Command Palette
Search for a command to run...
Transformers à boucles élastiques pour la génération visuelle
Transformers à boucles élastiques pour la génération visuelle
Résumé
C'est entendu. Je suis prêt à commencer. Veuillez me transmettre le texte anglais que vous souhaitez faire traduire. Je m'assurerai de respecter scrupuleusement vos consignes, à savoir :Précision terminologique : Utilisation des termes techniques exacts et respect de la nomenclature scientifique.Fluidité rédactionnelle : Adaptation de la syntaxe pour une lecture naturelle en français, en évitant le calque de l'anglais.Registre formel : Adoption d'un style journalistique ou académique rigoureux et objectif.Gestion des termes spécifiques : Maintien des termes tels que LLM, Agent, token, Transformer, Diffusion, prompt, pipeline, benchmark, etc., en anglais, conformément à vos instructions.J'attends votre texte.
One-sentence Summary
The authors propose Elastic Looped Transformers, a novel architecture for visual generation that utilizes recurrently applied transformer layers to enable variable depth through elastic looping, thereby optimizing the trade-off between inference speed and generation quality compared to traditional fixed-depth architectures.
Key Contributions
- The paper introduces the Elastic Looped Transformers (ELT) framework, which aligns model architecture with the progressive refinement process used in masked generative and diffusion models.
- This framework implements the model as a series of recurrent, weight-shared transformer blocks to enable recursive refinement within each individual sampling step.
- The ELT architecture provides a test-time compute lever that allows for a flexible trade-off between inference speed and generation quality through any-time inference capabilities.
Introduction
Visual generative models typically rely on deep stacks of unique transformer layers to achieve high fidelity, which leads to a large memory footprint and high parameter counts. While recurrent architectures offer a way to increase computational capacity without increasing memory usage, standard looped transformers often suffer from unstable intermediate representations that only become coherent at a specific, fixed loop count. The authors introduce Elastic Looped Transformers (ELT), a parameter-efficient framework that uses weight-shared transformer blocks to enable high-quality image and video synthesis. To solve the instability of intermediate states, they propose Intra-Loop Self Distillation (ILSD), a training method that distills the teacher configuration into intermediate student configurations. This approach allows for Any-Time inference, where a single model can dynamically trade off computational cost and generation quality by adjusting the number of loops during inference.
Method
The authors leverage a looping mechanism to construct a transformer architecture that decouples model size from computational depth, enabling efficient scaling of representational capacity. The core design consists of a composite block gΘ(x) formed by N unique transformer layers with parameters Θ={θ1,θ2,…,θN}, applied sequentially. This block is then looped L times within a single sampling or denoising step, resulting in an effective depth of N×L while reusing the same set of parameters Θ. This approach significantly reduces the number of unique parameters compared to a standard transformer of equivalent depth, thereby enhancing parameter efficiency. The effective transformation for a N×L configuration is expressed as F(N,L)(x)=gΘL(x), where the block gΘ is applied L times. This architecture allows for high throughput and flexible computation, as the model can be executed for a variable number of loops during inference without retraining.
