Command Palette
Search for a command to run...
Rapport technique d'EXAONE 4.5
Rapport technique d'EXAONE 4.5
Résumé
Ce rapport technique présente EXAONE 4.5, le premier modèle vision-langage à poids ouverts (open-weight) publié par LG AI Research. L'architecture d'EXAONE 4.5 repose sur l'intégration d'un encodeur visuel dédié au framework existant d'EXAONE 4.0, permettant un pré-entraînement multimodal natif sur les modalités visuelles et textuelles.Le modèle a été entraîné sur des données à grande échelle avec une sélection rigoureuse (careful curation), en mettant particulièrement l'accent sur des corpus centrés sur les documents, en alignement avec les domaines d'application stratégiques de LG. Cette conception ciblée des données permet des gains de performance substantiels dans la compréhension de documents et les tâches connexes, tout en offrant des améliorations généralisées des capacités linguistiques globales.EXAONE 4.5 étend la longueur de contexte jusqu'à 256K tokens, facilitant ainsi le raisonnement sur long contexte (long-context reasoning) et les cas d'usage à l'échelle de l'entreprise. Les évaluations comparatives démontrent qu'EXAONE 4.5 atteint des performances compétitives sur les benchmarks généraux, tout en surpassant les modèles de pointe (state-of-the-art) de taille similaire en matière de compréhension de documents et de raisonnement contextuel en langue coréenne.Dans le cadre des efforts continus de LG pour un déploiement industriel concret, EXAONE 4.5 est conçu pour être étendu de manière continue à de nouveaux domaines et scénarios d'application, afin de faire progresser l'IA pour une vie meilleure (AI for a better life).
One-sentence Summary
LG AI Research introduces EXAONE 4.5, an open-weight vision language model that integrates a dedicated visual encoder into the EXAONE 4.0 framework for native multimodal pretraining and achieves superior performance in document understanding and Korean contextual reasoning through curated document-centric corpora, supporting six languages with a 256K token context window.
Key Contributions
- The paper introduces EXAONE 4.5, an open-weight vision language model that integrates a 2B-parameter visual encoder into the EXAONE 4.0 framework to enable native multimodal pretraining.
- This work implements architectural innovations including Grouped Query Attention (GQA) in the vision encoder, 2D Rotary Positional Embedding (RoPE), and a Multi-Token Prediction (MTP) module to balance computational efficiency with model capacity.
- The model achieves a stable context length of 256K tokens through direct embedding during the supervised fine-tuning stage and demonstrates state-of-the-art performance in document understanding, mathematical reasoning, and Korean contextual reasoning.
Introduction
As industrial AI shifts toward agentic workflows, there is an increasing need for models that can bridge the gap between advanced linguistic reasoning and visual perception. While previous iterations of the EXAONE series focused on text-based reasoning and mathematical tasks, they lacked the multimodal capabilities required for complex industrial applications like manufacturing quality control or technical blueprint analysis. The authors address this by introducing EXAONE 4.5, LG's first open-weight vision-language model. They integrate a 1.2B parameter vision encoder into the existing 32B EXAONE 4.0 framework to enable native multimodal pretraining. This architecture, combined with a focus on document-centric corpora and an extended 256K token context length, allows the model to achieve state-of-the-art performance in document understanding and Korean contextual reasoning.
