Command Palette
Search for a command to run...
WildDet3D : Passer à l'échelle de la détection 3D promptable en milieu sauvage (in the wild)
WildDet3D : Passer à l'échelle de la détection 3D promptable en milieu sauvage (in the wild)
Résumé
Comprendre les objets en 3D à partir d'une seule image constitue la pierre angulaire de l'intelligence spatiale. Une étape cruciale vers cet objectif est la détection d'objets 3D monoculaire, qui consiste à récupérer l'étendue, la localisation et l'orientation des objets à partir d'une image RGB d'entrée. Pour être opérationnel dans le monde réel (open world), un tel détecteur doit pouvoir se généraliser au-delà des catégories à ensemble fermé (closed-set), prendre en charge diverses modalités de prompt et exploiter les indices géométriques lorsqu'ils sont disponibles.Le progrès est actuellement entravé par deux goulots d'étranglement : les méthodes existantes sont conçues pour un type unique de prompt et manquent de mécanisme pour incorporer des indices géométriques supplémentaires, et les jeux de données 3D actuels ne couvrent que des catégories restreintes dans des environnements contrôlés, ce qui limite le transfert en open-world. Dans ce travail, nous comblons ces deux lacunes. Premièrement, nous introduisons WildDet3D, une architecture unifiée sensible à la géométrie (geometry-aware) qui accepte nativement des prompts de type texte, point et box, et peut incorporer des signaux de profondeur auxiliaires lors de l'inference. Deuxièmement, nous présentons WildDet3D-Data, le plus grand jeu de données de détection 3D en accès libre à ce jour. Celui-ci a été construit en générant des candidate 3D boxes à partir d'annotations 2D existantes, pour ne conserver que celles vérifiées par l'humain, produisant ainsi plus d'un million d'images couvrant 13,5K catégories dans diverses scènes réelles.WildDet3D établit un nouveau niveau de performance de l'état de l'art (state-of-the-art) sur plusieurs benchmarks et configurations. En configuration open-world, il atteint une AP3D de 22,6/24,8 sur notre nouveau benchmark WildDet3D-Bench avec des prompts textuels et de type box. Sur Omni3D, il atteint respectivement 34,2/36,4 AP3D avec des prompts textuels et de type box. Lors des évaluations en zero-shot, il obtient un ODS de 40,3/48,9 sur Argoverse 2 et ScanNet. Notamment, l'incorporation d'indices de profondeur lors de l'inference apporte des gains supplémentaires substantiels (une augmentation moyenne de +20,7 AP selon les configurations).
One-sentence Summary
To enable scalable and open-world monocular 3D object detection, the authors introduce WildDet3D, a unified geometry-aware architecture that supports text, point, and box prompts while incorporating auxiliary depth signals, and WildDet3D-Data, a dataset of over 1M images across 13.5K categories that allows the model to establish a new state of the art across multiple benchmarks.
Key Contributions
- The paper introduces WildDet3D, a unified geometry-aware architecture that supports text, point, and box prompts while incorporating auxiliary depth signals through a specialized depth fusion module.
- This work presents WildDet3D-Data, a large-scale dataset containing over 1M images across 13.5K categories, which was constructed using a multi-model candidate generation pipeline followed by human and VLM verification.
- Experimental results demonstrate that WildDet3D achieves state-of-the-art performance on the Omni3D benchmark and shows strong zero-shot generalization across diverse datasets like Argoverse 2 and ScanNet.
Introduction
Monocular 3D object detection is essential for spatial intelligence in applications like robotics, AR/VR, and mobile devices. However, existing methods are often limited to closed-set categories and fixed interaction modes, typically supporting only a single type of prompt. Furthermore, current 3D datasets are often restricted to narrow categories and controlled environments, which hinders open-world generalization. The authors address these challenges by introducing WildDet3D, a unified geometry-aware architecture that natively accepts text, point, and box prompts while allowing for the integration of auxiliary depth signals at inference time. To support this model, they also present WildDet3D-Data, a massive dataset containing over 1 million human-verified images across 13.5K categories to enable robust open-vocabulary 3D perception.
Dataset

WildDet3D-Data Overview
The authors introduce WildDet3D-Data, a large-scale dataset designed for open-vocabulary 3D detection in diverse, real-world environments. It features over 1M images, 3.7M valid 3D annotations, and 13.5K object categories, representing a 138x increase in category coverage compared to existing datasets like Omni3D.
Dataset Composition and Sources The dataset is built upon dense 2D annotations from four primary large-scale sources:
- COCO: 118K training and 5K validation images.
