Command Palette
Search for a command to run...
OccuBench : Évaluation des AI Agents sur des tâches professionnelles du monde réel via des Language World Models
OccuBench : Évaluation des AI Agents sur des tâches professionnelles du monde réel via des Language World Models
Xiaomeng Hu Yinger Zhang Fei Huang Jianhong Tu Yang Su Lianghao Deng Yuxuan Liu Yantao Liu Dayiheng Liu Tsung-Yi Ho
Résumé
Voici la traduction française de votre texte, réalisée selon les standards de rigueur scientifique et de précision terminologique requis :On s'attend à ce que les AI agents accomplissent des tâches professionnelles dans des centaines de domaines d'activité (allant du triage aux urgences médicales à la surveillance de la sécurité des réacteurs nucléaires, jusqu'au traitement des importations douanières). Pourtant, les benchmarks actuels ne permettent d'évaluer les agents que dans les rares domaines où des environnements publics existent. Nous introduisons OccuBench, un benchmark couvrant 100 scénarios de tâches professionnelles réelles, répartis sur 10 catégories industrielles et 65 domaines spécialisés. Ce projet est rendu possible par les Language World Models (LWMs), qui simulent des environnements spécifiques à chaque domaine grâce à une génération de réponses d'outils pilotée par des LLMs. Notre pipeline de synthèse multi-agents produit automatiquement des instances d'évaluation garantissant la résolvabilité, un niveau de difficulté calibré et une diversité ancrée dans des documents réels.OccuBench évalue les agents selon deux dimensions complémentaires : l'accomplissement des tâches à travers les domaines professionnels et la robustesse environnementale sous injection de fautes contrôlées (erreurs explicites, dégradation implicite des données et fautes mixtes). Nous avons évalué 15 modèles de pointe issus de 8 familles de modèles et avons constaté que :(1) Aucun modèle unique ne domine l'ensemble des industries, car chacun possède un profil de capacité professionnelle distinct ;(2) Les fautes implicites (données tronquées, champs manquants) sont plus difficiles à gérer que les erreurs explicites (délais d'attente/timeouts, erreurs 500) ou les fautes mixtes, car elles manquent de signaux d'erreur manifestes et exigent que l'agent détecte de manière autonome la dégradation des données ;(3) Les modèles plus larges, les nouvelles générations et un effort de raisonnement (reasoning effort) plus élevé améliorent systématiquement les performances. Par exemple, GPT-5.2 progresse de 27,5 points entre un effort de raisonnement minimal et maximal ;(4) Des agents performants ne sont pas nécessairement de bons simulateurs d'environnement. La qualité du simulateur est cruciale pour la fiabilité de l'évaluation basée sur les LWMs.OccuBench constitue la première évaluation systématique inter-industrielle des AI agents appliquée à des tâches professionnelles spécialisées.
One-sentence Summary
To evaluate AI agents, the researchers propose OccuBench, a benchmark covering 100 real-world professional scenarios across 65 specialized domains that leverages Language World Models to simulate diverse environments and utilizes a multi-agent synthesis pipeline to assess task completion and environmental robustness through solvable, document-grounded, and calibrated evaluation instances.
Key Contributions
- The paper introduces OCCUBENCH, a benchmark that evaluates AI agents across 100 real-world professional task scenarios spanning 10 industry categories and 65 specialized domains.
- This work develops Language World Models (LWMs) that utilize LLMs to simulate domain-specific environments through tool response generation, enabling stateful multi-step interactions and realistic action spaces.
- The research presents a multi-agent synthesis pipeline to automatically produce evaluation instances with guaranteed solvability and calibrated difficulty, while measuring agent performance through both task completion and environmental robustness under controlled fault injection.
Introduction
As AI agents move toward high-value applications like healthcare triage, financial auditing, and industrial monitoring, they require robust evaluation in complex, multi-step professional environments. Current benchmarks are largely limited to accessible domains like web browsing or code editing, leaving the vast majority of specialized occupational tasks untestable due to the high engineering cost of building custom APIs and simulators. Furthermore, existing frameworks often focus on "happy path" scenarios and fail to assess how agents handle real-world environmental noise such as data degradation or service timeouts.
The authors leverage Language World Models (LWMs) to transform environment construction from an engineering challenge into a configuration task, using LLMs to simulate domain-specific tool responses. They introduce OccuBench, a benchmark covering 100 professional scenarios across 10 industries and 65 specialized domains. This framework enables a systematic evaluation of both task completion and environmental robustness through controlled fault injection, providing a scalable way to measure an agent's fitness for diverse professional roles.