Dataset
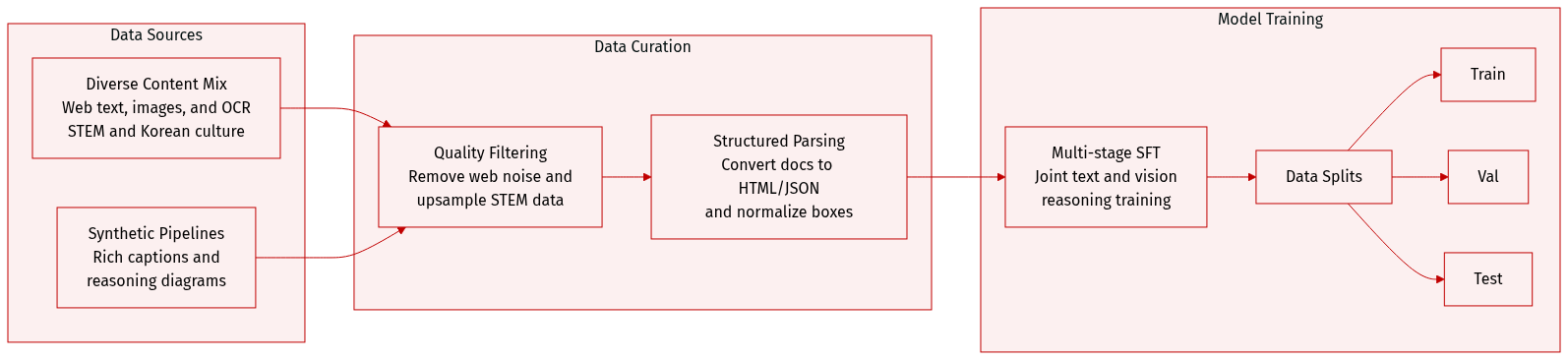
The authors construct a diverse pre-training and supervised fine-tuning (SFT) dataset designed to enhance multimodal reasoning, document understanding, and cultural nuance. The dataset composition and processing details are as follows:
-
Dataset Composition and Sources
- Image Caption Data: Primarily Korean-English bilingual pairs. The authors use a synthetic captioning pipeline to transform noisy web captions into semantically rich descriptions, prioritizing entity diversity and visual complexity.
- Interleaved Image-Text Data: A massive corpus of open-source and in-house web content.
- OCR and Documents: A mix of English and Korean resources at character, word, and document levels.
- Grounding and Counting: A combination of high-quality open-source sets and an in-house synthetic pipeline.
- STEM and Reasoning: Domain-specific academic content, including math, engineering, and science diagrams, retrieved via a search-based synthesis pipeline.
- Korean-Specific Data: Specialized corpora including cultural images from the Korea Tourism Organization and digital culture content from IT Donga and Game Donga.
-
Key Processing and Filtering Details
- Textual Filtering: A lightweight text-based classifier evaluates interleaved data based on educational quality and STEM relevance to upsample high-density information.
- Document Parsing: Charts, tables, and documents are transformed into structured formats like HTML, Markdown, and JSON to improve layout understanding.
- Spatial Grounding: Object locations are represented as normalized bounding boxes with coordinates scaled to a range of [0, 1000].
- Counting Balancing: To prevent bias toward simple categories, the authors use synthetic generation to handle occlusion and explicitly balance the dataset across different count ranges and object types.
- Text-to-Vision Augmentation: For Korean reasoning, text-based problems are converted into high-resolution rendered images to improve academic content parsing.
-
Training Strategy and Usage
- Pre-training Curriculum: The authors employ a progressive curriculum starting with broad filtering for visual diversity, followed by strategic upsampling of specialized datasets to bridge performance gaps.
- SFT Framework: The supervised fine-tuning stage uses a multi-stage curriculum where data is organized by domain. The model is jointly trained on text-only and vision-language data, integrating both non-reasoning and reasoning supervision.
- Multilingual Support: The SFT mixture is designed for multilingual instruction following across English, Korean, Spanish, German, Japanese, and Vietnamese.
Method
The authors leverage a scalable and efficient architecture for EXAONE 4.5, designed to handle high-resolution visual inputs while maintaining strong multimodal alignment and computational efficiency. The framework centers on a 1.2-billion-parameter vision encoder trained from scratch, which processes visual data using hybrid attention and Grouped Query Attention (GQA). This design choice enables the model to retain rich visual representations without aggressive token truncation, addressing the challenge of high-resolution image processing. The vision encoder employs 2D Rotary Positional Embedding (2D RoPE) to capture spatial structure, while the language model retains standard 1D RoPE for compatibility with pre-trained textual representations. The language backbone is derived from the EXAONE 4.0 architecture, enhanced with the Multi-Token Prediction (MTP) module to improve decoding throughput.