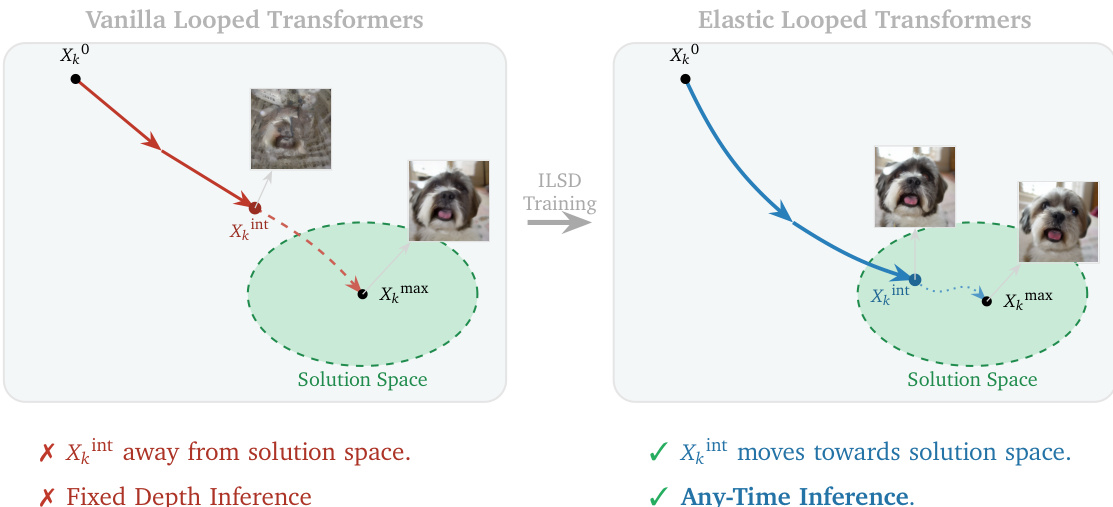
As shown in the figure above, the proposed Elastic Looped Transformers (ELT) framework introduces a novel training strategy called Intra-Loop Self Distillation (ILSD) to improve the quality of intermediate representations during the looping process. In a standard looped transformer, the model is typically trained only for its final output after Lmax iterations, which can result in suboptimal representations at intermediate steps. ILSD addresses this by treating the full-depth model as an internal teacher and the shallower model as a student. The shared parameters Θ are optimized to ensure that the intermediate outputs at any loop count Lint are useful and consistent with the final output at Lmax. This is achieved by training the model with a dual-path system where both a teacher path executing Lmax loops and a stochastic student path exiting at a randomly sampled intermediate loop Lint are used. The student path receives supervision from both ground-truth labels and the teacher's predictions, encouraging the model to learn a robust, incremental transformation.
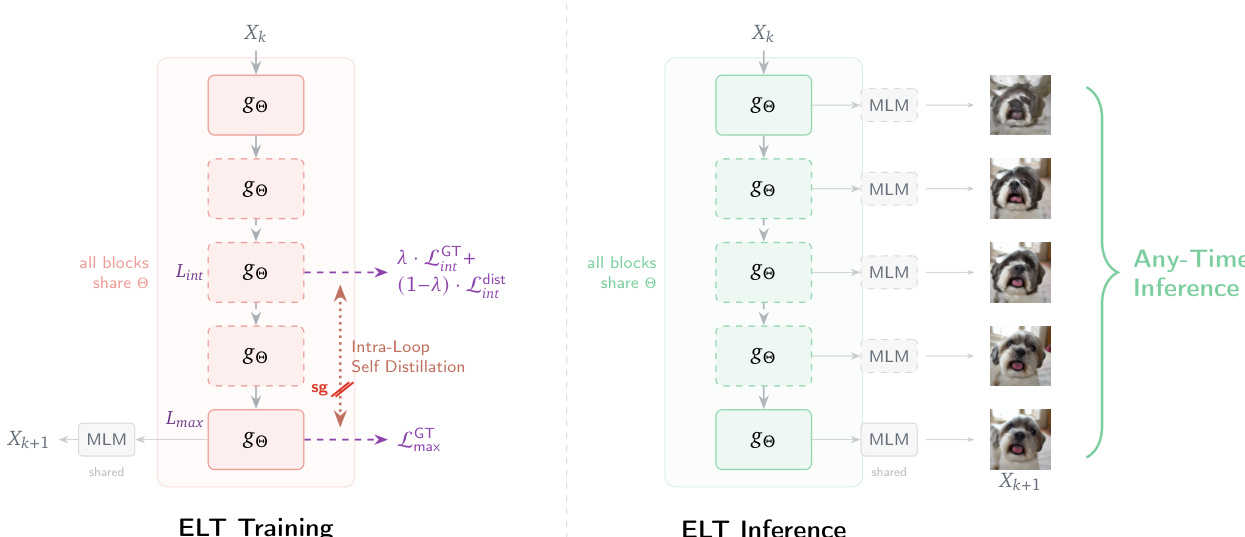
The training process is formalized with a joint loss function LΘILSD that combines three components: the ground-truth loss for the teacher output F(N,Lmax)(x), the ground-truth loss for the student output F(N,Lint)(x), and the distillation loss between the student output and the stop-gradient of the teacher output. The distillation loss is computed using a cross-entropy or MSE loss, depending on the task, and is weighted by a hyperparameter λ that linearly decays from 1 to 0 during training. This curriculum learning approach initially anchors the student to reliable ground-truth labels and gradually shifts to mimicking the teacher's predictions as the model matures. The gradients from both computational paths update the shared set of block parameters Θ, providing a richer training signal that prevents the model from learning shortcuts and promotes generalization to lower depths.
