Command Palette
Search for a command to run...
LLaTiSA : Vers un raisonnement sur séries temporelles stratifié par difficulté, de la perception visuelle à la sémantique
LLaTiSA : Vers un raisonnement sur séries temporelles stratifié par difficulté, de la perception visuelle à la sémantique
Yueyang Ding HaoPeng Zhang Rui Dai Yi Wang Tianyu Zong Kaikui Liu Xiangxiang Chu
Résumé
La compréhension globale des séries temporelles demeure un défi majeur pour les grands modèles de langage (LLMs). La recherche actuelle est entravée par des définitions de tâches fragmentées et des bancs d'essai (benchmarks) présentant des ambiguïtés intrinsèques, ce qui empêche une évaluation rigoureuse et le développement de modèles de raisonnement sur séries temporelles (TSRMs) unifiés. Pour combler cette lacune, nous formalisons le raisonnement sur séries temporelles (TSR) via une taxonomie à quatre niveaux de complexité cognitive croissante. Nous introduisons HiTSR, un ensemble de données hiérarchique pour le raisonnement sur séries temporelles comprenant 83 000 échantillons avec des combinaisons de tâches diversifiées et des trajectoires de chaîne de pensée (Chain-of-Thought, CoT) vérifiées. En exploitant HiTSR, nous proposons LLaTiSA, un TSRM performant qui intègre des motifs visualisés à des tableaux numériques calibrés avec précision afin d'améliorer la perception temporelle des modèles vision-langage (VLMs). Grâce à une stratégie d'apprentissage par transfert progressif (curriculum fine-tuning) en plusieurs étapes, LLaTiSA atteint des performances supérieures et démontre une robustesse de généralisation hors distribution (out-of-distribution) à travers diverses tâches de TSR et des scénarios réels. Notre code est disponible à l'adresse suivante : https://github.com/RainingNovember/LLaTiSA.
One-sentence Summary
The authors propose LLaTiSA, a Time Series Reasoning Model that enhances the temporal perception of Vision-Language Models by integrating visualized patterns with precision-calibrated numerical tables, achieving superior performance and robust out-of-distribution generalization across diverse tasks through a multi-stage curriculum fine-tuning strategy leveraging the hierarchical 83k-sample HiTSR dataset.
Key Contributions
- The paper establishes a formal framework for Time Series Reasoning (TSR) through a four-level taxonomy that categorizes tasks by increasing cognitive complexity.
- A hierarchical dataset named HiTSR is introduced, consisting of 83,000 samples that feature diverse task combinations and verified Chain-of-Thought trajectories.
- The study presents LLaTiSA, a Time Series Reasoning Model that utilizes visualized patterns and precision-calibrated numerical tables to enhance temporal perception, achieving superior performance and robust out-of-distribution generalization through a multi-stage curriculum fine-tuning strategy.
Introduction
Time series reasoning is essential for interpreting temporal dynamics in critical fields such as medical diagnostics, finance, and industrial monitoring. While Large Language Models (LLMs) and Vision-Language Models (VLMs) show promise, current research suffers from fragmented task definitions and unreliable benchmarks that often lack numerical precision or suffer from semantic ambiguity. Many existing models struggle with foundational tasks, such as basic numerical grounding, which undermines their ability to perform complex high-level reasoning.
The authors address these gaps by formalizing a four-level cognitive taxonomy for time series reasoning and introducing HiTSR, a hierarchical dataset containing 83k samples with verified reasoning chains. They leverage this framework to develop LLaTiSA, a VLM-based reasoning model that integrates visual plots with structured numerical tables to bridge the gap between qualitative perception and quantitative precision. To ensure robust capability building, the authors employ a multi-stage curriculum fine-tuning strategy that progressively trains the model from basic numerical read-out to complex semantic interpretation.