- LVIS: COCO images with long-tail annotations covering over 1,200 categories.
- Objects365: 609K training and 30K validation images across 365 categories.
- V3Det: 183K training and 30K validation images.
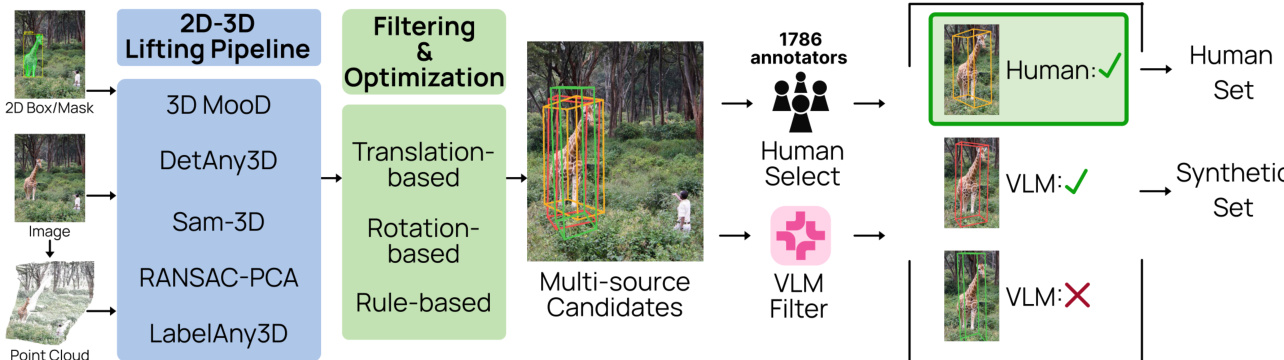
Data Processing and Candidate Generation To lift 2D annotations into 3D space, the authors employ a multi-stage pipeline:
- Geometric Lifting: Images undergo 4x super-resolution before metric depth and camera intrinsics are estimated. Candidate 3D boxes are then generated using five complementary methods: 3D-MOOD, DetAny3D, SAM-3D, RANSAC-PCA, and LabelAny3D.
- Refinement: Initial candidates undergo translation and rotation optimization to align with estimated depth maps and 2D projection constraints.
- Multi-Stage Filtering:
- Geometric Filters: Candidates are removed based on edge contact, occlusion ratios, or unrealistic 3D-to-2D projection sizes.
- Semantic Filters: A VLM (Qwen3.5-9B) removes depicted objects (e.g., pictures or reflections) and composite images.
- Size and Geometry Filters: GPT-4o-mini estimates physical dimensions to filter out implausible scales, depth-to-width ratios, and axis proportions.
- Final Selection: The authors use two paths to finalize annotations:
- Human Selection: A subset of ~103K images is verified by crowdsourced annotators who rate candidate quality.
- VLM Selection: For the remaining ~896K images, a fine-tuned Molmo2 model automatically selects the best candidate based on six perceptual criteria.
Training and Evaluation Usage The authors use the data in a three-stage training curriculum:
- Stage 1: Initial training on Omni3D.
- Stage 2: Fine-tuning on a mixture of Omni3D, WildDet3D-Data (both human and synthetic subsets), and supplementary datasets (CA-1M, Waymo, 3EED, and FoundationPose).
- Stage 3: Final fine-tuning on Omni3D and the human-annotated portion of WildDet3D-Data using mask-guided point and box training.
For evaluation, the authors construct WildDet3D-Bench, an in-the-wild benchmark containing 700+ open-vocabulary categories. This benchmark uses a balanced sampling strategy to ensure coverage across rare, common, and frequent categories.
Method
The WildDet3D framework is designed to perform 3D object detection from a single RGB image, optionally augmented with camera intrinsics and depth information, guided by a user-specified prompt. The architecture is structured around three primary components: a dual-vision encoder system that processes visual and geometric inputs, a promptable detector that conditions detection on diverse prompt types, and a 3D detection head that produces metric 3D bounding boxes with unambiguous orientation. An overview of the framework is shown in Figure 3, which illustrates the modular flow from input through feature extraction and fusion to multi-task prediction.
