Command Palette
Search for a command to run...
Attention Sink dans les Transformers : une étude sur l'utilisation, l'interprétation et l'atténuation
Attention Sink dans les Transformers : une étude sur l'utilisation, l'interprétation et l'atténuation
Résumé
En tant que traducteur professionnel spécialisé dans les domaines technologiques et scientifiques, voici la traduction de votre texte en français, respectant les standards de rigueur académique et les consignes terminologiques fournies :En tant qu'architecture fondamentale de l'apprentissage automatique moderne, les Transformers ont impulsé des progrès remarquables dans divers domaines de l'IA. Malgré leur impact transformateur, un défi persistant au sein de nombreux Transformers est l'« Attention Sink » (AS) — un phénomène où une proportion disproportionnée de l'attention se concentre sur un sous-ensemble restreint de tokens spécifiques mais non informatifs. L'AS complique l'interprétabilité, affecte significativement la dynamique de training et d'inference, et exacerbe des problèmes tels que les hallucinations. Ces dernières années, des recherches substantielles ont été consacrées à la compréhension et à l'exploitation de l'AS. Cependant, il manque encore une étude exhaustive (survey) capable de consolider systématiquement les recherches liées à l'AS et d'offrir des orientations pour les avancées futures. Pour combler cette lacune, nous présentons la première étude exhaustive sur l'AS, structurée autour de trois dimensions clés qui définissent le paysage de la recherche actuelle : l'Utilisation Fondamentale, l'Interprétation Mécaniste et l'Atténuation Stratégique. Notre travail apporte une contribution pivotale en clarifiant les concepts clés et en guidant les chercheurs à travers l'évolution et les tendances du domaine. Nous envisageons cette étude comme une ressource de référence, permettant aux chercheurs et aux praticiens de gérer efficacement l'AS au sein du paradigme actuel des Transformers, tout en inspirant simultanément des avancées innovantes pour la prochaine génération de Transformers. La liste des articles de ce travail est disponible à l'adresse suivante : https://github.com/ZunhaiSu/Awesome-Attention-Sink.
One-sentence Summary
This first comprehensive survey on Attention Sink in Transformers systematically categorizes research into fundamental utilization, mechanistic interpretation, and strategic mitigation to clarify key concepts and provide a framework for managing uninformative token focus to improve training, inference, and interpretability.
Key Contributions
- This work presents the first comprehensive survey on Attention Sink (AS) in Transformer architectures by systematically synthesizing over 180 studies. The review is structured around three key dimensions: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation.
- The paper provides a detailed analysis of how AS influences training dynamics, model interpretability, and inference efficiency across various architectures. It clarifies key concepts and examines how empirical utilization strategies, mechanistic studies, and mitigation techniques can be leveraged to improve model performance and robustness.
- The survey establishes a foundational framework for understanding AS and identifies critical future research directions. These include the development of standardized benchmarks for mitigation, the exploration of cross-architecture and cross-modal transfer, and the investigation of synergistic integration between multiple AS handling techniques.
Introduction
Transformers serve as the foundational architecture for modern AI, yet they frequently exhibit Attention Sink (AS), a phenomenon where disproportionate attention concentrates on a small subset of uninformative tokens. This behavior complicates model interpretability, destabilizes training and inference, and contributes to issues like hallucinations and quantization errors. While recent studies have explored various ways to exploit or reduce AS, the existing literature remains fragmented, leaving researchers without a unified reference to guide development. The authors leverage a comprehensive review of over 180 studies to present the first systematic survey of the field. They organize the research into a novel taxonomy based on three dimensions: fundamental utilization, mechanistic interpretation, and strategic mitigation.
Method
The foundational architecture for modern large language models (LLMs) is derived from the Transformer, which operates on an encoder-decoder framework. As shown in the figure below, a standard Transformer block consists of two primary components: a multi-head self-attention (MHSA) module and a position-wise feed-forward network (FFN). The MHSA mechanism enables the model to capture long-range global dependencies without the inductive bias of sequential processing. For an input sequence X∈RN×D, queries Q, keys K, and values V are obtained via linear projections: Q=XWQ, K=XWK, V=XWV, where WQ,WK,WV∈RD×dk. Attention is computed as Attention(Q,K,V)=Softmax(dkQKT)V. The FFN is applied to each position independently and is defined as FFN(x)=σ(xW1+b1)W2+b2. To stabilize training and mitigate the vanishing gradient problem, each sub-layer incorporates a residual connection followed by layer normalization (LayerNorm): Xout=LayerNorm(X+SubLayer(X)).