Dataset
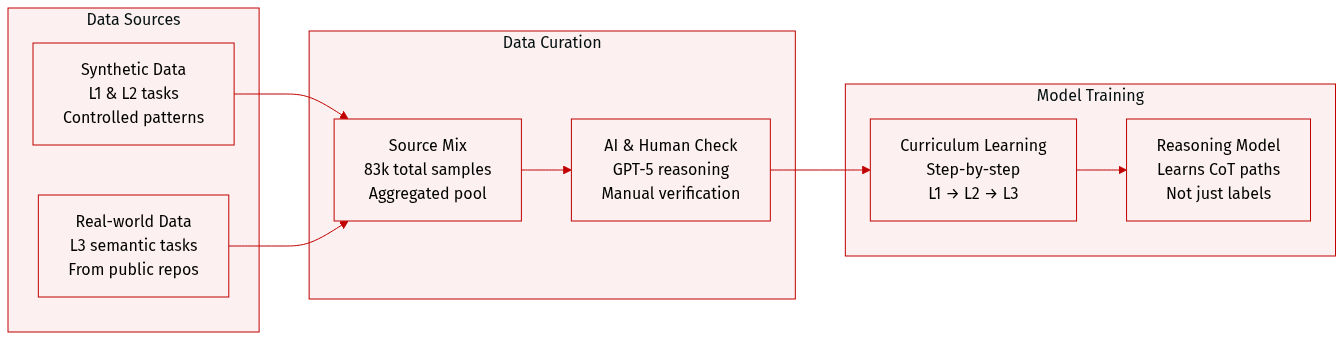
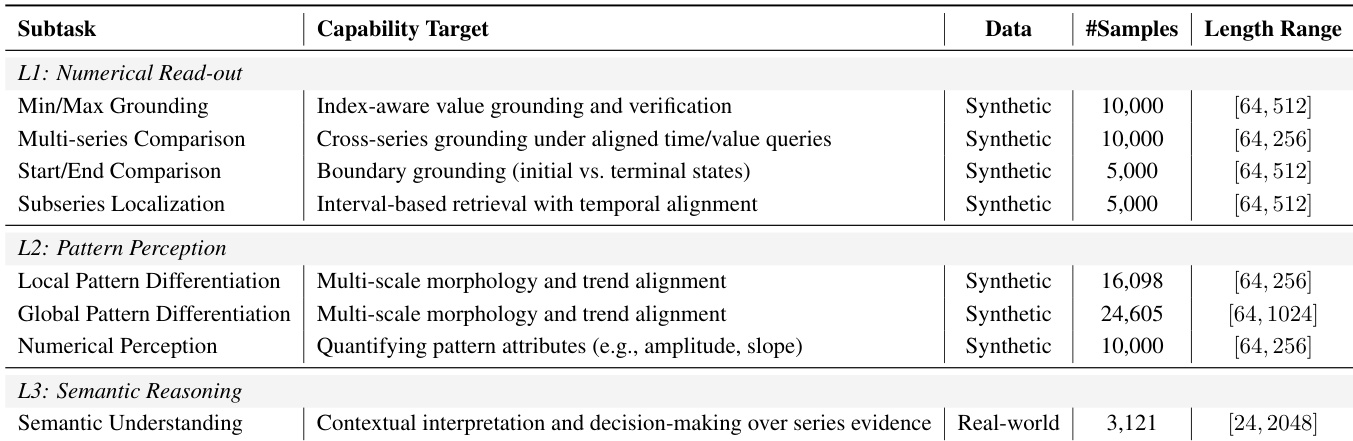
The authors introduce HiTSR, a unified dataset designed for training and evaluating Time Series Reasoning (TSR) capabilities across three hierarchical levels (L1 to L3). The dataset consists of approximately 83,000 samples and is structured as follows:
-
Dataset Composition and Subsets
- HiTSR-L1 (30,000 samples): Focuses on fundamental numerical read-out and localization tasks. These are generated using synthetic time series to provide large-scale supervision in a controlled manner.
- HiTSR-L2 (50,703 samples): Targets pattern perception, including local and global pattern differentiation. These samples are also derived from synthetic time series to allow for systematic manipulation of temporal structures.
- HiTSR-L3 (3,121 samples): Focuses on high-level semantic understanding. This subset is curated from real-world time series sourced from diverse repositories, including UTSD, Monash, and Time-MMD.
-
Data Processing and Annotation
- Synthesis and Augmentation: For L3 tasks, the authors apply random cropping to real-world time series to create sub-series, which increases data volume and descriptive diversity.