The pre-training pipeline is structured in two sequential stages to progressively establish cross-modal alignment and expand representational coverage. In Stage 1, foundational modality alignment is achieved through end-to-end joint training of the vision encoder, merger, and LLM. This stage integrates a diverse mix of image-text pairs, interleaved documents, document understanding data, and OCR-centric samples, while preserving language modeling capability through the inclusion of text-only datasets. Stage 2 focuses on perceptual and knowledge refinement by emphasizing high-density, structured information. The data curriculum shifts toward grounding, document, and OCR-centric data, supplemented with knowledge, mathematics, and STEM datasets to provide the model with domain-specific exposure.
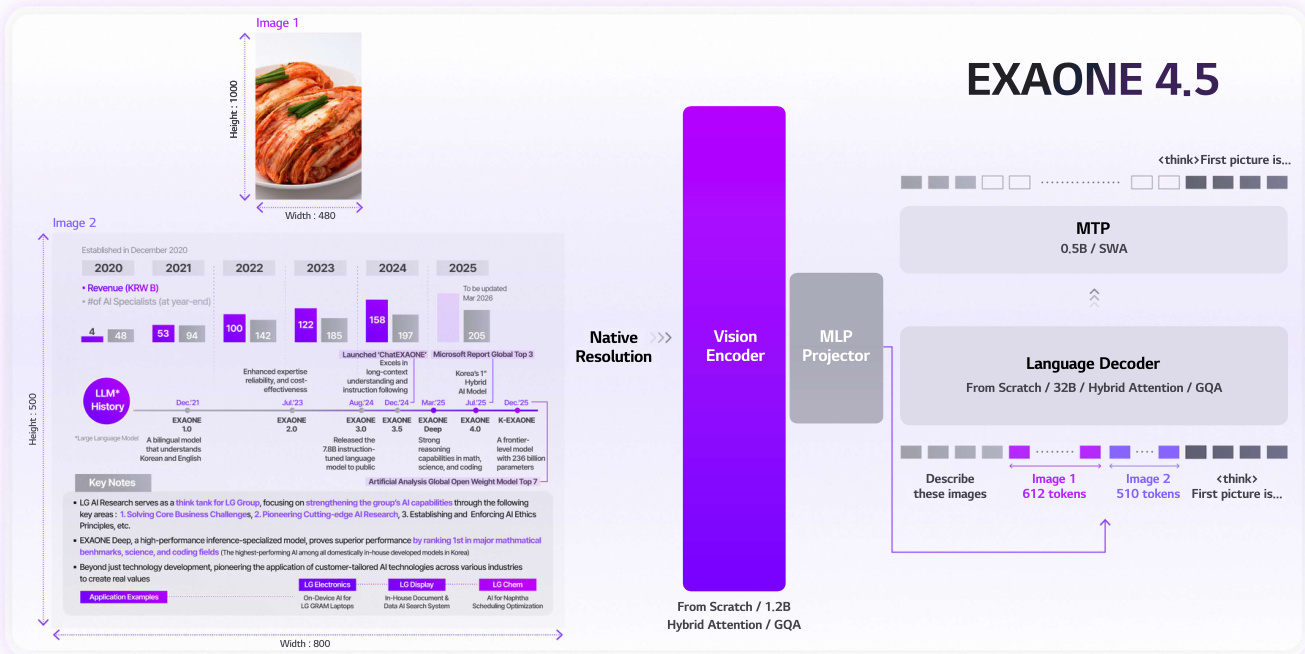
As shown in the figure below, the architecture integrates a native-resolution vision encoder that processes images at 800×1000 resolution, generating 612 visual tokens. These tokens are merged with textual inputs through an MLP projector and fed into the language decoder, which supports a maximum context length of 256K tokens. The language decoder leverages hybrid attention and GQA to optimize computational efficiency and hardware utilization. The model supports a maximum resolution of 800×1000, calibrated to match real-world inputs to balance performance and resource efficiency. The tokenizer, inherited from K-EXAONE, enhances multilingual and Korean language processing, ensuring robust text representations across diverse linguistic contexts. The framework enables stable context extension by integrating long-context training directly into the supervised fine-tuning phase, leveraging a 128K-capable base LLM to stabilize optimization. Context Parallelism is employed to manage the computational demands of 256K sequences. Additionally, joint multimodal reinforcement learning is applied, using task-specific reward functions and GRPO with zero-variance filtering to enhance reasoning across text and vision modalities.