Dataset

-
Dataset Composition and Sources: The authors developed OccuBench, a benchmark consisting of 382 solvable task instances. These instances cover 100 professional task scenarios across 10 industry categories and 65 specialized domains. To ensure high quality and structural diversity, the authors used a multi-agent synthesis pipeline powered by Gemini-3-Flash-Preview to generate environment configurations, task instructions, tool definitions, and verification rubrics.
-
Key Details and Filtering: Each scenario is grounded by a professional reference document covering domain terminology, workflows, and constraints. The authors applied strict filtering rules to remove tasks that were trivially easy (100% autonomous success), unsolvable (0% success), or contained invalid tool schemas. The resulting tasks are complex, averaging 5.5 tools and 16.2 tool calls per instance, and require multi-turn state transitions rather than single-step calls.
-
Data Usage and Difficulty Calibration: For the evaluation set, the authors select the specific difficulty level for each task that yields the lowest autonomous success rate to maximize the benchmark's discriminative power. The dataset is used to evaluate 15 frontier models across 8 different model families.
-
Environmental Fault Injection and Processing: The authors implement a controlled fault injection strategy to test agent robustness during evaluation. While the base data is synthesized in a clean environment (E0), they inject two types of faults via system prompt modifications:
- E1 (Explicit Faults): Randomly injected error responses like HTTP 500 or timeouts that provide clear signals for the agent to retry.
- E2 (Implicit Faults): Degraded responses such as truncated data or empty fields that appear superficially correct, requiring the agent to detect quality issues and re-query.
Method
The authors leverage a Language World Model (LWM) as the core component of their framework, formalized as a function that maps the current state and agent action to the next state and observation: (st+1,ot+1)=fθ(st,at;c). The environment configuration c is composed of four key elements: the system prompt, tool schema, initial state, and state description. These components collectively define the simulation rules, action space, and initial conditions, enabling the LLM to maintain causal consistency implicitly through its context window. The LWM does not learn the transition dynamics from data but instead relies on the pre-trained knowledge of the underlying domain logic encoded in its configuration.
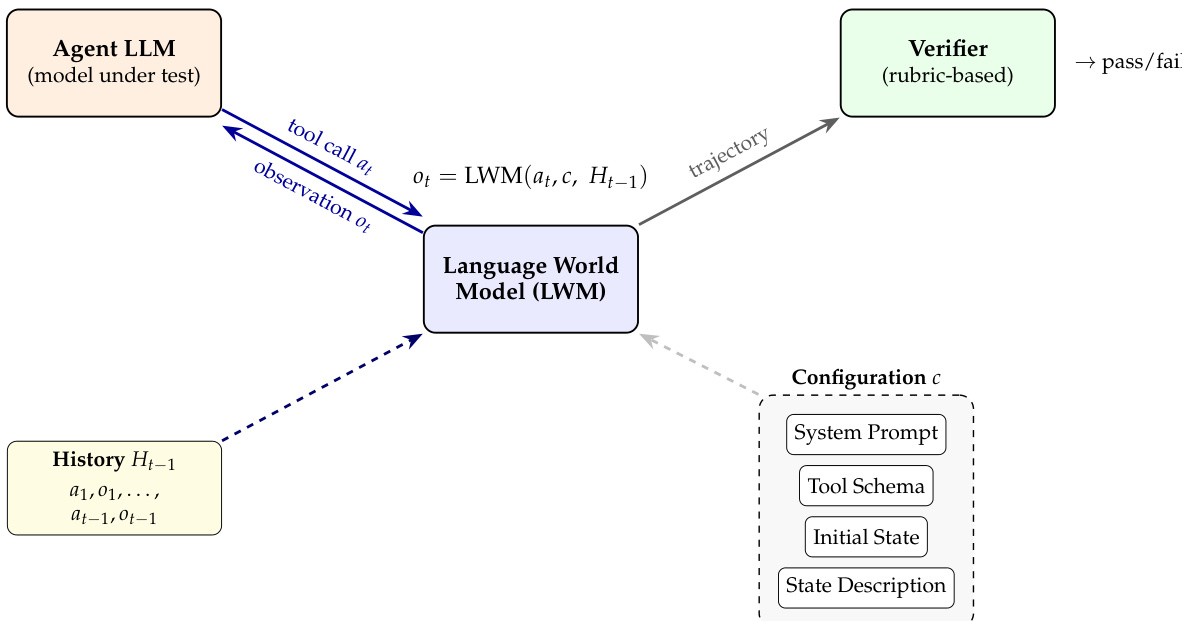
As shown in the figure below, the evaluation loop begins with an Agent LLM that issues a tool call at based on its internal reasoning and the history of prior interactions Ht−1. This history, which includes all previous actions and observations, is maintained in the context of the LLM and serves as input to the LWM. The LWM processes the tool call at, the environment configuration c, and the history Ht−1 to produce an observation ot. The observation is then returned to the Agent LLM, allowing it to update its internal state and plan subsequent actions. The configuration c is external to the LWM but is provided during each interaction, ensuring that the model operates within the defined simulation constraints. The trajectory generated by this process is evaluated by a rubric-based verifier, which assesses the correctness and coherence of the agent's behavior over time. The LWM thus acts as a simulation engine that enables the agent to interact with a structured environment in a controlled and consistent manner.