The dual-vision encoder system decouples semantic and geometric feature extraction to address the inherent trade-off between detection quality and metric depth estimation. It consists of an image encoder and an RGBD encoder. The image encoder, a Vision Transformer (ViT-H) with a SimpleFPN neck, is initialized from a segmentation-pretrained checkpoint and extracts high-resolution, multi-scale semantic features. The RGBD encoder, built on a DINOv2 ViT-L/14 backbone, processes the same image along with an optional depth map, producing depth latents through a convolutional neck. These two encoders operate independently, allowing the architecture to leverage different pretrained models optimized for their respective tasks—semantic segmentation for the image encoder and metric depth estimation for the RGBD encoder. The depth fusion module, highlighted in yellow in Figure 3, merges these two streams by injecting depth latents into the image encoder's feature maps. This is achieved through a residual connection where the depth latents, after being bilinearly upsampled to match the visual feature resolution and normalized via LayerNorm, are projected to the visual feature dimension using a zero-initialized 1×1 convolution. This design ensures that the pretrained visual features remain stable during training, with the depth contribution being gradually learned.
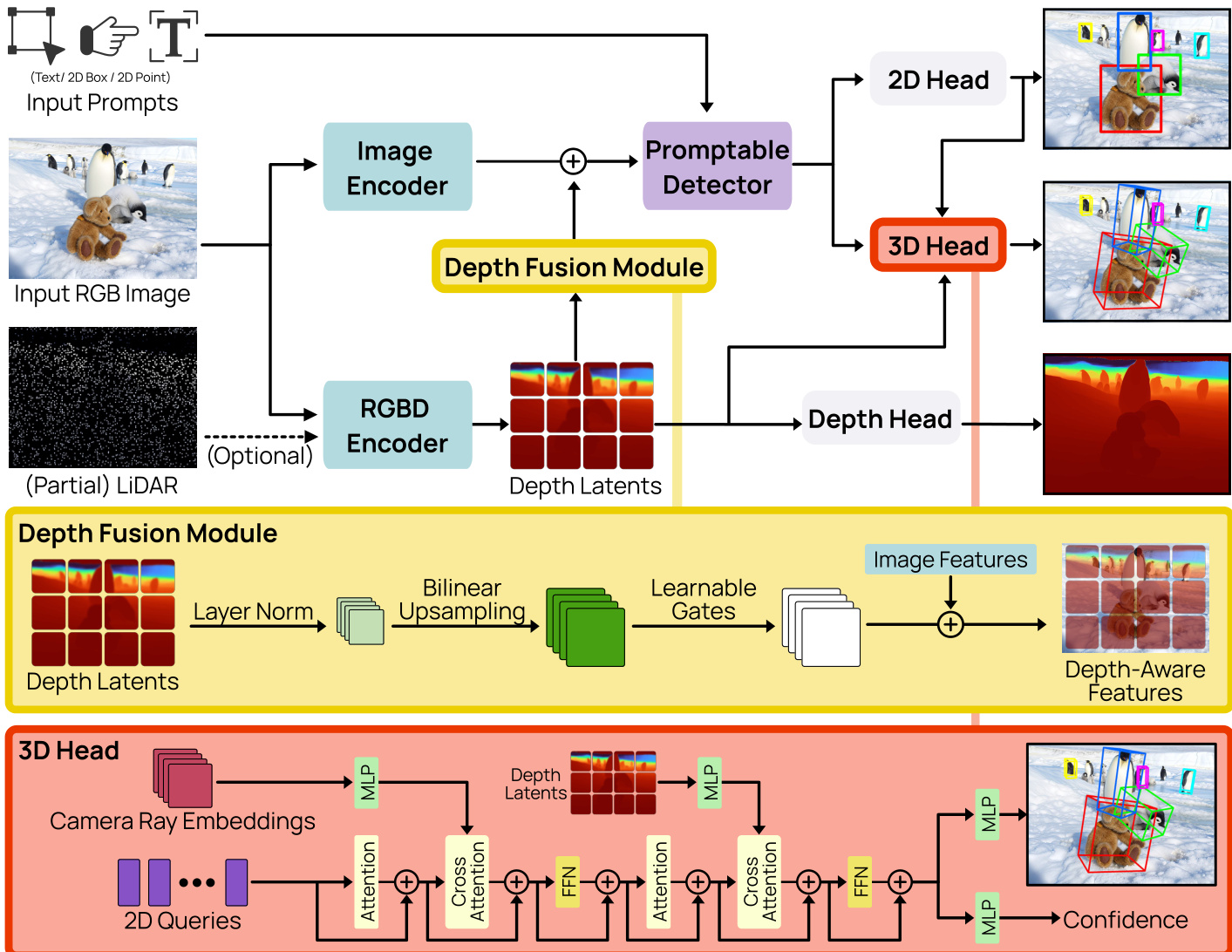
The promptable detector, depicted as the purple block in Figure 3, unifies various input prompt types into a single representation for the detection heads. It accepts four prompt modalities: text, point, box, and exemplar. Each prompt type is encoded separately: text prompts are tokenized and passed through a causal text Transformer, while geometric prompts (point and box) are encoded by summing a direct coordinate projection, ROI-aligned features, and sinusoidal positional encoding, refined by a cross-attention Transformer. Exemplar prompts use a similar encoding but are distinguished by a special token and a multi-target matching strategy. The encoded tokens from all prompt types are concatenated into a single sequence, which acts as cross-attention memory in the subsequent detection stages. This component operates on a per-prompt batching strategy, where training batches are constructed around unique prompt instances rather than images, enabling fine-grained supervision and handling an arbitrary number of categories per image.