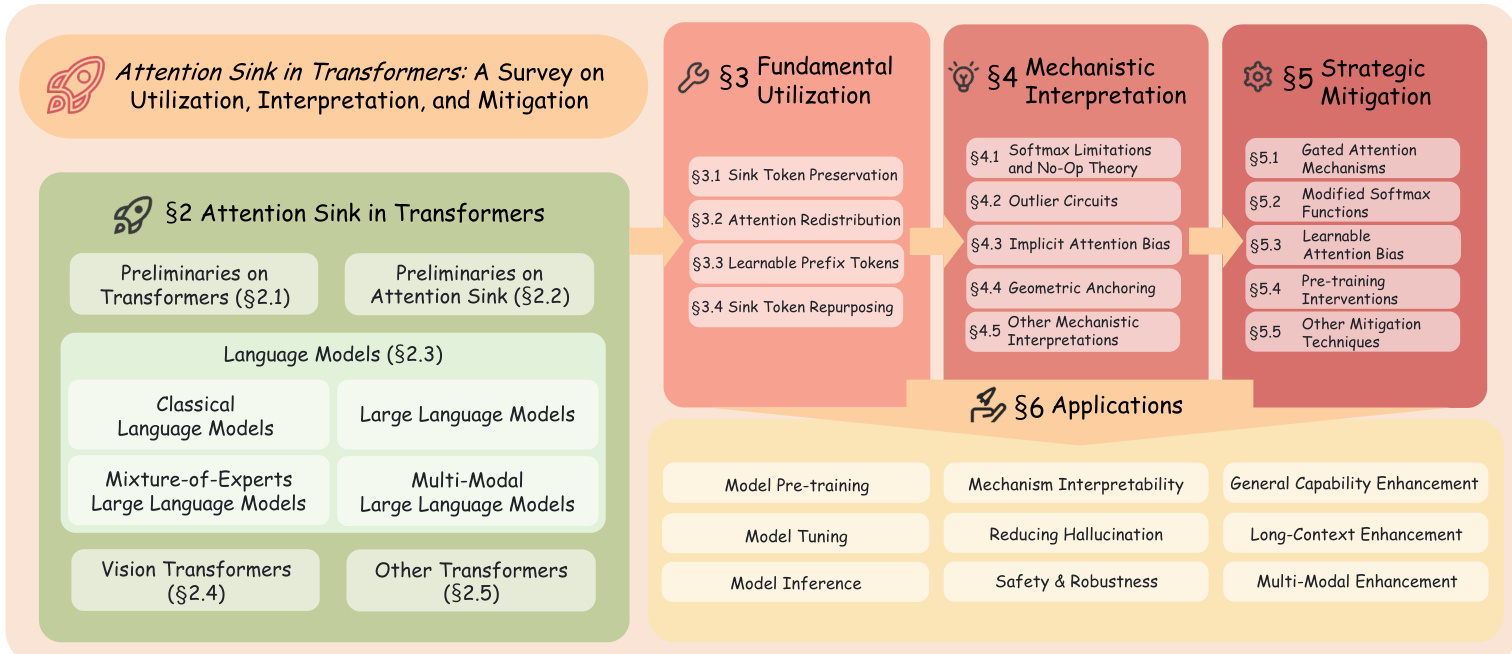
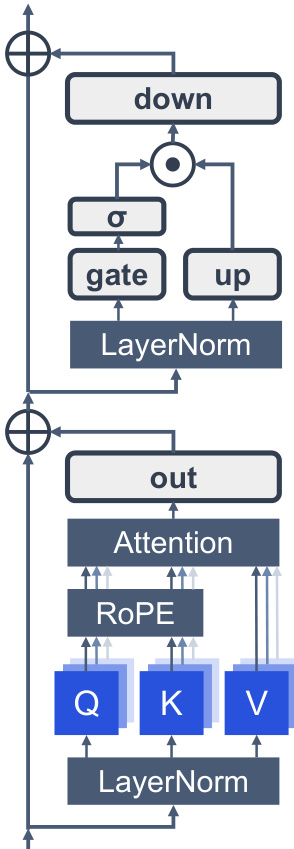
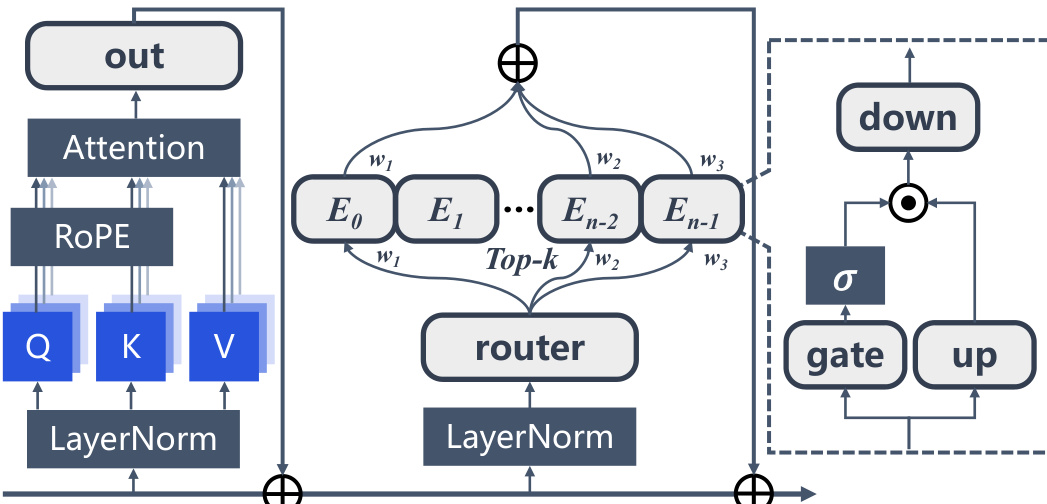
Modern LLMs are a specialized adaptation of the Transformer, fundamentally rooted in the decoder-only configuration. The structural layout of these models is illustrated in Figure 7. A defining constraint inherited from the decoder-only architecture is the causal masking mechanism, which ensures that each query vector qi at position i can only attend to preceding key vectors kj where j≤i. Formally, the attention pattern is defined as Attention(Q,K,V)=softmax(dkQK⊤+M)V, where M is the causal mask with Mij=−∞ for j>i and 0 otherwise. In this setting, only the initial tokens are visible to the entire sequence, making them the most stable candidates for attention offloading. Beyond causal masking, contemporary LLMs incorporate a suite of architectural refinements that collectively enhance training stability, model expressivity, and inference efficiency. For normalization, pre-normalization with Root Mean Square Layer Normalization (RMSNorm) has largely replaced the original post-LN design, mitigating gradient variance and enabling more stable training at scale. The feed-forward network has been upgraded from the original two-layer MLP to Gated Linear Units (GLU), with SwiGLU emerging as the predominant variant due to its superior trade-off between expressivity and computational cost. For positional encoding, Rotary Positional Embeddings (RoPE) encode relative position information through rotation matrices, offering improved length extrapolation capabilities compared to absolute or learnable positional embeddings.
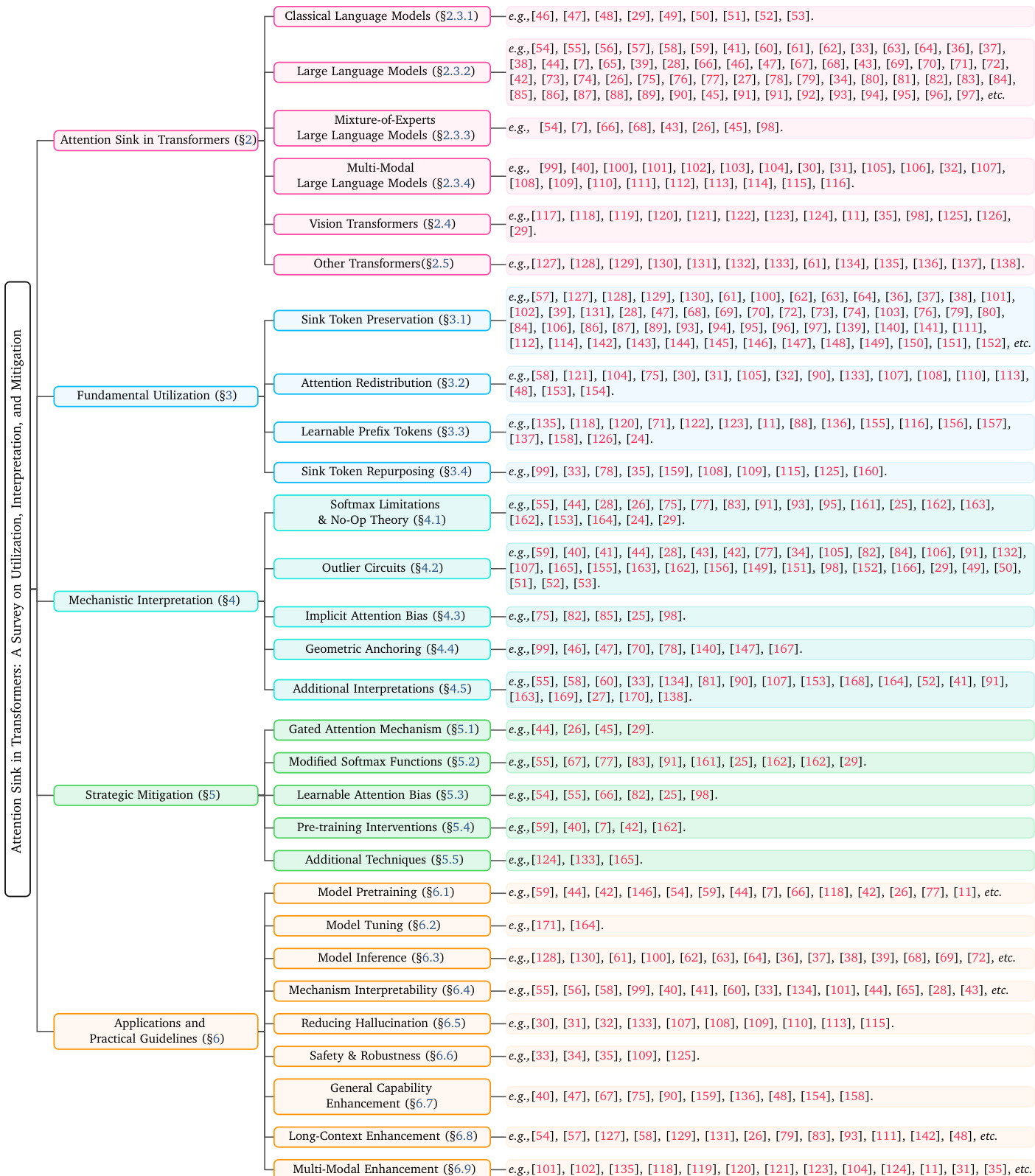