- Question Construction: L1 tasks use rule-based short-answer formats. L2 and L3 tasks are structured as multiple-choice questions (MCQs) where the targets are crafted as complete natural-language statements to improve instruction-following.
- CoT Generation: The authors implement a "Perception-to-Reasoning" pipeline. For L2 and L3, GPT-5 is used to generate numerically aware descriptions and Chain-of-Thought (CoT) trajectories. Distractors are engineered by sampling from other series or through rule-based perturbations to ensure they are logically distinct.
- Multi-Stage Verification: To ensure high fidelity, the authors employ a rigorous verification pipeline. L1 uses deterministic scripts, L2 uses a combination of GPT-5 cross-validation and human auditing (10% of the pool), and L3 undergoes 100% manual human verification to ensure semantic and numerical integrity.
-
Model Training and Usage
- Curriculum Learning: The authors use the stratified levels of HiTSR to implement a three-stage curriculum fine-tuning strategy, progressing from L1 to L3.
- Reasoning Enhancement: Unlike traditional benchmarks that only provide labels, HiTSR provides verified CoT trajectories, allowing the model to learn the reasoning process rather than simple pattern mapping.
Method
The authors leverage a four-level taxonomy to structure the Time Series Reasoning (TSR) task, grounded in established cognitive and visual perception frameworks. The framework decomposes TSR into distinct cognitive stages: L1 (Numerical Read-out), L2 (Pattern Perception), L3 (Semantic Reasoning), and L4 (Predictive Inference). Each level corresponds to increasing complexity in reasoning, with L1 focusing on basic value retrieval, L2 on identifying trends and patterns, L3 on contextualizing patterns within domain knowledge, and L4 on predicting future states. This hierarchy is informed by Bloom's Taxonomy, mapping lower-order thinking skills to L1–L2 and higher-order skills to L3–L4, and by Bertin’s Levels of Reading, which supports the progression from elementary data element analysis to extrapolative inference. The framework provides a diagnostic tool to pinpoint whether model failures arise from perceptual limitations or reasoning deficits.
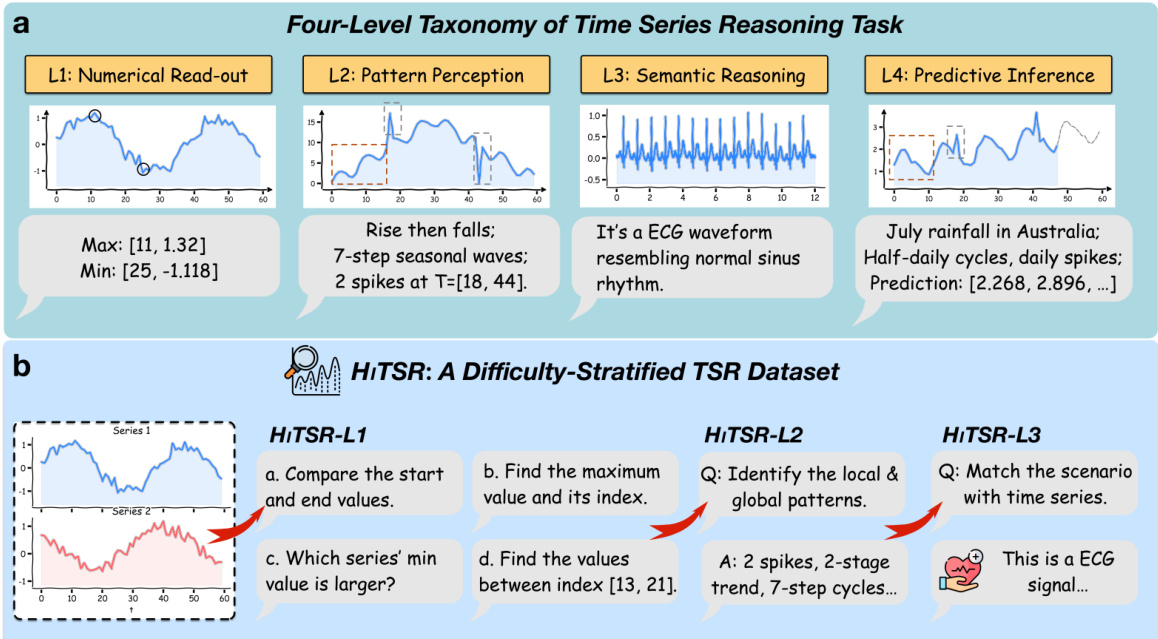
As shown in the figure below, the HiTSR dataset is constructed to evaluate models across these levels. The dataset includes tasks such as HiTSR-L1, which requires comparing start and end values or identifying minima, and HiTSR-L2, which involves recognizing local and global patterns. For HiTSR-L3, the task shifts to matching scenarios with time series data, such as identifying an ECG signal. The progression reflects the increasing cognitive demand, with each level building on the previous one.