Experiment
EXAONE 4.5 was evaluated across a comprehensive set of vision and language benchmarks to validate its multimodal reasoning, document understanding, and linguistic capabilities. The model demonstrates robust and well-balanced performance, showing particular strength in mathematical reasoning, coding, and complex instruction following. Overall, the results indicate that EXAONE 4.5 is highly competitive against both large-scale and specialized baseline models across a wide range of diverse evaluation scenarios.
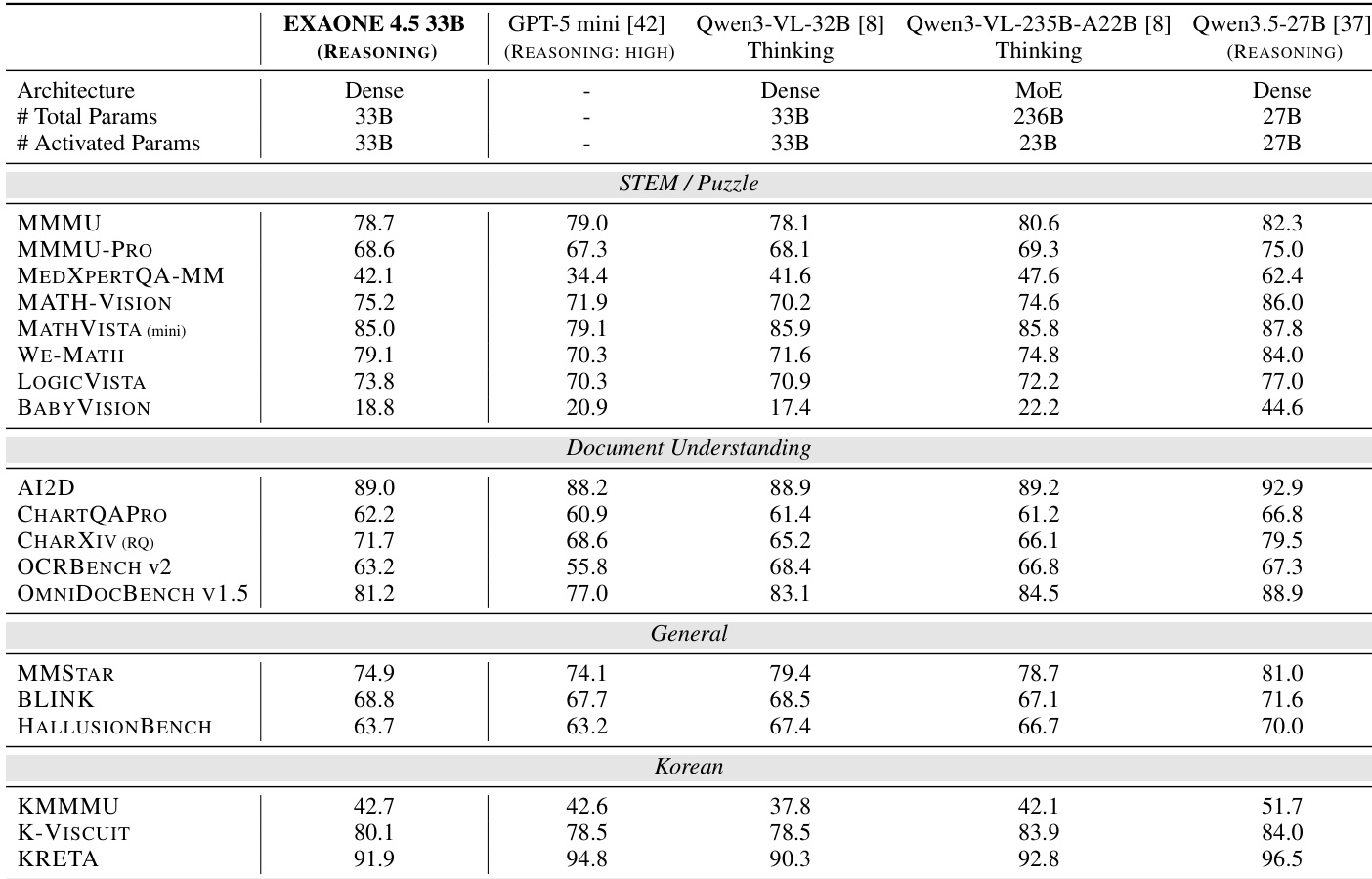
The authors compare EXAONE 4.5 33B with several baseline models across multiple vision benchmarks. Results show that EXAONE 4.5 achieves competitive performance across all categories, particularly excelling in STEM/Puzzle and Document Understanding tasks, while maintaining strong performance in general and Korean benchmarks. EXAONE 4.5 outperforms larger models on several STEM and puzzle benchmarks. It demonstrates strong performance in document understanding tasks, surpassing some larger models. The model maintains consistent results across general and Korean benchmark categories.