Mixture-of-Experts (MoE) LLMs extend the vanilla Transformer architecture by substituting the static feed-forward network with a sparse MoE layer, as illustrated in Figure 8. The hidden representation after multi-head self-attention, Hl′∈Rn×d, passes through Layer Normalization and is fed into the MoE layer. A router network determines which experts to activate via the weight matrix WG∈Rd×E, where the routing weights G∈Rn×E are computed as G=softmax(Hl′WG). Sparse activation of the experts is achieved by selecting the top-k routing weights for each input token, producing the MoE layer output: MoE(Hl′)=∑i∈Top−k(Gi)Gji⋅FFN(LNmoe(Hjl′)),∀j=1…n. In dense LLMs, AS emerges as a stable pattern anchored to the initial tokens. In MoE LLMs, the sparse activation mechanism dynamically routes different tokens to distinct experts during inference. The interaction between the AS mechanism and the MoE architecture gives rise to unique AS manifestations in MoE LLMs where the distribution of AS may influence or be influenced by expert routing decisions.
Multi-modal LLMs (MLLMs) extend the standard Transformer architecture by integrating a vision encoder with a causal LLM backbone via a cross-modal connector. Formally, given an input image x∈RH×W×C, the vision encoder first extracts a sequence of visual tokens: V={v1,v2,…,vN}=fvision(x), where N denotes the number of patches and fvision represents the vision encoder. These visual tokens are then projected via a cross-modal connector P to align with the LLM's embedding space: V′=P(V)={v1′,v2′,…,vN′}, where vi′∈RDllm. The projected visual tokens V′ are concatenated with textual tokens T={t1,…,tM} to form the full input sequence S=[V′,T], which is subsequently processed by the causal LLM. Unlike text-only Transformers, MLLMs operate over heterogeneous receptive fields, requiring textual queries to attend to information-rich visual patches that are inherently non-causal. This multi-modal integration forces the attention mechanism to reconcile magnitude or variance disparities between visual and textual embeddings, directly influencing the emergence and spatial distribution of AS during multimodal inference.
