Command Palette
Search for a command to run...
SPPO : PPO au niveau de la séquence pour les tâches de raisonnement à long horizon (Long-Horizon Reasoning)
SPPO : PPO au niveau de la séquence pour les tâches de raisonnement à long horizon (Long-Horizon Reasoning)
Tianyi Wang Yixia Li Long Li Yibiao Chen Shaohan Huang Yun Chen Peng Li Yang Liu Guanhua Chen
Résumé
Voici la traduction de votre texte en français, réalisée selon les standards de la rédaction scientifique et technologique :L'algorithme Proximal Policy Optimization (PPO) est au cœur de l'alignement des Large Language Models (LLMs) sur des tâches de raisonnement impliquant des récompenses vérifiables. Cependant, le PPO standard au niveau du token peine dans ce contexte en raison de l'instabilité de l'assignation de crédit temporel (temporal credit assignment) sur de longs horizons de Chain-of-Thought (CoT), ainsi que du coût de mémoire prohibitif du modèle de valeur (value model). Bien que des alternatives sans critique (critic-free), telles que le GRPO, atténuent ces problèmes, elles engendrent un surcoût computationnel significatif en nécessitant plusieurs échantillons pour l'estimation de la référence (baseline estimation), ce qui limite sévèrement le débit d'entraînement (training throughput). Dans cet article, nous introduisons le Sequence-Level PPO (SPPO), un algorithme scalable qui harmonise l'efficacité d'échantillonnage du PPO avec la stabilité des mises à jour basées sur le résultat (outcome-based updates). Le SPPO reformule le processus de raisonnement comme un problème de bandit contextuel au niveau de la séquence (Sequence-Level Contextual Bandit problem), en employant une fonction de valeur scalaire découplée pour dériver des signaux d'avantage à faible variance sans nécessiter de multi-échantillonnage. Des expérimentations approfondies sur des benchmarks mathématiques démontrent que le SPPO surpasse significativement le PPO standard et égale les performances des méthodes de groupe gourmandes en calcul, offrant ainsi un framework économe en ressources pour l'alignement des LLMs de raisonnement.
One-sentence Summary
The authors propose SPPO, a scalable sequence-level reinforcement learning algorithm that reformulates long-horizon reasoning as a contextual bandit problem and employs a decoupled scalar value function to achieve low-variance advantage signals without the multi-sampling overhead of group-based methods, significantly outperforming standard PPO on mathematical benchmarks.
Key Contributions
- The paper introduces Sequence-Level PPO (SPPO), an algorithm that reformulates the reasoning process as a Sequence-Level Contextual Bandit problem to harmonize sample efficiency with the stability of outcome-based updates.
- This work implements a Decoupled Critic strategy that uses a lightweight critic to align a larger policy, which reduces memory usage by 12.8% while enabling high-throughput single-sample updates.
- Extensive evaluations on mathematical benchmarks such as AIME, AMC, and MATH demonstrate that SPPO matches the performance of group-based methods like GRPO while achieving a 5.9x training speedup.
Introduction
Aligning Large Language Models (LLMs) for complex reasoning tasks requires Reinforcement Learning with Verifiable Rewards (RLVR) to ensure logical correctness. While standard token-level Proximal Policy Optimization (PPO) is widely used, it suffers from unstable temporal credit assignment and high memory costs when dealing with long Chain-of-Thought horizons. Conversely, critic-free methods like Group Relative Policy Optimization (GRPO) reduce bias but introduce high variance and significant computational overhead because they require sampling multiple responses per prompt to estimate baselines. The authors leverage a new perspective that treats reasoning as a Sequence-Level Contextual Bandit problem rather than a multi-step Markov Decision Process. They introduce Sequence-Level PPO (SPPO), which uses a learned scalar value function to provide stable advantage signals. This approach allows for high-throughput single-sample updates, matching the performance of group-based methods while achieving a significant training speedup.
Method
The authors leverage a sequence-level optimization framework to address the challenges of credit assignment in long-horizon reasoning tasks. The proposed method, SPPO, reformulates the standard token-level Markov Decision Process (MDP) into a Sequence-Level Contextual Bandit (SL-CB) setting, where the entire generated response sequence is treated as a single atomic action. This shift fundamentally alters the policy optimization process by eliminating the need for a token-level critic that attempts to estimate future returns from intermediate states. Instead, SPPO introduces a scalar value model Vϕ(sp), which predicts the probability of success for a given prompt sp. This value function is trained using Binary Cross-Entropy (BCE) loss to ensure it serves as a calibrated baseline for the advantage calculation.
