Command Palette
Search for a command to run...
Seedance 2.0 : Faire progresser la génération de vidéo pour la complexité du monde.
Seedance 2.0 : Faire progresser la génération de vidéo pour la complexité du monde.
Résumé
Voici la traduction de votre texte en français, en respectant les standards de la communication scientifique et technologique :Seedance 2.0 est un nouveau modèle de génération audio-vidéo multi-modale natif, officiellement lancé en Chine au début du mois de février 2026. Comparativement à ses prédécesseurs, Seedance 1.0 et 1.5 Pro, Seedance 2.0 adopte une architecture unifiée, hautement efficace et à grande échelle pour la génération conjointe de contenus audio et vidéo. Cette structure lui permet de prendre en charge quatre modalités d'entrée : le texte, l'image, l'audio et la vidéo, en intégrant l'une des suites de capacités de référence et d'édition de contenu multi-modal les plus complètes du secteur à ce jour. Le modèle apporte des améliorations substantielles et équilibrées dans toutes les dimensions clés de la génération vidéo et audio. Lors des évaluations d'experts ainsi que des tests utilisateurs publics, le modèle a démontré des performances comparables aux niveaux de pointe du domaine.Seedance 2.0 permet la génération directe de contenus audio-vidéo d'une durée comprise entre 4 et 15 secondes, avec des résolutions de sortie natives de 480p et 720p. Pour l'utilisation d'entrées multi-modales comme référence, sa plateforme ouverte actuelle supporte jusqu'à 3 clips vidéo, 9 images et 3 clips audio. De plus, nous proposons la version « Seedance 2.0 Fast », une variante accélérée de Seedance 2.0 conçue pour augmenter la vitesse de génération dans des scénarios à faible latence. Seedance 2.0 a apporté des améliorations significatives à ses capacités de génération fondamentales ainsi qu'à ses performances de génération multi-modale, offrant ainsi une expérience créative enrichie aux utilisateurs finaux.
One-sentence Summary
Please provide the abstract of the paper so that I may rewrite it into a single, polished sentence that preserves all concrete details regarding the Seedance 2.0 model, its method, and its evaluation.
Key Contributions
- Seedance 2.0 introduces a unified multimodal audio-video joint generation framework that features enhanced controllability through instruction-following, subject identity preservation, and autonomous directorial reasoning for shot sequencing.
- The model incorporates an upgraded audio generation module equipped with binaural technology to produce high-fidelity, immersive soundscapes with precise temporal synchronization between multi-track audio and visual actions.
- This work implements versatile video manipulation capabilities, including targeted editing of specific clips or characters and video continuation functionality for generating seamless consecutive shots.
Introduction
Video generation models are essential to modern digital content infrastructure and generative AI ecosystems. While previous models focused on generating short clips with limited controllability, they often struggled with complex motion stability, physical plausibility, and precise multi-modal integration. The authors leverage a unified, large-scale architecture to introduce Seedance 2.0, a native multi-modal audio-video generation model. This contribution enables robust, highly controllable synthesis by supporting text, image, audio, and video inputs simultaneously to achieve high-fidelity synchronization and professional-grade directorial control.
Method
The authors leverage SeedVideoBench 2.0 to establish a comprehensive evaluation framework for video generation models, emphasizing both multimodal task adherence and narrative quality. The framework introduces two primary innovations: a multimodal task evaluation system that formalizes instruction-following and generation consistency across diverse modalities, and a dual-track evaluation approach combining objective and subjective assessments. Objective metrics, such as motion stability, are computed through automated pipelines, while subjective evaluations—focusing on aesthetics and narrative quality—are conducted via blind expert reviews. A realism study was also performed, where evaluators attempted to distinguish model outputs from real video clips, with results informing the aesthetic tuning process.
At the core of the evaluation is the multimodal task evaluation module, which measures instruction-following accuracy across four distinct task groups. These include reference tasks involving subject, motion, visual effects, and style generation; editing tasks covering subject, style, scene, and audio modifications; extension tasks that assess plot continuation and seamless temporal extension in both forward and backward directions; and combination tasks that simulate real-world workflows, such as replacing a video subject with a reference image. This fine-grained categorization enables explicit characterization of model capabilities, addressing the limitation of narrow multimodal coverage that previously required trial-and-error probing.