The 3D detection head, shown in red in Figure 3, is responsible for generating the final 3D bounding box predictions. It takes the query features from the promptable detector and enriches them with multi-source information. For each decoder layer, it first incorporates camera geometry by generating per-pixel ray directions from the camera intrinsics and encoding them using 8th-order real spherical harmonics. This ray feature is fused via cross-attention. Subsequently, it fuses depth latents from the RGBD encoder using another cross-attention module. The fused query features are then passed through a two-layer MLP to predict a 12-dimensional encoding of the 3D box, which includes center offset, log-depth, log-dimensions, and a 6D rotation representation. To resolve the inherent ambiguity in 3D box orientation, a two-step unambiguous rotation normalization is applied to both ground truth and predictions: dimensions are ordered such that width is less than or equal to length, and the yaw angle is folded into the interval [0,π). This normalization ensures a one-to-one mapping between box geometry and the regression target. The 3D center is recovered at inference by back-projecting the predicted offset and depth. A parallel confidence branch, also a two-layer MLP, predicts a scalar score s3D∈[0,1], which is trained with an IoU-aware focal BCE loss using a soft target that combines depth prediction quality and 3D IoU. The final detection score is a weighted sum of the 2D objectness score and the 3D confidence.

Experiment
The researchers evaluate WildDet3D through extensive testing on a new in-the-wild benchmark, standard datasets like Omni3D, and zero-shot transfer tasks to validate its open-vocabulary capabilities and geometric accuracy. The experiments demonstrate that the model significantly outperforms existing methods in detecting diverse, long-tailed object categories and generalizes effectively across different environments. Furthermore, the results show that the architecture successfully leverages optional depth cues to resolve scale ambiguity and provides a versatile foundation for real-world applications in robotics, AR/VR, and mobile computing.
The model uses a three-stage training pipeline, starting from scratch and progressing through data mixing and mask-guided training. Each stage employs specific data combinations and learning rate schedules to gradually improve performance. The training begins from scratch and proceeds in three stages with increasing complexity. Stage 2 combines multiple datasets with a specific data mixing ratio and uses the output of Stage 1 as initialization. Stage 3 uses a mask-guided approach with a different data mix and further refines the model from Stage 2.

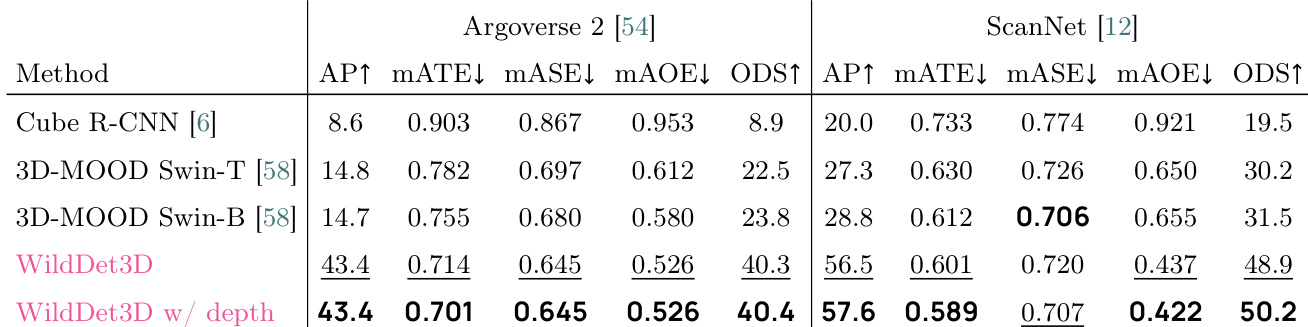
The authors evaluate WildDet3D on Argoverse 2 and ScanNet benchmarks, showing significant improvements over prior methods in detection and geometric accuracy. The model achieves higher AP and ODS scores while reducing translation, scale, and orientation errors, particularly when depth information is available. WildDet3D achieves superior detection and geometric accuracy compared to baselines on Argoverse 2 and ScanNet. The model reduces translation, scale, and orientation errors, improving localization precision. Performance gains are more pronounced when depth information is incorporated, especially on ScanNet.