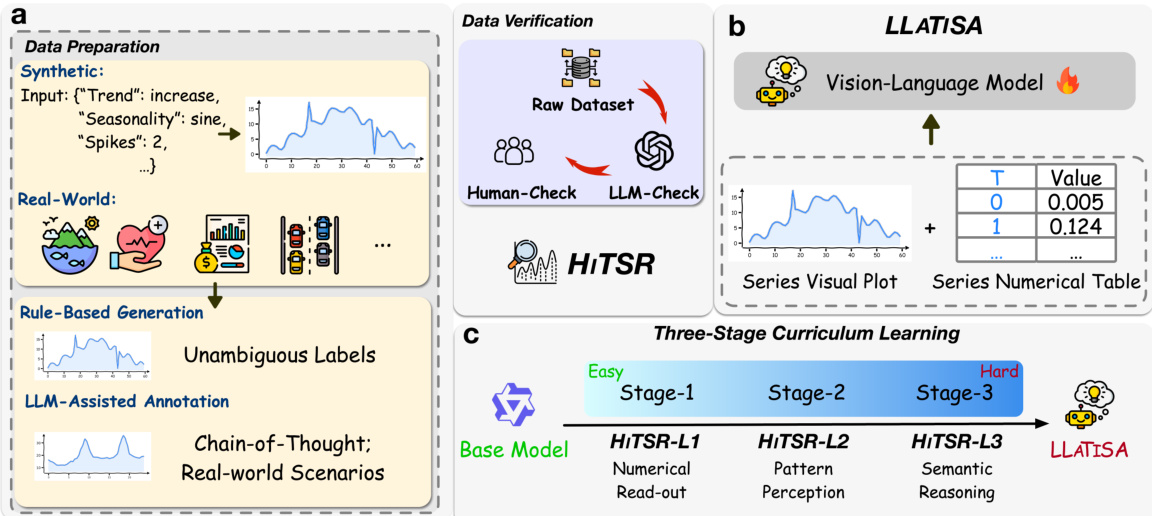
The model architecture, LLATiSA, is designed to process time series data through a dual-modal input format, integrating visual and numerical information. The visual component consists of a series plot, where the lookback context and candidate prediction are rendered in blue and red, respectively, enabling comparative analysis of temporal continuity. This is complemented by a numerical table that provides precise values for the lookback window, ensuring fine-grained grounding. This dual-view strategy allows the model to leverage global trend intuition from the plots while maintaining numerical precision.
The training process employs a three-stage curriculum learning approach. The first stage focuses on HiTSR-L1, emphasizing numerical read-out tasks. The second stage targets HiTSR-L2, involving pattern perception. The third stage addresses HiTSR-L3, requiring semantic reasoning. This staged progression ensures that the model builds capabilities incrementally, starting from basic perception to complex reasoning. The base model is enhanced through this curriculum, culminating in the LLATiSA model, which is trained to handle the full range of difficulty levels in the HiTSR dataset.
Experiment
The experiments evaluate the LLaTISA model across four levels of time series reasoning (L1–L4) using out-of-distribution benchmarks and real-world ECG interpretation tasks. By comparing various encoding strategies and training paradigms, the study validates that a dual-view multimodal approach combined with a multi-stage curriculum significantly enhances performance and generalization. The results demonstrate that integrating visual global context with indexed textual numerical data, alongside Chain-of-Thought reasoning, allows the model to effectively transition from basic value localization to complex semantic understanding and predictive inference.