Experiment
The evaluation utilizes OCCUBENCH to assess agent performance across diverse industry categories and tests environmental robustness through the injection of explicit, implicit, and mixed faults. The findings reveal that no single model excels in all domains, as each exhibits a unique occupational specialization and capability profile. Furthermore, agents struggle significantly with implicit faults that lack clear error signals, and the results highlight that increasing model scale, generational advancement, and reasoning effort all contribute to improved professional task execution.
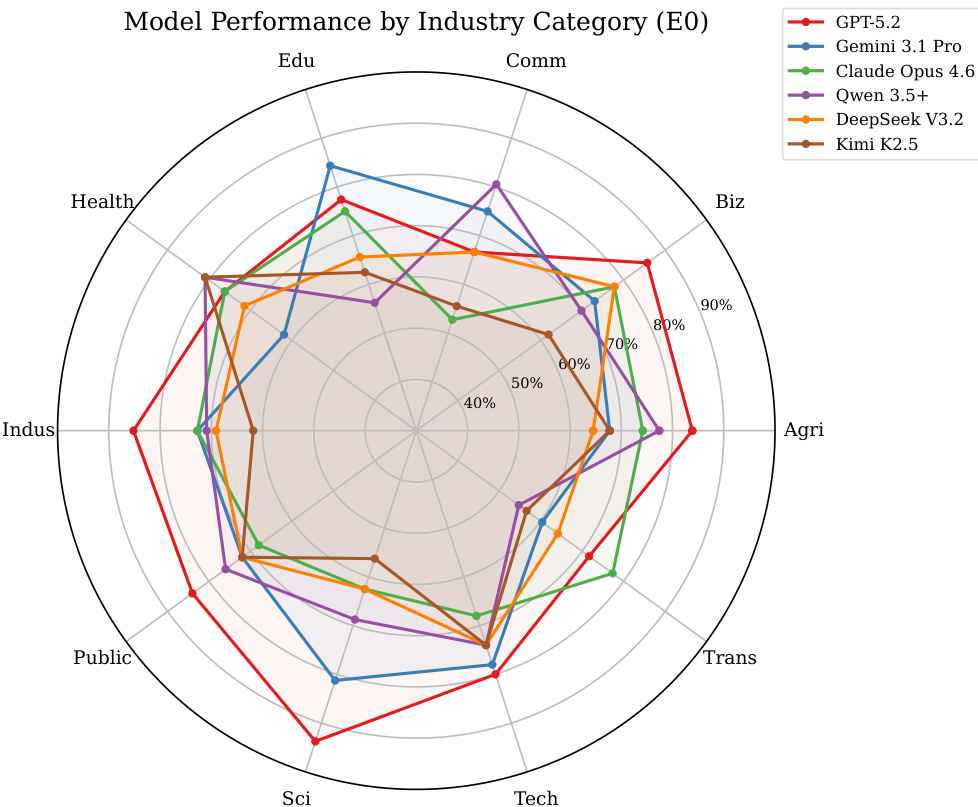
The authors analyze model performance across different industry categories using a radar chart. Results show that no single model excels across all industries, with each model exhibiting a distinct capability profile characterized by strengths and weaknesses in specific domains. The chart reveals significant variation in performance, highlighting diverse occupational specializations among the evaluated models. No model dominates all industries, with each showing a unique pattern of strengths and weaknesses. Performance varies significantly across industries, indicating different occupational specializations for each model. The radar chart visualizes distinct capability profiles, with some models excelling in knowledge-intensive domains and others in operational or consumer-facing areas.