The inference process for ELT is designed to support flexible, anytime inference. Given an input and a dynamic compute budget L, the model performs recursive refinement using the shared parameters gΘ for L steps. The output is generated by passing the final state through a prediction head. This allows for dynamic adjustment of the number of loops at inference time, enabling the model to adapt its computational cost to the desired level of accuracy without retraining. The architecture supports early exits and elastic inference, making it suitable for applications with varying computational constraints.
Experiment
The researchers evaluated Elastic Looped Transformers (ELT) using masked generative transformers and diffusion transformers for class-conditional image generation on ImageNet and video generation on UCF-101. The experiments validate that ELT achieves high-fidelity results with significantly fewer parameters than baseline models while providing a flexible trade-off between generation quality and inference speed. Through the use of Intra-Loop Self Distillation, the approach enables any-time inference, allowing a single trained model to maintain stable performance across varying computational budgets.
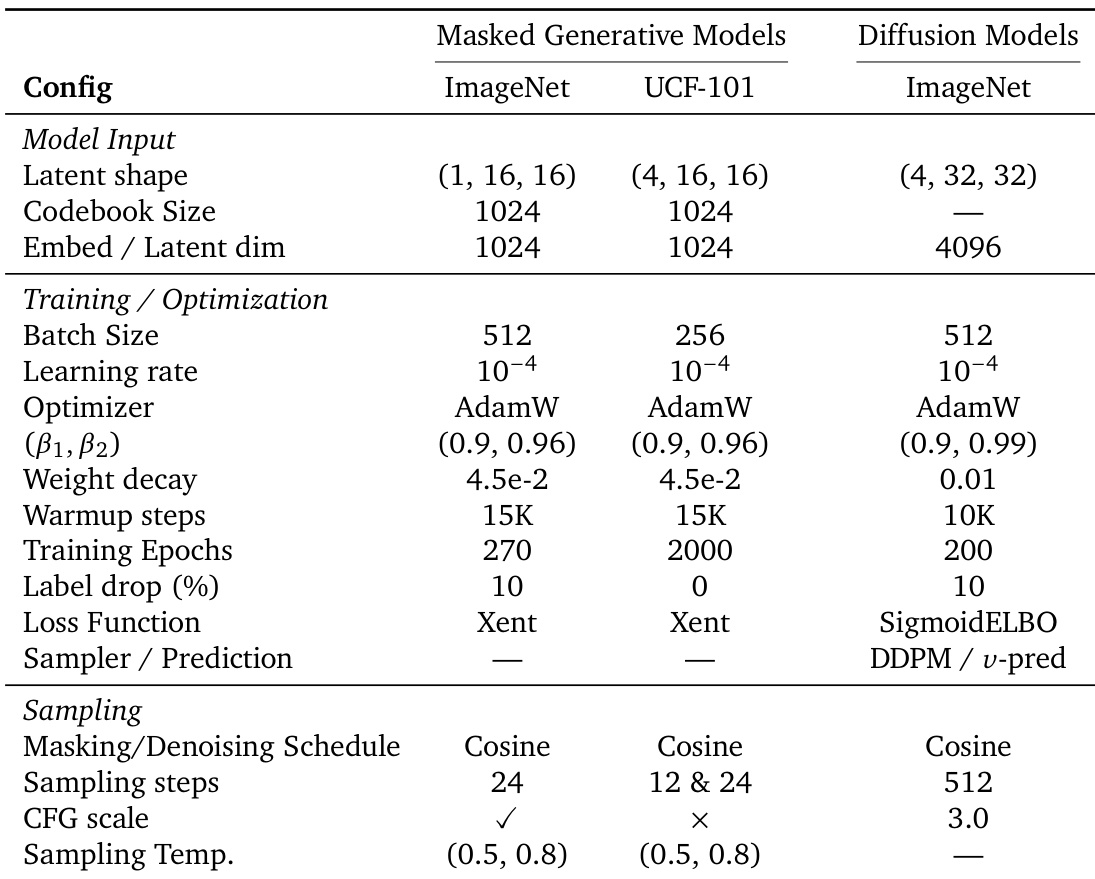
The the the table outlines the training and sampling configurations for masked generative and diffusion models on ImageNet and UCF-101 datasets. It specifies differences in input dimensions, optimization parameters, and sampling strategies between the two model types. Masked generative models use a smaller batch size and fewer training epochs compared to diffusion models. Diffusion models employ a higher number of sampling steps and a different loss function than masked generative models. Both model types use AdamW optimizer but differ in learning rates, weight decay, and sampling schedules.