Consistency is evaluated through two dimensions: reference alignment, which measures how closely generated content matches the input reference, and editing consistency, which assesses the preservation of non-edited regions during modifications. To ensure robustness, specialized datasets are constructed for subject, motion, scene, style, and audio, with sample distributions optimized to minimize variance under limited evaluation budgets.
On the narrative quality front, SeedVideoBench 2.0 extends beyond the existing metrics of vividness and aesthetics by introducing finer-grained narrative dimensions. Unlike motion quality, which is amenable to objective measurement, narrative quality is inherently subjective and evaluates whether the generated content conveys a coherent story. This is assessed across three sub-dimensions: cinematographic language, which examines whether camerawork supports the narrative through shot logic, expressiveness, and adherence to cinematic conventions such as the 180-degree rule and shot size consistency; plot design, which evaluates the model's ability to generate engaging and coherent narratives from brief or vague prompts; and stylistic aesthetics, which considers the overall visual coherence in terms of lighting, framing, composition, color grading, and the consistency of characters, costumes, props, and sets.

Experiment
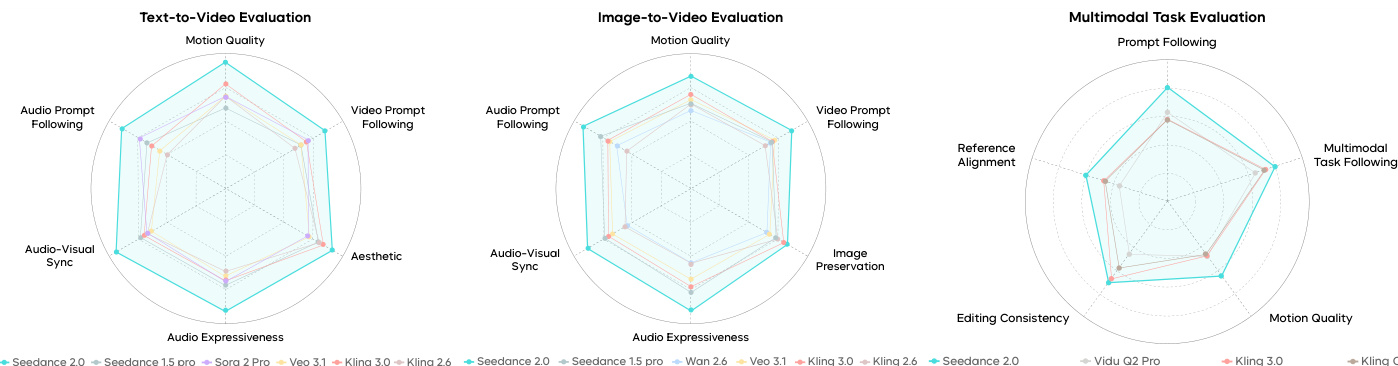
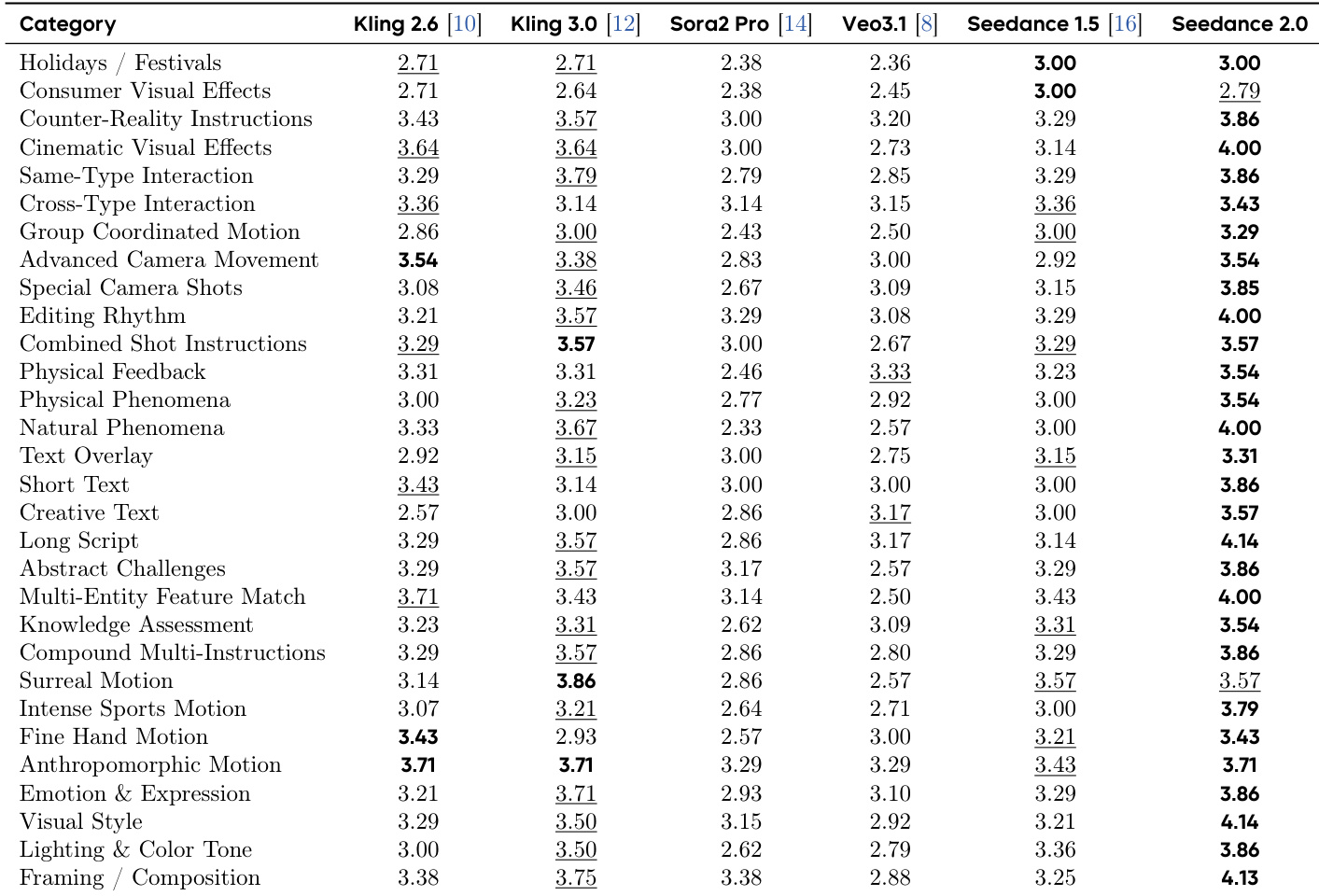
Seedance 2.0 was evaluated using the SeedVideoBench 2.0 framework and human preference testing on Arena.AI to assess its capabilities in text-to-video, image-to-video, and reference-based generation. The experiments validate the model's superior performance in motion stability, cinematic aesthetics, complex instruction following, and high-fidelity audio-visual synchronization. Overall, the model demonstrates significant advancements in generating nuanced facial expressions, realistic physical movements, and layered, contextually aligned audio compared to existing commercial models.