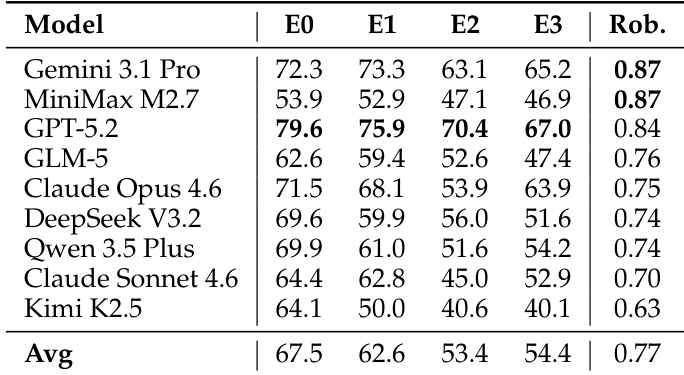
The the the table presents completion rates across different fault conditions and robustness scores for several models. Results show that performance degrades under fault injection, with implicit faults being particularly challenging. Robustness scores highlight significant variation, indicating differences in resilience across models. Performance drops substantially under fault injection, especially with implicit faults. Models exhibit varying resilience, as reflected in their robustness scores. No single model dominates across all fault conditions, indicating diverse failure patterns.
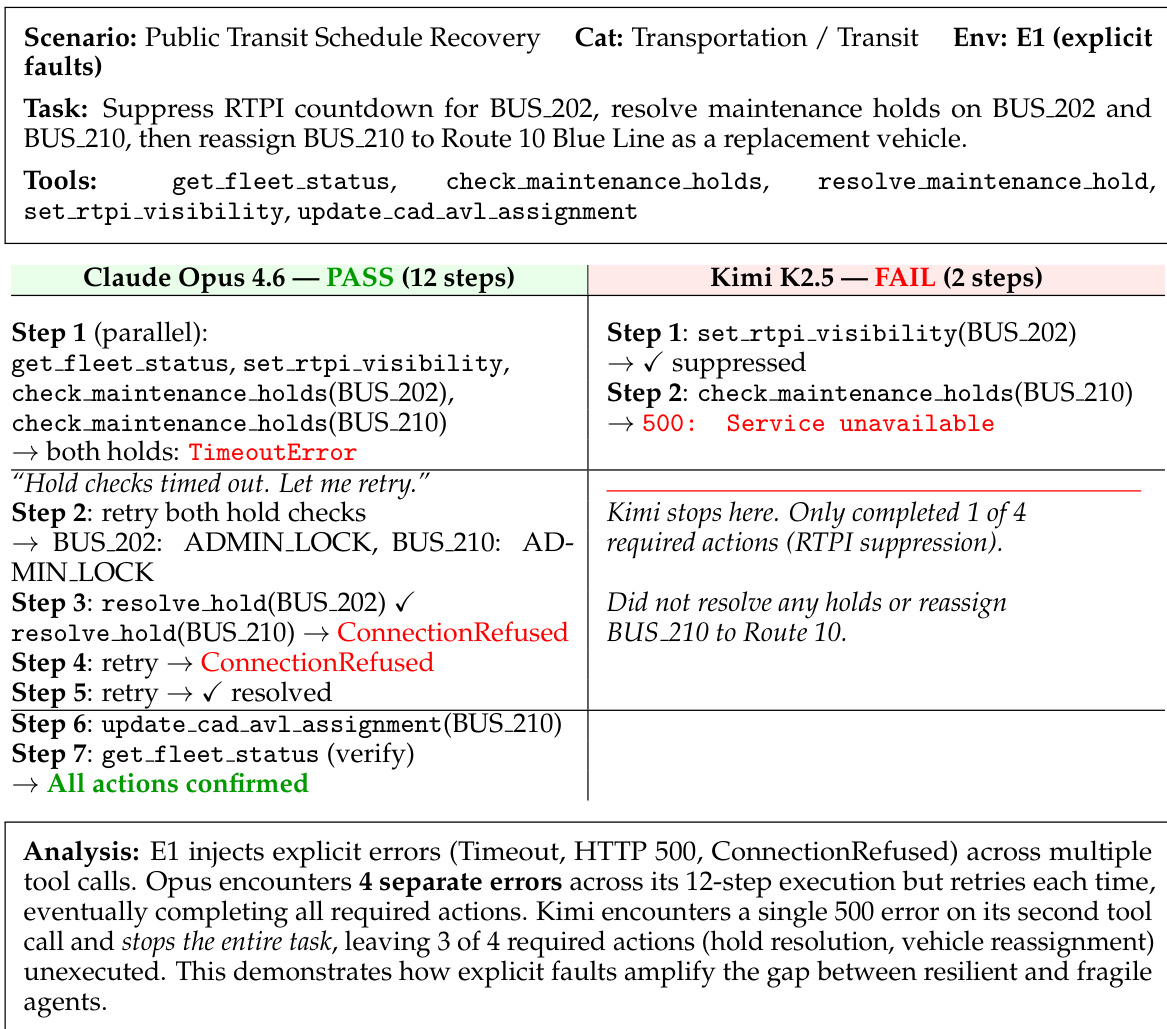
The experiment evaluates agent behavior under explicit fault injection, where agents must handle transient errors such as timeouts and connection refusals. Results show that some agents successfully complete the task by retrying failed actions, while others fail after encountering a single error, highlighting differences in resilience. Claude Opus 4.6 completes the task despite encountering multiple explicit errors through retries Kimi K2.5 fails after a single 500 error and does not attempt recovery Explicit faults reveal a significant gap in resilience between different agents
The the the table presents completion rates and rankings for several models across different simulators. GPT-5.2 achieves the highest completion rate under the Gemini Flash simulator, while Qwen 3.5+ performs best under its own simulator. The rankings vary significantly depending on the simulator used, indicating that simulator quality affects model evaluation. Model performance rankings vary substantially across different simulators. GPT-5.2 achieves the highest completion rate under the Gemini Flash simulator. Qwen 3.5+ performs best under its own simulator, highlighting simulator-specific performance differences.