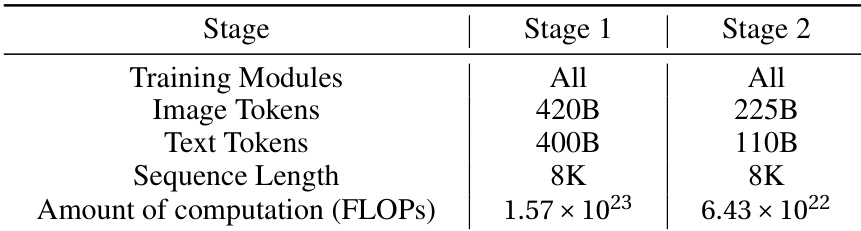
The the the table compares two training stages of a model, showing differences in training modules, data volume, sequence length, and computational requirements. Stage 2 uses less training data and lower computational resources compared to Stage 1. Stage 2 uses fewer image and text tokens than Stage 1 Both stages use the same sequence length of 8K Stage 2 requires significantly less computational resources than Stage 1
The authors compare EXAONE 4.5 with several baseline models across various language benchmarks. Results show that EXAONE 4.5 achieves strong performance in reasoning and coding tasks, particularly excelling on LIVECODEBENCH V6 and performing competitively on other categories such as agentic tool use and instruction following. EXAONE 4.5 achieves the best score on LIVECODEBENCH V6 among all compared models. EXAONE 4.5 outperforms other models on agentic tool-use benchmarks, including τ²-BENCH. EXAONE 4.5 demonstrates competitive performance on instruction-following and long-context understanding tasks.