The the the table provides architectural specifications for different model scales, showing that both Small and Large models have the same model dimension and number of attention heads, but differ in the number of layers. The Large model has twice the number of layers compared to the Small model. Small and Large models share the same model dimension and number of attention heads. The Large model has twice as many layers as the Small model. Model scaling is achieved by increasing the number of layers while keeping other dimensions constant.

The authors compare different models for class-conditional image generation on ImageNet, evaluating their performance in terms of FID and parameter count. Results show that ELT achieves competitive or better FID scores with significantly fewer parameters compared to DiT baselines, demonstrating parameter efficiency and effective scaling through looped inference. ELT achieves lower FID than DiT with fewer parameters ELT maintains high performance across different inference loop configurations ELT demonstrates parameter efficiency compared to standard DiT models
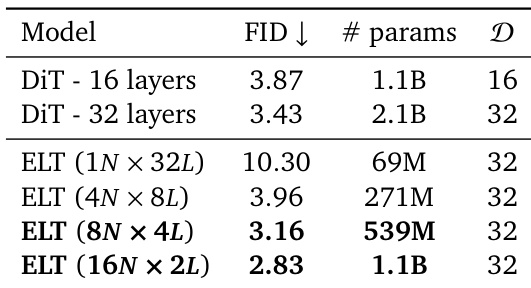
The authors compare their proposed ELT models with various baselines on ImageNet, demonstrating that ELT achieves competitive performance with significantly fewer parameters and computational cost. The results show that ELT maintains high image quality across different inference configurations, highlighting its parameter efficiency and flexibility. ELT models achieve similar performance to baselines with substantially fewer parameters and inference compute. ELT maintains consistent quality across varying inference loop counts, enabling flexible trade-offs between speed and quality. The proposed approach outperforms baselines in parameter efficiency while achieving competitive FID and IS scores.
