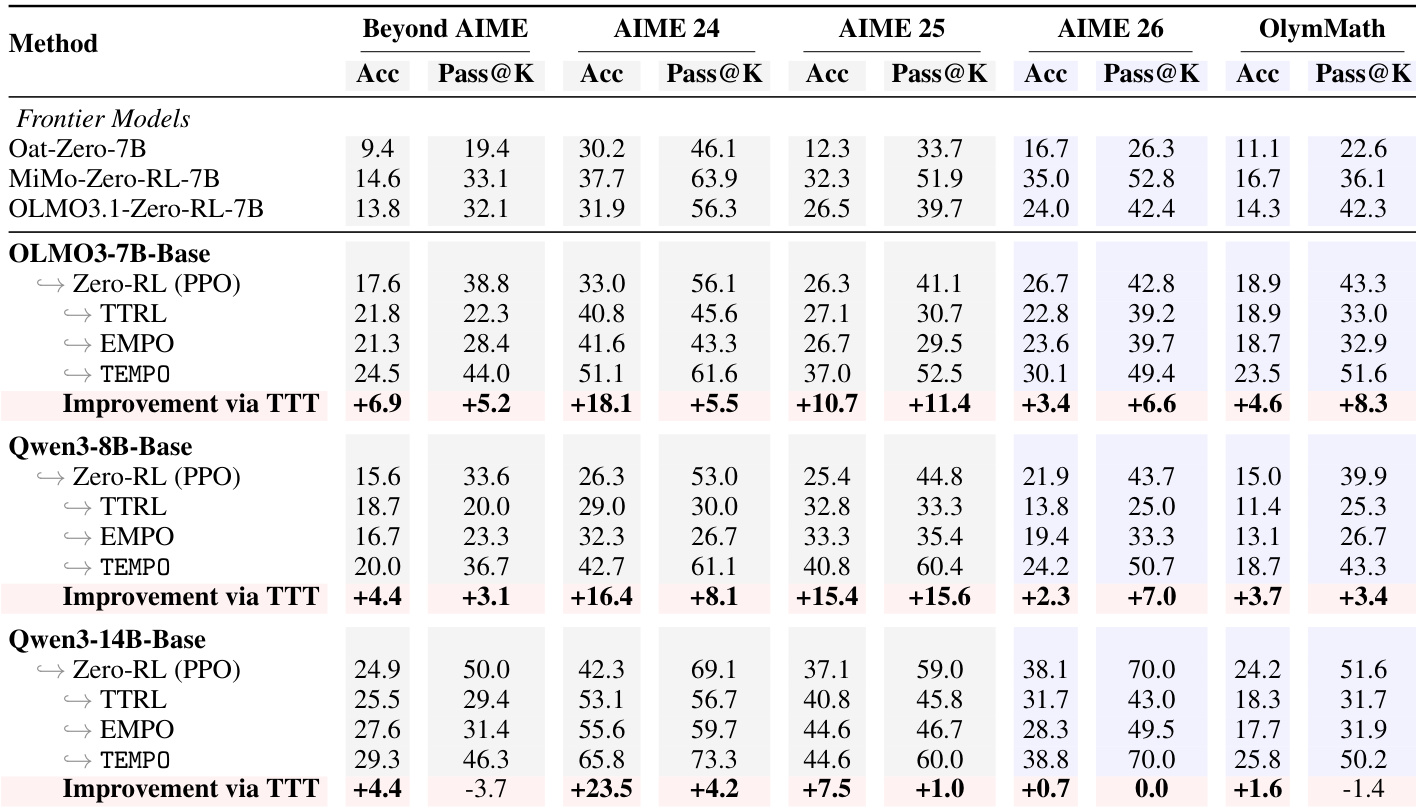
The authors evaluate TEMPO on general reasoning tasks beyond mathematical reasoning, comparing it against baselines such as PPO, TTRL, and EMPO. Results show that TEMPO achieves significant improvements across multiple benchmarks and models, particularly on complex domains like GPQA-Diamond, while maintaining high diversity in outputs. The method demonstrates robust performance gains even when starting from a converged model, indicating its effectiveness in leveraging test-time data for sustained capability improvement. TEMPO achieves substantial improvements across diverse reasoning tasks, including BigBenchHard, AGI Eval, ZebraLogic, and GPQA-Diamond, outperforming baselines like TTRL and EMPO. The method maintains high output diversity, avoiding the collapse seen in other self-training approaches, which leads to consistent gains in pass@k metrics. TEMPO continues to improve beyond convergence points, demonstrating that test-time training on novel data enables performance gains beyond the limits of standard RLVR.