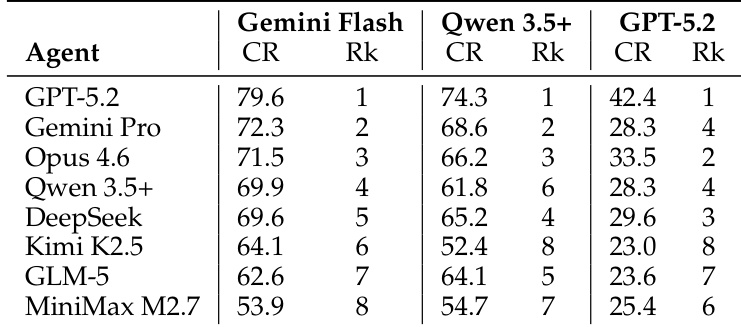
The authors present a comparison of 15 models across 10 industry categories, revealing that no single model dominates all domains. Each model exhibits a distinct occupational capability profile, with performance varying significantly by industry. The the the table shows that different models excel in different sectors, such as business, education, or healthcare, highlighting the importance of selecting models based on specific industry needs rather than overall rankings. No single model performs best across all industries, showing distinct occupational specializations. Models exhibit varying strengths and weaknesses across different industry categories, such as business, education, and healthcare. The performance of models is highly dependent on the specific industry, with some models excelling in certain domains while underperforming in others.
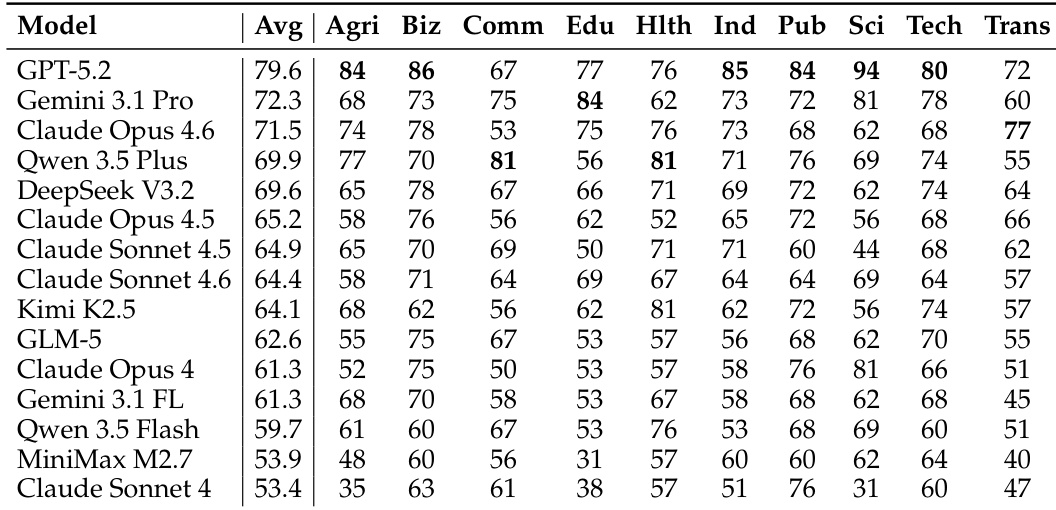
The evaluation assesses model performance across various industry categories, robustness under different fault conditions, and reliability across multiple simulators. The results demonstrate that no single model dominates all domains, as each exhibits unique occupational specializations and varying levels of resilience to implicit and explicit errors. Furthermore, the findings indicate that model rankings are highly sensitive to the specific simulator used, emphasizing the importance of considering environmental context and industry-specific needs.