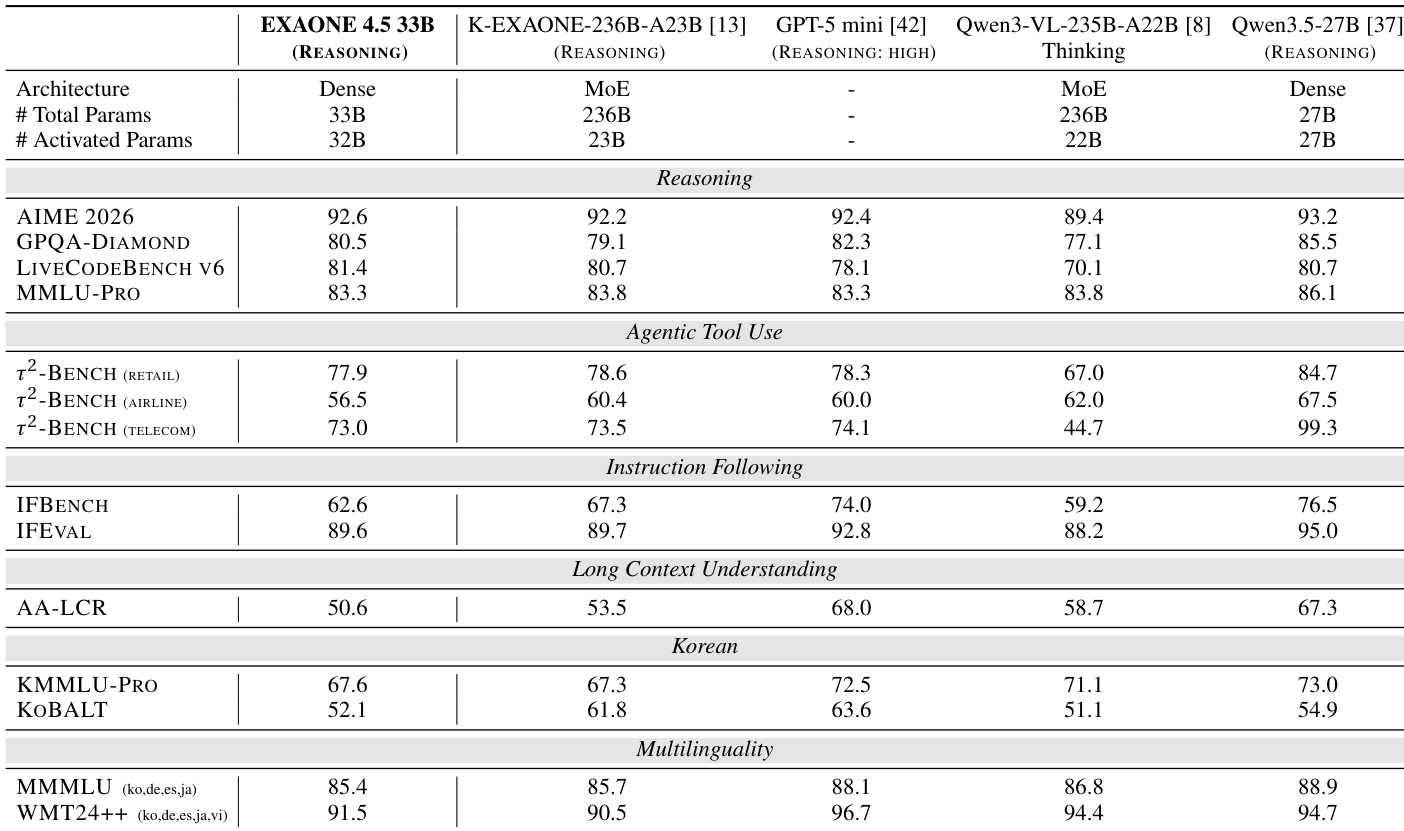
EXAONE 4.5 was evaluated against several baseline models across vision and language benchmarks to assess its reasoning, coding, and multimodal capabilities. The model demonstrates exceptional proficiency in STEM, puzzle-solving, and document understanding, while also outperforming larger models in coding and agentic tool-use tasks. Furthermore, the experimental results highlight a training progression where the second stage achieves high performance using significantly fewer computational resources and data compared to the first stage.