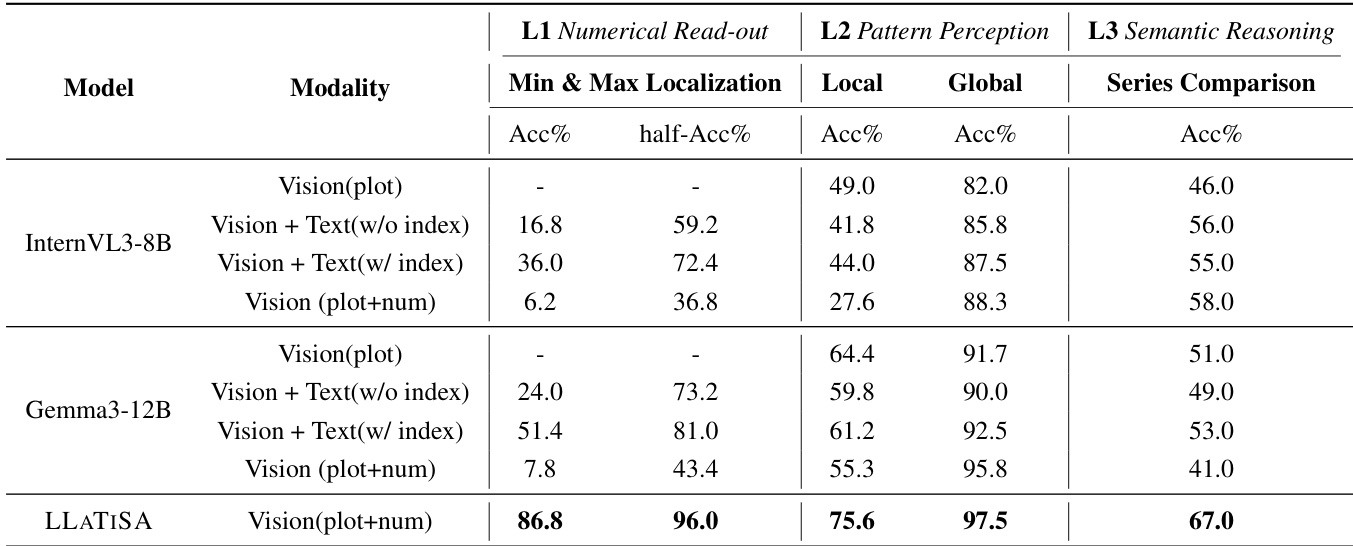
The authors compare the performance of various models on time series reasoning tasks across different levels, including numerical read-out, pattern perception, and semantic reasoning. The results show that LLATISA consistently outperforms other models, particularly in tasks requiring precise numerical grounding and complex reasoning, across all levels. The integration of visual and textual modalities with explicit index information leads to significant improvements in accuracy and success rate. LLATISA achieves the highest performance across all tasks and levels compared to other models. The combination of vision and text with index information significantly improves performance in numerical grounding and reasoning tasks. Models using only vision or text modalities show lower accuracy, especially in tasks requiring precise numerical understanding.
The authors evaluate LLATISA's performance on ECG interpretation tasks, comparing it against baseline models across in-distribution and out-of-distribution settings. Results show that LLATISA achieves superior performance in lead-wise assessment and diagnostic accuracy, particularly in out-of-distribution scenarios, and outperforms other models despite being fine-tuned on a significantly smaller dataset. LLATISA achieves higher lead assessment coverage and accuracy compared to baseline models in both in-distribution and out-of-distribution settings. LLATISA outperforms GEM and Qwen3-VL-8B in diagnostic accuracy and evidence-based reasoning, especially in out-of-distribution scenarios. LLATISA demonstrates strong performance with significantly less training data compared to other models, indicating high data efficiency.