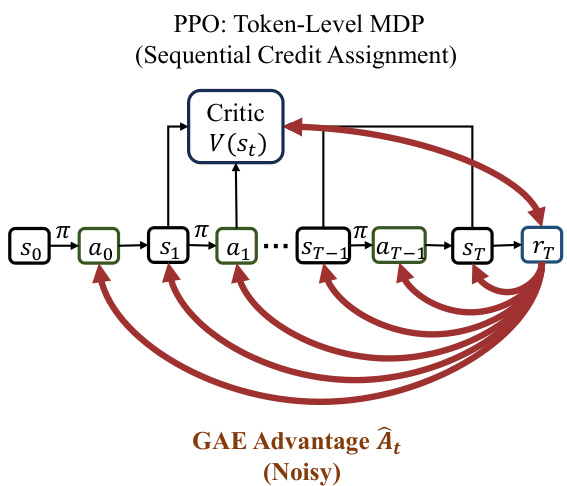
As shown in the figure below, the standard PPO framework operates within a token-level MDP, where the policy π generates actions at sequentially from states st. A critic V(st) estimates the value of each intermediate state, and the advantage A^t is computed via Generalized Advantage Estimation (GAE), which sums discounted temporal difference errors. This mechanism leads to noisy, position-dependent credit assignment, as the advantage signal is heavily influenced by the token's position in the sequence, causing the "tail effect" where rewards are only propagated effectively near the end of the generation.
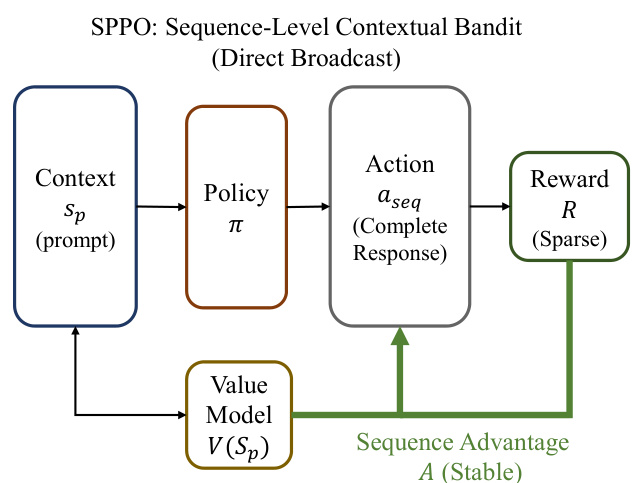
In contrast, the SPPO framework, as illustrated in the figure below, operates on the prompt sp as the sole context. The policy π outputs a complete response sequence aseq, which is then evaluated by a sparse reward function R to determine its correctness. The advantage is computed as a simple scalar difference A(sp,a)=R−Vϕ(sp), which is then directly broadcast to every token within the generated sequence. This sequence-level advantage A is stable and independent of the response length, effectively solving the temporal credit assignment problem by reinforcing or penalizing the entire chain of actions uniformly based on the final outcome. The policy optimization objective adapts the PPO clipped surrogate objective but applies the single sequence-level advantage to all tokens, ensuring that the policy update is aligned with the holistic success or failure of the reasoning process.
Experiment
The evaluation compares the proposed SPPO algorithm against several baselines, including standard PPO, GRPO, RLOO, and ReMax, using mathematical reasoning benchmarks and reinforcement learning control tasks. Results demonstrate that SPPO achieves superior performance and faster convergence by utilizing a sequence-level contextual bandit formulation that effectively resolves credit assignment issues in sparse-reward settings. Furthermore, the study validates that decoupling the critic size from the policy significantly reduces memory overhead without sacrificing accuracy, making large-scale reasoning model alignment more resource-efficient.