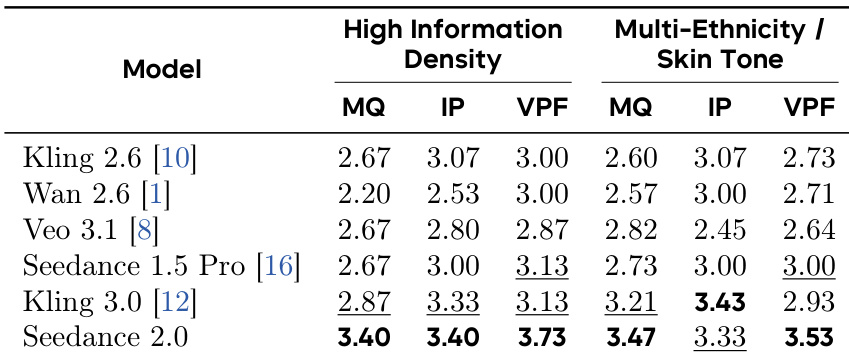
The model achieves top performance across all evaluated dimensions in complex reference-based image-to-video generation tasks. It demonstrates superior motion quality, image preservation, and prompt following, particularly in high-information-density and multi-ethnicity scenarios. Seedance 2.0 leads on all metrics in complex reference tasks It achieves the highest scores in motion quality and prompt following It outperforms competitors in maintaining reference consistency for high-information-density and multi-ethnicity content
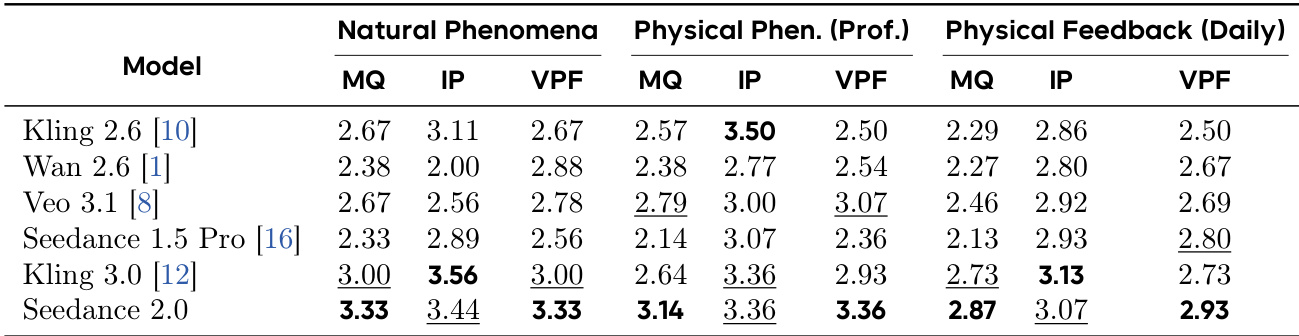
Seedance 2.0 achieves top performance across multiple evaluation dimensions in both motion quality and audio-related tasks. The model demonstrates significant improvements over previous versions and competitors, particularly in motion stability, physical realism, and audio-visual synchronization. Seedance 2.0 ranks first in all evaluated dimensions for motion quality and audio-visual sync The model shows strong improvements in physical realism and motion stability compared to prior versions Seedance 2.0 outperforms competitors in audio-visual alignment and audio expressiveness
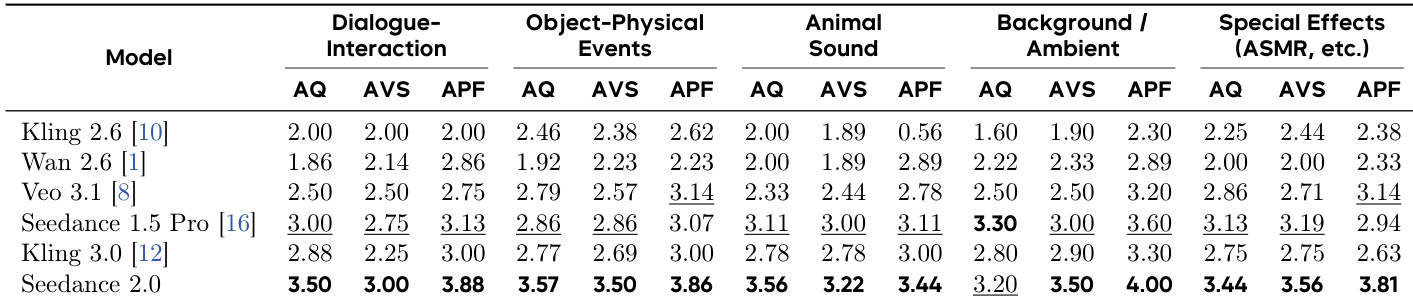
The the the table compares audio-visual performance across models, with Seedance 2.0 achieving the highest scores in audio quality, audio-visual sync, and audio prompt following across all categories. It demonstrates superior performance in background sound and special effects, significantly outperforming other models in audio expressiveness and synchronization. Seedance 2.0 achieves the highest scores in audio quality, audio-visual sync, and audio prompt following across all evaluated categories. The model shows strong performance in background sound and special effects, with top ratings in audio quality and sync. Seedance 2.0 significantly outperforms competitors in audio expressiveness and alignment between audio and visual elements.
