Command Palette
Search for a command to run...
Repenser la Distillation On-Policy des Large Language Models : Phénoménologie, Mécanisme et Recette
Repenser la Distillation On-Policy des Large Language Models : Phénoménologie, Mécanisme et Recette
Résumé
Voici la traduction de votre texte en français, respectant les standards de la communication scientifique et technique :La distillation on-policy (OPD) est devenue une technique centrale dans la phase de post-entraînement des grands modèles de langage (LLMs), pourtant sa dynamique d'entraînement demeure mal comprise. Cet article propose une investigation systématique des dynamiques et des mécanismes de l'OPD. Nous identifions d'abord que deux conditions régissent le succès ou l'échec de l'OPD : (i) l'étudiant et l'enseignant doivent partager des schémas de pensée (thinking patterns) compatibles ; et (ii) même avec des schémas de pensée cohérents et des scores plus élevés, l'enseignant doit offrir des capacités réellement nouvelles, dépassant ce que l'étudiant a déjà rencontré durant son training. Nous validons ces conclusions à travers une distillation inverse de type "weak-to-strong", démontrant que des enseignants de même famille (1.5B et 7B) sont indiscernables sur le plan distributionnel du point de vue de l'étudiant. En explorant le mécanisme au niveau des tokens, nous démontrons qu'une OPD réussie se caractérise par un alignement progressif sur les tokens à haute probabilité dans les états visités par l'étudiant, via un petit ensemble de tokens partagés qui concentre la majeure partie de la masse de probabilité (97 % - 99 %). Nous proposons ensuite deux stratégies pratiques pour remédier à une OPD défaillante : le "off-policy cold start" et la sélection de prompts alignés sur l'enseignant (teacher-aligned prompt selection). Enfin, nous montrons que l'apparent "free lunch" de l'OPD, consistant en une récompense dense au niveau des tokens, a un coût, ce qui soulève la question de savoir si l'OPD peut passer à l'échelle pour une distillation sur de longs horizons (long-horizon distillation).
One-sentence Summary
Through a systematic investigation of on-policy distillation (OPD) dynamics in large language model post-training, this paper identifies that success depends on compatible thinking patterns and teacher novelty, uncovers a token-level mechanism characterized by progressive alignment on high-probability tokens, and proposes off-policy cold start and teacher-aligned prompt selection to recover failing distillation processes.
Key Contributions
- The paper identifies two fundamental conditions for successful on-policy distillation: the requirement for compatible thinking patterns between the student and teacher, and the necessity for the teacher to provide genuinely new capabilities that the student has not encountered during training.
- The study reveals a token-level mechanism where successful distillation is characterized by progressive alignment on high-probability tokens at student-visited states, with a small shared token set concentrating 97% to 99% of the probability mass.
- Two practical strategies, off-policy cold start and teacher-aligned prompt selection, are introduced to recover distillation performance when the identified success conditions are not met.
Introduction
On-policy distillation (OPD) has become a vital post-training technique for large language models because it provides dense, per-token supervision that mitigates the exposure bias found in off-policy methods. However, OPD is often fragile, and practitioners frequently encounter scenarios where a stronger teacher fails to improve a student model. The authors investigate this instability by identifying that successful distillation requires both compatible thinking patterns between models and the presence of genuinely new knowledge that the student has not yet acquired. To address these failures, the authors propose two practical strategies: an off-policy cold start to bridge the thinking-pattern gap and teacher-aligned prompt selection to sharpen alignment.
Dataset
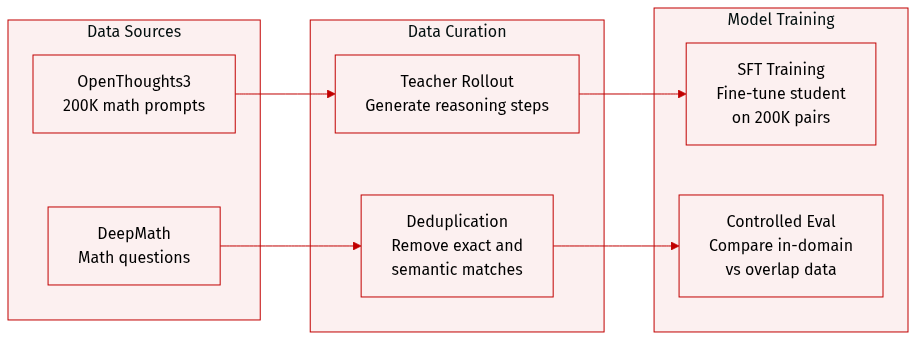
The authors construct several specialized datasets to facilitate cold-start distillation and controlled evaluations:
- Cold-Start SFT Dataset: To initialize the student model, the authors sample 200,000 math prompts from the math subset of OpenThoughts3-1.2M. These prompts are processed through an offline teacher rollout using Qwen3-4B (Non-thinking) with a temperature of 0.7 and a maximum generation length of 12,288 tokens. The resulting dataset is filtered to remove incomplete or degenerate repetitive responses.