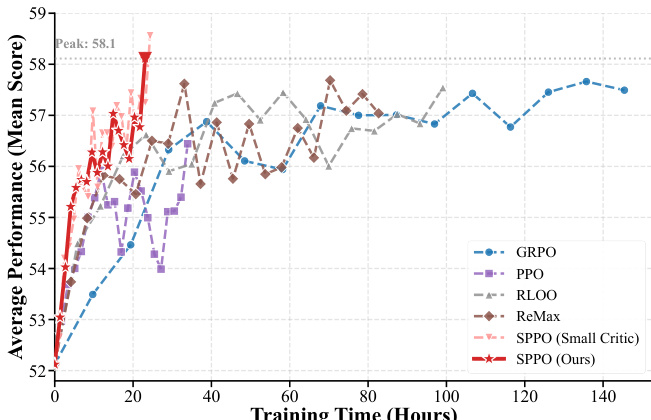
The results show that SPPO achieves higher average performance and faster convergence compared to baseline methods. The approach demonstrates improved training efficiency, with SPPO reaching peak performance more quickly than other algorithms. SPPO outperforms all baselines in average performance and convergence speed SPPO achieves peak performance significantly faster than group-based methods The small critic variant of SPPO maintains high performance while reducing computational overhead
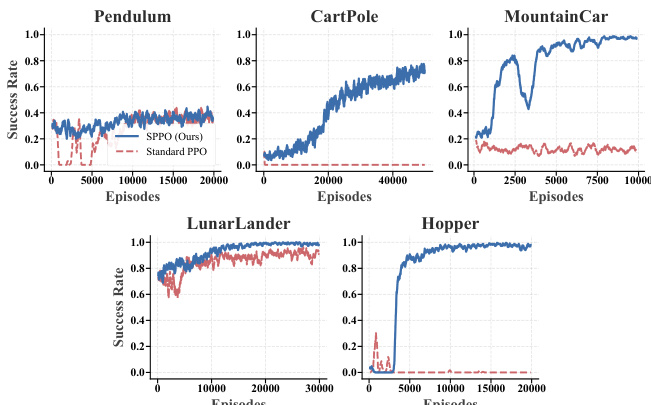
The authors evaluate SPPO against Standard PPO across five control tasks with sparse rewards. Results show SPPO consistently converges and outperforms Standard PPO, particularly in long-horizon tasks where the baseline fails. SPPO achieves robust convergence across all control tasks, while Standard PPO fails in complex environments. In long-horizon tasks, SPPO successfully solves problems where Standard PPO remains at low success rates. SPPO demonstrates superior sample efficiency, rapidly improving in precision tasks like CartPole.
The the the table compares the performance of various reinforcement learning methods on mathematical reasoning benchmarks. SPPO consistently achieves higher average scores than baselines, with the best results observed when using a smaller critic model. The authors use a sequence-level advantage estimation method to improve training stability and efficiency. SPPO outperforms all baselines on both model scales, achieving the highest average score. Using a smaller critic model improves performance and reduces memory usage while maintaining effectiveness. Standard PPO shows limited improvement over the base model, indicating instability in sparse-reward settings.
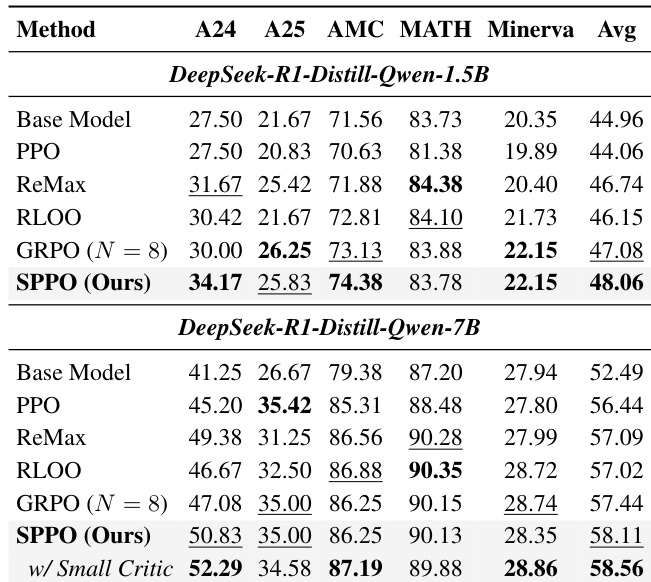
SPPO is evaluated against Standard PPO and other baseline methods across control tasks with sparse rewards and mathematical reasoning benchmarks to validate its training efficiency and stability. The results demonstrate that SPPO achieves superior average performance and faster convergence, particularly in complex, long-horizon environments where baseline methods often fail. Additionally, employing a smaller critic model enhances performance and reduces computational overhead without sacrificing effectiveness.