The authors evaluate Seedance 2.0 across multiple video generation dimensions, showing it achieves top rankings in all categories compared to other models. The results demonstrate significant improvements in motion quality, audio-visual alignment, and instruction following, with particularly strong performance in complex motion and audio-related tasks. Seedance 2.0 achieves the highest scores in all evaluated dimensions compared to competing models. The model shows superior performance in motion quality and audio-visual synchronization across various complex scenarios. Seedance 2.0 leads in audio-related tasks, including audio expressiveness and prompt following, where other models show significant weaknesses.
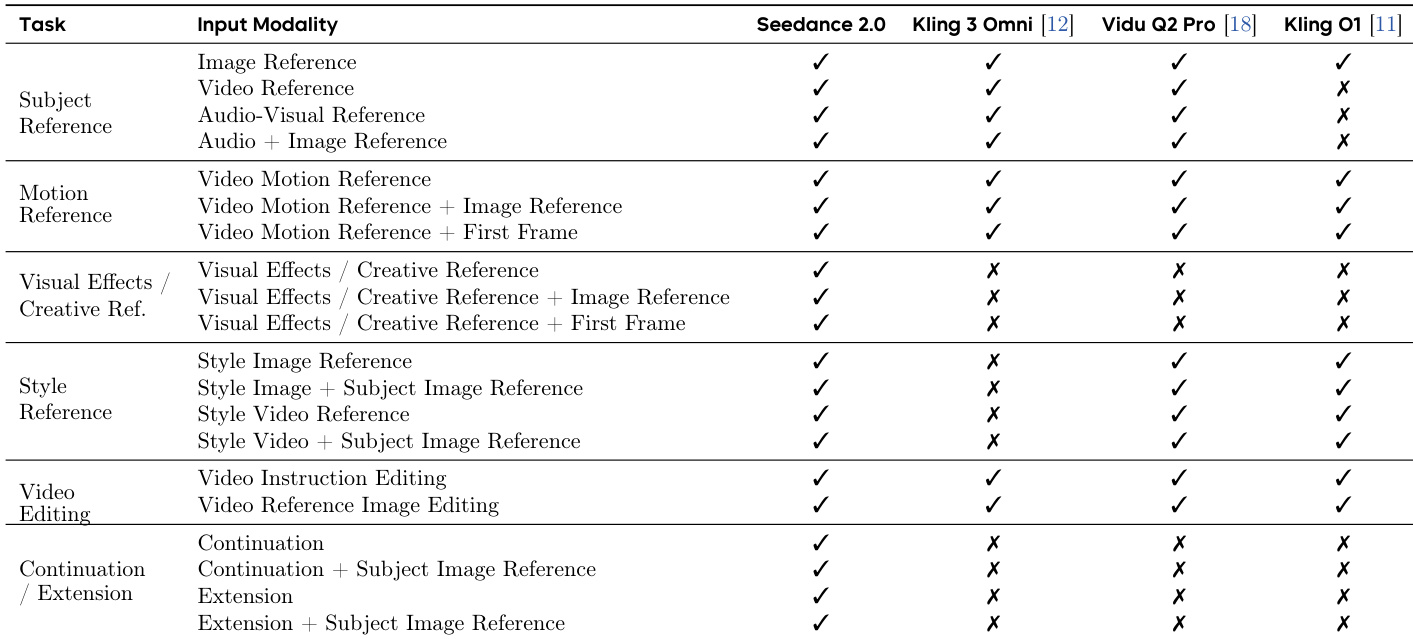
The the the table compares the support for various reference modalities across different video generation tasks. Seedance 2.0 supports the most comprehensive range of reference types, including subject, motion, visual effects, style, and video editing, across multiple input modalities. Other models show more limited support, with several lacking capabilities in key areas like audio-visual reference and complex editing. Seedance 2.0 supports the broadest range of reference types across all tasks Other models lack support for audio-visual and complex reference modalities Seedance 2.0 enables a wider variety of creative and editing scenarios
Seedance 2.0 was evaluated across various video generation tasks to validate its performance in complex reference-based image-to-video generation, audio-visual synchronization, and multi-modal reference support. The model demonstrates superior motion quality, physical realism, and prompt following, particularly when handling high-information-density content and diverse ethnicities. Furthermore, it achieves exceptional audio-visual alignment and offers the most comprehensive range of reference modalities, enabling more versatile creative and editing scenarios than its competitors.