Vision Transformer (ViT) introduces a patch-based tokenization mechanism to adapt the Transformer for image recognition. Given an image x∈RH×W×C, it is first partitioned into a grid of N=HW/P2 patches, where (P,P) is the resolution of each patch, where each patch pi∈RP2C corresponds to a spatial segment of the image. Each patch is then flattened and linearly projected into a D-dimensional embedding: ei=Epi, where E∈RD×(P2C) is a learnable projection matrix. The resulting sequence of N patch embeddings, together with a learnable [CLS] token ecls, serves as input to the Transformer encoder. Building upon the core ViT architecture, subsequent works have extended its capabilities through novel training paradigms. This architectural choice has direct implications for AS behavior: without the forced causality that concentrates attention on initial tokens, AS in ViT is not constrained to the sequence start but may instead emerge on background patches or low-semantic regions that serve as structurally stable anchoring points across the image.
Experiment
The Implicit Attention Bias framework is evaluated through causal interventions and visualization across various architectures, including LLMs and ViTs, to validate its role in explaining attention sinks. The results demonstrate that the Softmax sum-to-one constraint induces a fixed, input-independent bias that accounts for the disproportionate attention received by sink tokens. While the framework provides a unified explanation for this phenomenon, the underlying training dynamics and the relationships between different forms of implicit bias remain areas for future investigation.