- DeepMath Deduplicated Subset: For cross-size experiments, the authors create a version of the DeepMath subset that is deduplicated against DAPO-Math-17K to isolate in-domain prompts from those appearing in the teacher's RL post-training data. This process involves two stages:
- Exact-match deduplication: The instruction suffixes are removed, and any DeepMath question that exactly matches a DAPO-Math-17K question is discarded.
- Semantic deduplication: Questions are encoded using the all-mpnet-base-v2 model. Using a FAISS index, the authors identify near-duplicates by calculating cosine similarity. Any DeepMath question with a similarity score of 0.6 or higher to its nearest neighbor in DAPO-Math-17K is removed.
- Model Training and Usage:
- The filtered 200,000 teacher-generated pairs are used for full-parameter supervised fine-tuning (SFT) on the Qwen3-1.7B-Base model to produce Qwen3-1.7B-SFT.
- The deduplicated DeepMath subset is used to enable a controlled comparison between prompts that overlap with teacher post-training data and those that are strictly in-domain.
Method
The authors present a framework for On-Policy Distillation (OPD), a method that transfers knowledge from a teacher language model πT to a student model πθ by minimizing the divergence between their next-token distributions on trajectories sampled from the current student policy. The core mechanism operates in an on-policy setting, where for each prompt x drawn from the dataset Dx, the student generates a response y^=(y^1,…,y^T) through autoregressive sampling. At each step t, the student's distribution pt(v)=πθ(v∣x,y^<t) and the teacher's distribution qt(v)=πT(v∣x,y^<t) are compared. The primary objective is to minimize the sequence-level reverse Kullback-Leibler (KL) divergence between the student's and teacher's generated trajectories, which decomposes into a sum of per-token KL divergences over the rollout.

As shown in the figure above, the overall framework is structured into three interconnected components. The first, "Phenomenology," identifies two empirical patterns that distinguish effective OPD: consistent thinking patterns and the observation that higher scores do not necessarily imply the acquisition of new knowledge. The central component, "Mechanism," explains why OPD works at the token level, highlighting that progressive alignment on high-probability tokens governs the process and that overlap tokens alone can suffice for effective distillation. The final component, "Recipe," proposes two strategies to rescue failing OPD instances by bridging the thinking-pattern gap, specifically off-policy cold start and teacher-aligned prompts.
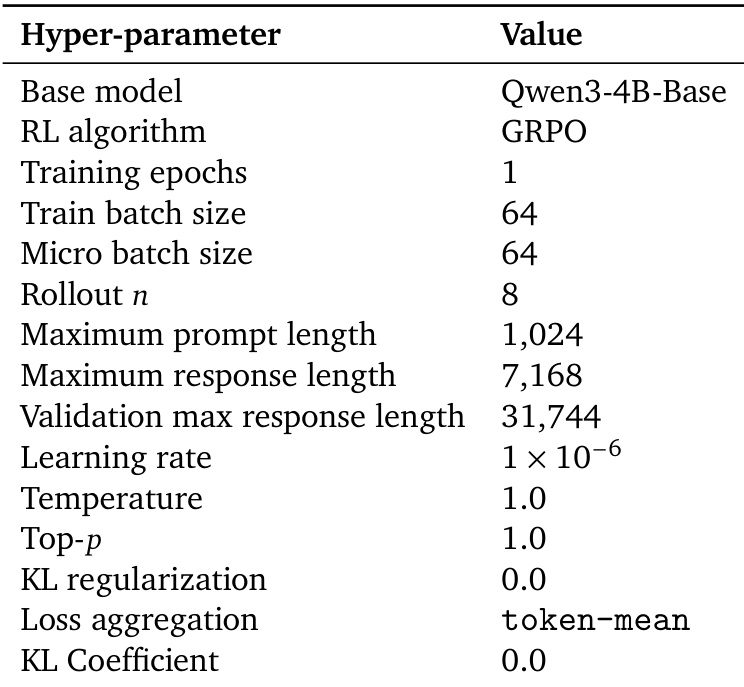
The framework encompasses three distinct implementations of OPD, varying in the granularity of supervision used to compute the KL divergence. The most lightweight variant, sampled-token OPD, evaluates the divergence only at the specific token sampled by the student at each step, using the loss ℓtsample=logpt(y^t)−logqt(y^t). In contrast, full-vocabulary OPD computes the KL divergence over the entire vocabulary at each step, providing denser gradients but at a higher computational cost. Top-k OPD offers a middle ground by restricting the divergence computation to a subset St of the vocabulary, typically the top-k tokens with the highest probability under the student's distribution. This approach approximates the full-vocabulary KL divergence while significantly reducing the number of teacher queries, focusing supervision on the student's high-probability region. The authors further define metrics to monitor the distillation process, including the overlap ratio, which measures the alignment between the student's and teacher's top-k sets, the overlap-token advantage, which assesses distributional agreement within the overlapping tokens, and the entropy gap, which tracks the difference in uncertainty between the two models.