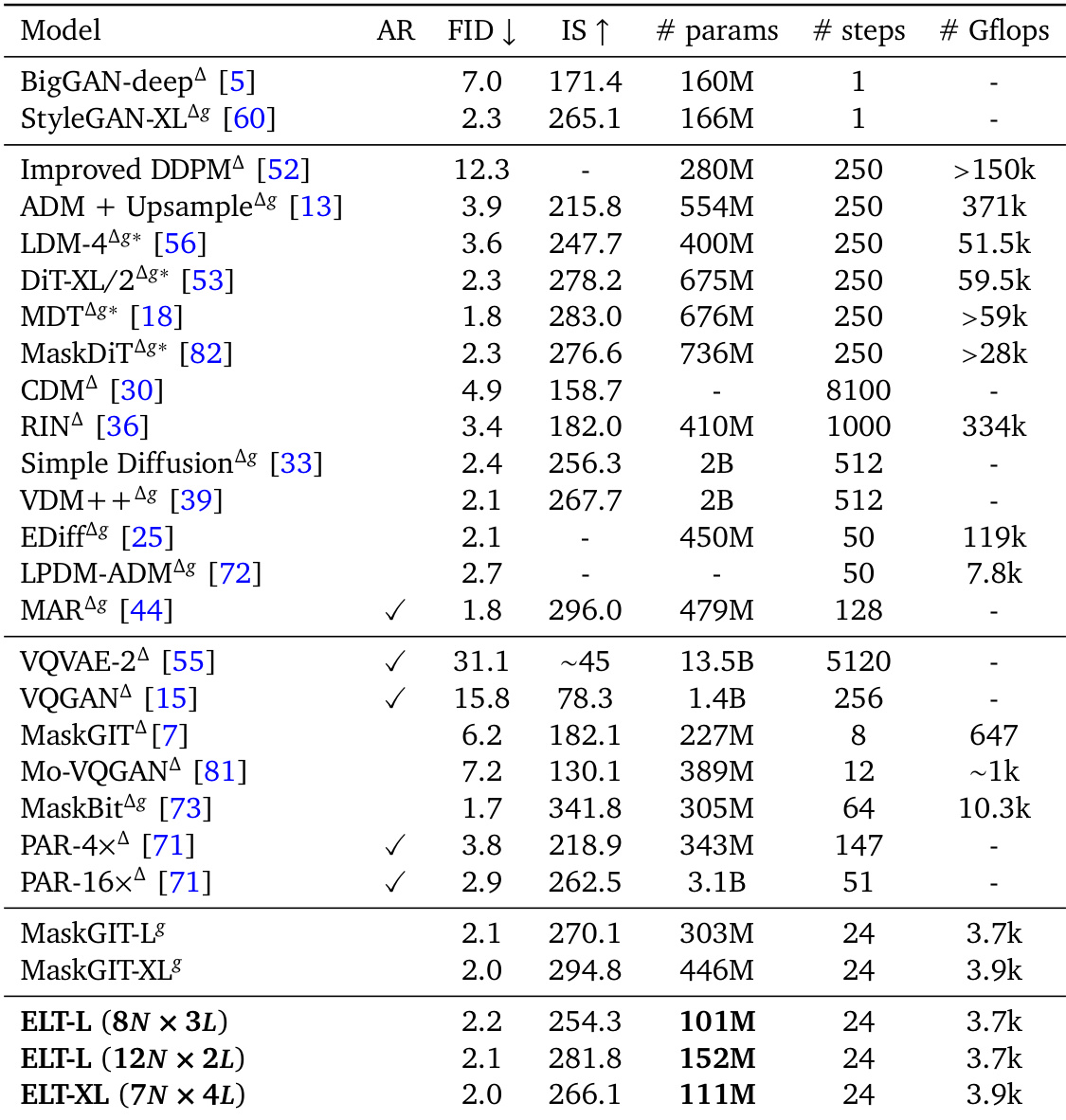
The the the table presents throughput ratios for different ELT model configurations, showing that larger models achieve higher throughput relative to their baselines. The results indicate that ELT's parameter efficiency leads to improved inference speed, with the highest gain observed for the largest model scale. Larger ELT models exhibit higher throughput ratios compared to smaller models. The throughput improvement is attributed to reduced memory transfers due to shared parameters. The highest throughput ratio is achieved by the largest model configuration.
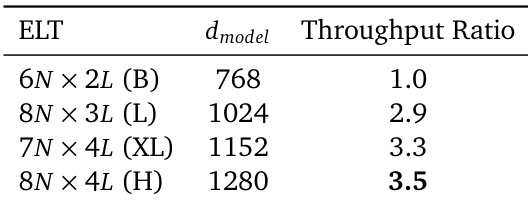
The experiments evaluate various model scales and training configurations for masked generative and diffusion models on the ImageNet and UCF-101 datasets. The results demonstrate that the proposed ELT approach achieves competitive image generation quality while maintaining significantly higher parameter efficiency and lower computational costs than standard baselines. Furthermore, the model exhibits improved inference throughput, particularly at larger scales, due to reduced memory transfers from shared parameters.