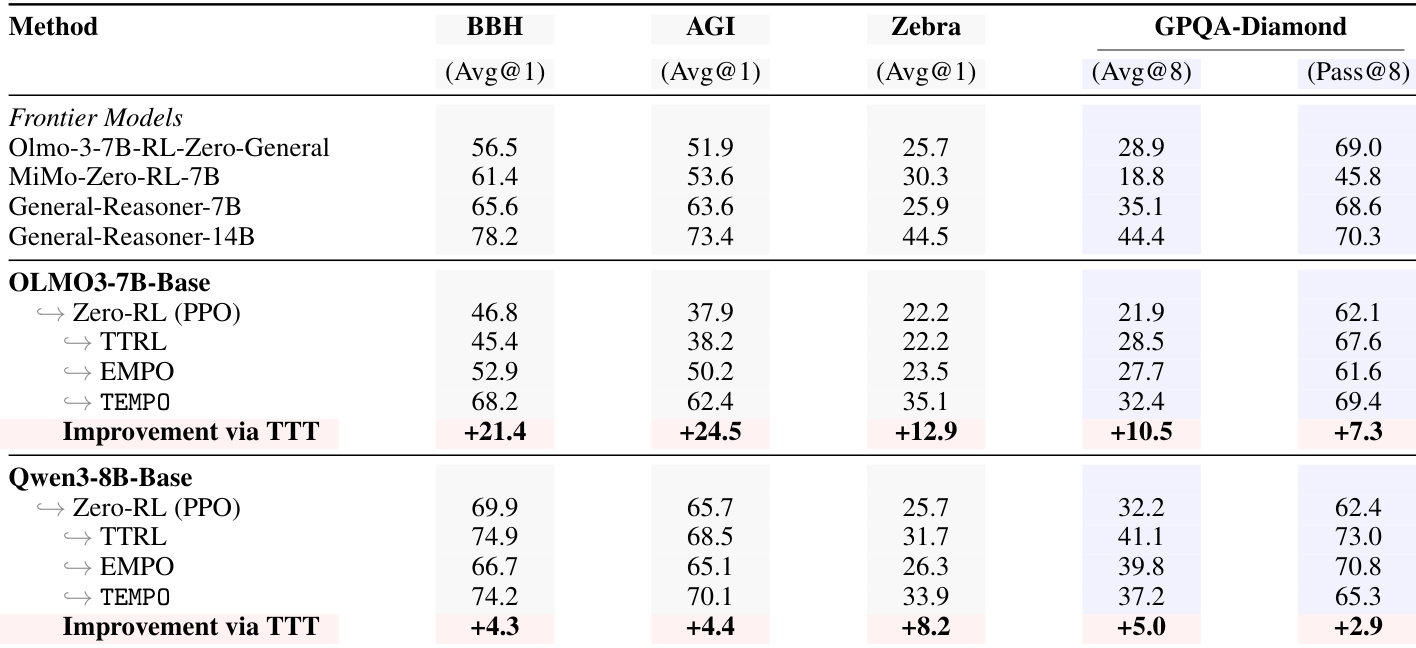
TEMPO is evaluated across various model scales and reasoning benchmarks, including mathematical and general reasoning tasks, to compare its performance against standard reinforcement learning and test-time training baselines. The experiments demonstrate that TEMPO consistently improves reasoning capabilities and maintains high output diversity without the performance collapse or stagnation seen in other methods. These results suggest that the alternating training design effectively prevents reward signal drift and enables sustained self-improvement through test-time training.