Experiment
These experiments investigate the conditions and mechanisms governing On-Policy Distillation (OPD) effectiveness by comparing various teacher-student model pairings and training configurations. The results demonstrate that successful distillation depends on thinking-pattern consistency and the presence of new knowledge rather than mere benchmark performance or model scale. Mechanistically, effective OPD is driven by progressive alignment on shared high-probability tokens, a process that can be enhanced through off-policy cold starts or the use of teacher-aligned prompts.
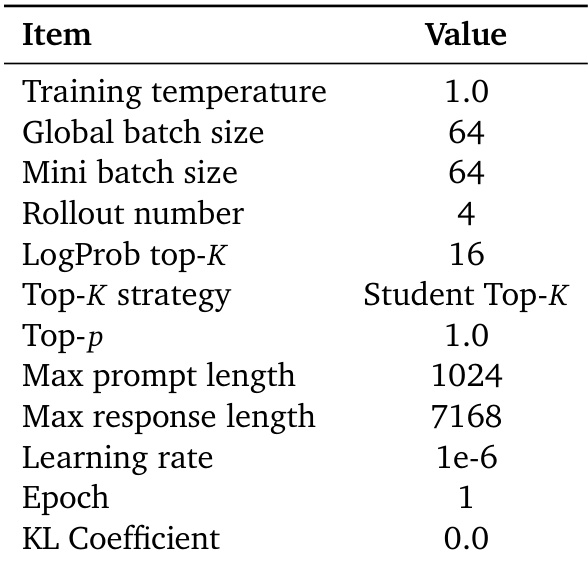
The the the table lists the default hyperparameters used for On-Policy Distillation (OPD) training, including settings for batch size, learning rate, and token support. These parameters define the training configuration for the experiments described in the paper. OPD uses a fixed learning rate of 1e-6 and a global batch size of 64. The training employs a Student Top-K strategy with a LogProb top-K of 16. KL regularization is disabled with a coefficient of 0.0 during training.
The figure compares successful and failed on-policy distillation training runs, showing that successful distillation is characterized by steady alignment on high-probability tokens, while failure occurs when this alignment stagnates. The main gradients and advantages come from overlapping tokens, which drive the optimization process. Successful OPD shows increasing overlap on high-probability tokens, while failed OPD shows stagnant alignment. The primary optimization signal in OPD comes from shared tokens between student and teacher. Failure occurs when the student cannot align with the teacher's high-probability tokens, leading to weak gradients and no improvement.