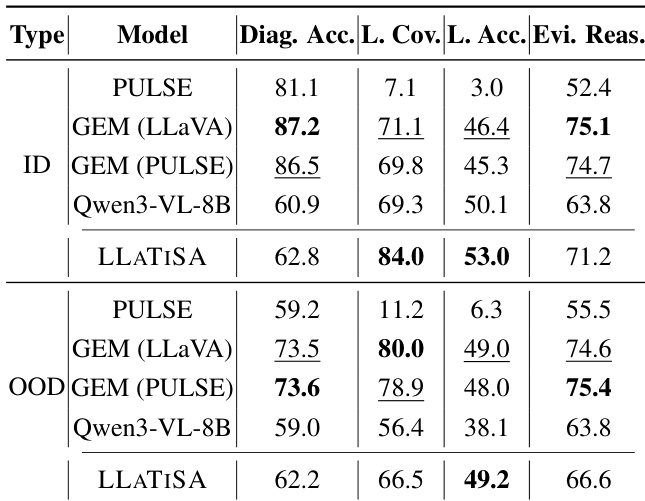
The authors compare various time series reasoning models across different datasets and tasks, focusing on their performance in out-of-distribution settings. Results show that the proposed model consistently outperforms baselines, particularly in tasks requiring multi-level reasoning and structured analysis. The model demonstrates strong generalization to real-world applications, such as ECG interpretation, with significant improvements in accuracy and lead-specific analysis. The proposed model achieves superior performance across diverse time series reasoning tasks, especially in out-of-distribution scenarios. It shows significant improvements in real-world applications like ECG interpretation, demonstrating strong generalization and data efficiency. The model's effectiveness is enhanced by a multi-stage curriculum and dual-view encoding, which improve reasoning and task adherence.
The experiment evaluates a model's performance across three levels of time series reasoning tasks, from basic numerical read-out to complex semantic understanding. The model demonstrates strong capabilities in numerical grounding and pattern perception, with consistent improvements observed when using dual-view encoding strategies and curriculum learning. Results show that the model outperforms various baselines, particularly in tasks requiring precise value localization and contextual reasoning. The model achieves significant improvements in numerical grounding and pattern perception tasks compared to baseline methods. Dual-view encoding strategies consistently outperform single-modality approaches across all task levels. Curriculum learning enhances performance, especially on complex tasks requiring semantic reasoning and generalization to real-world applications.
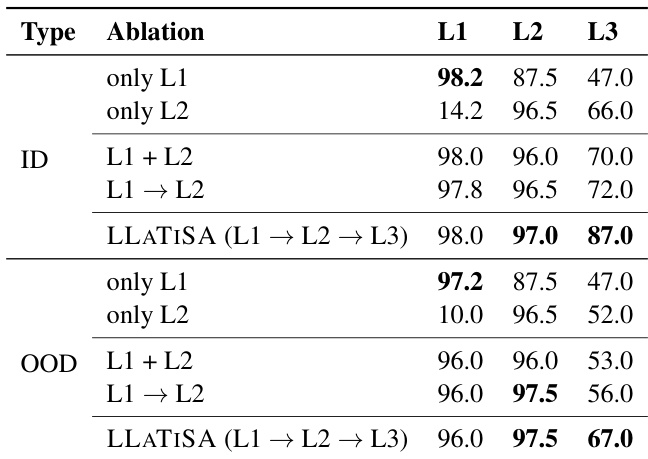
The authors conduct an ablation study to evaluate the impact of curriculum learning on model performance across different task levels. Results show that a sequential curriculum training approach consistently outperforms joint training strategies, with the model achieving the highest accuracy on all levels when trained sequentially. The performance gains are particularly pronounced in out-of-distribution settings, indicating the importance of structured, level-wise training for robust generalization. Sequential curriculum training achieves higher accuracy than joint training across all task levels. The model performs best when trained in a stepwise manner from L1 to L3, especially in out-of-distribution scenarios. Performance improvements are more significant in OOD settings, highlighting the role of curriculum learning in generalization.
The authors evaluate LLATISA through multi-level time series reasoning tasks, ECG interpretation, and ablation studies to validate its reasoning capabilities and generalization. The results demonstrate that integrating visual and textual modalities with dual-view encoding and index information significantly enhances numerical grounding and semantic reasoning compared to single-modality baselines. Furthermore, the model exhibits high data efficiency and superior out-of-distribution performance, particularly when employing a sequential curriculum learning strategy.