The authors investigate the conditions under which on-policy distillation (OPD) succeeds, finding that thinking-pattern consistency between student and teacher models is crucial for effective knowledge transfer. Even when a teacher model outperforms the student, OPD fails if their reasoning patterns are mismatched, and successful distillation occurs only when the teacher possesses new capabilities beyond the student's existing knowledge. Thinking-pattern consistency between student and teacher is essential for successful OPD OPD fails when the teacher's reasoning pattern is incompatible with the student's, regardless of benchmark performance New knowledge acquired by the teacher through post-training enables stronger gains in OPD
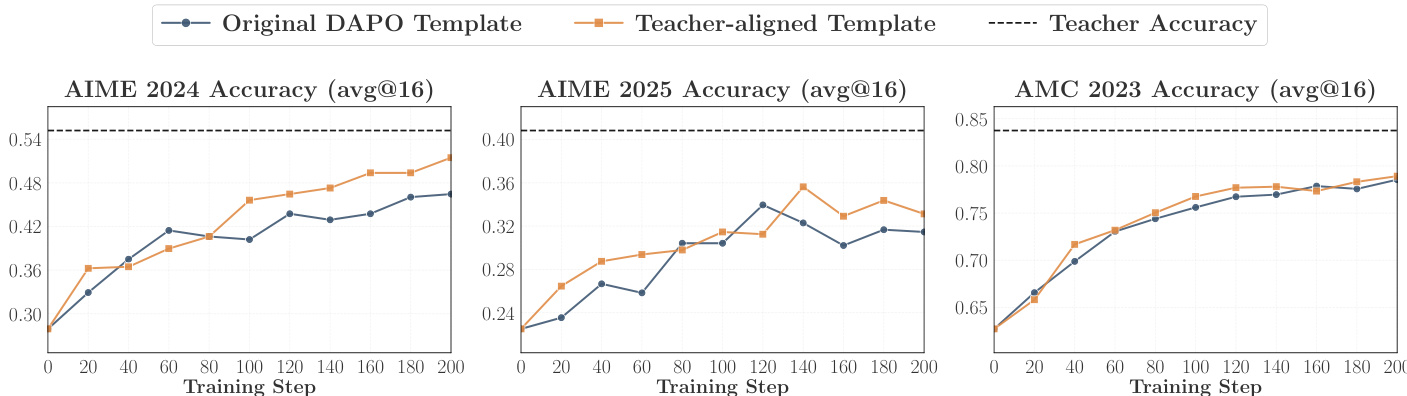
The experiment compares OPD performance using different prompt templates, showing that the teacher-aligned template leads to higher accuracy and better overlap growth across benchmarks. Results indicate that aligning the prompt format with the teacher's training data enhances distillation effectiveness by improving compatibility between student and teacher thinking patterns. Using a teacher-aligned prompt template improves accuracy and overlap growth in OPD The teacher-aligned template yields consistent gains across multiple benchmarks Prompt alignment enhances student-teacher compatibility, leading to better distillation outcomes
The experiment compares distillation from two teachers with different thinking patterns into the same student model. Results show that the teacher with a more compatible thinking pattern achieves stronger performance and higher initial overlap, indicating that thinking-pattern consistency governs OPD effectiveness. Despite similar benchmark performance, the more aligned teacher produces better distillation outcomes. Distillation from a teacher with a compatible thinking pattern outperforms distillation from a mismatched teacher. Initial overlap ratio correlates with downstream performance, suggesting early pattern alignment is crucial. Performance gap persists despite converging overlap curves, indicating early mismatch reduces distillation benefit.
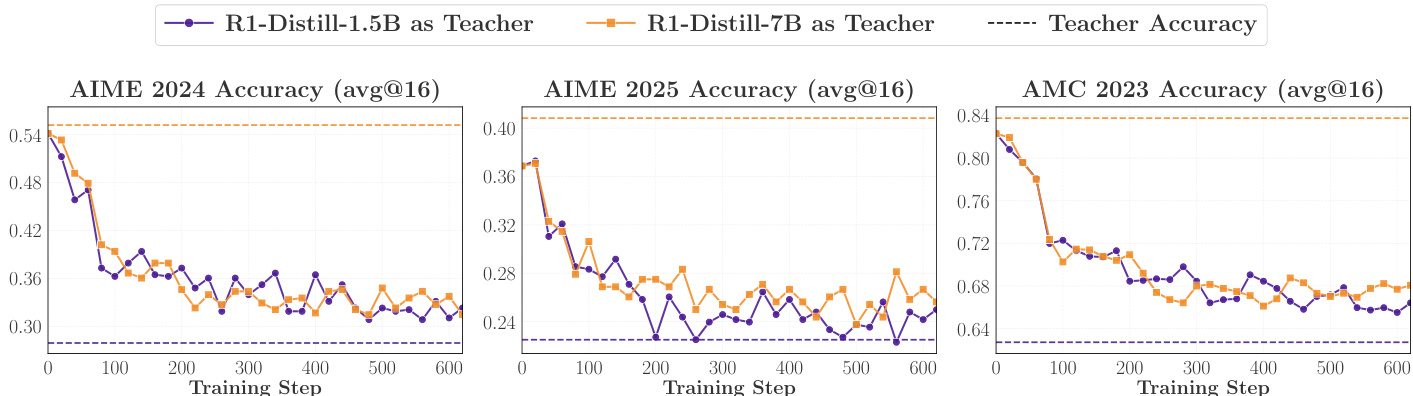
The experiments evaluate the dynamics and success factors of On-Policy Distillation (OPD) by analyzing training stability, thinking-pattern consistency, and prompt alignment. Results demonstrate that successful distillation relies on the student's ability to align with the teacher's high-probability tokens, a process driven by shared reasoning patterns. Ultimately, the effectiveness of OPD is determined by the compatibility of thinking patterns between the teacher and student, which can be further optimized through the use of teacher-aligned prompt templates.