The authors evaluate WildDet3D on WildDet3D-Bench, demonstrating significant improvements over baselines across different training data and prompt modalities. Results show that incorporating additional data and ground-truth depth leads to substantial performance gains, particularly for rare and common categories. WildDet3D achieves the highest performance on WildDet3D-Bench across all categories and prompt types. The inclusion of additional training data and ground-truth depth significantly improves detection accuracy. Performance gains are most pronounced on rare and common categories, highlighting strong generalization to unseen classes.
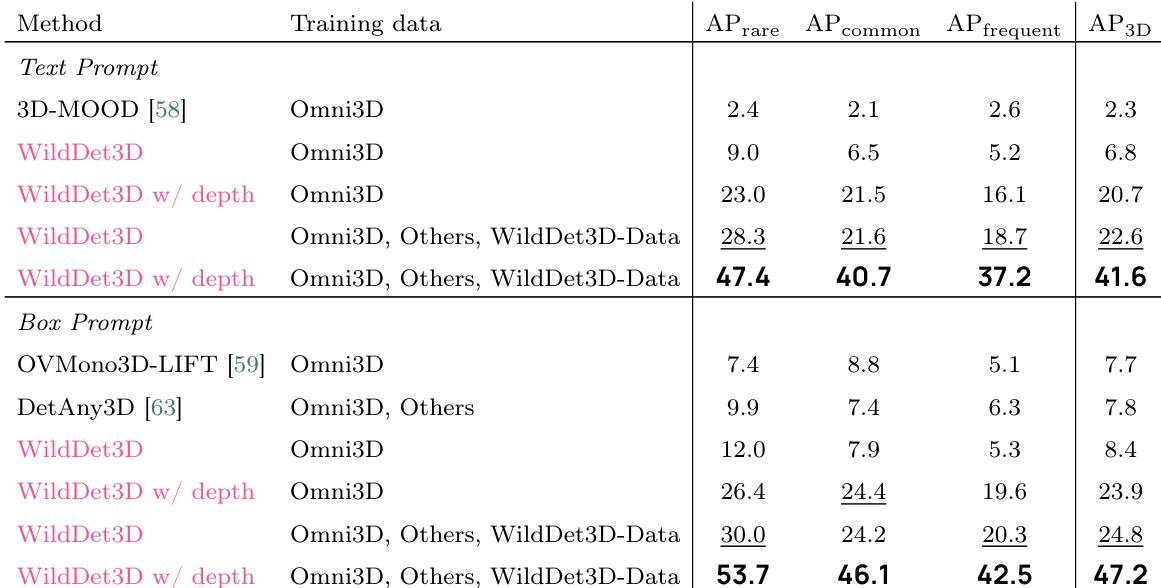
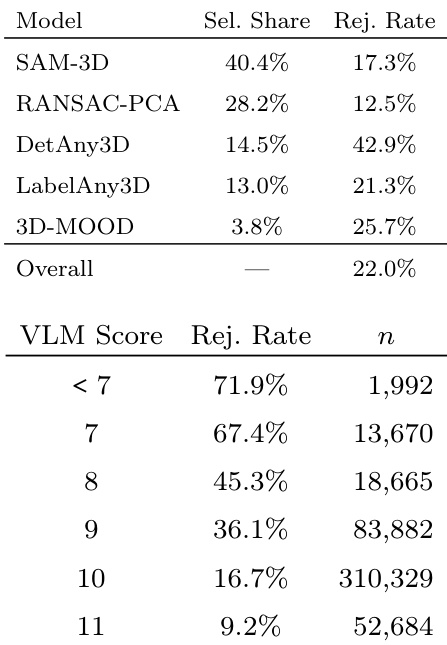
The authors evaluate WildDet3D on multiple benchmarks, showing superior performance compared to existing methods. Results indicate that incorporating depth information significantly enhances detection accuracy, particularly in the box prompt setting. The model achieves strong results across various datasets, demonstrating generalization and robustness. WildDet3D achieves higher AP3D than all baselines across multiple datasets. Performance improves substantially when depth is provided, especially in the box prompt setting. The model shows consistent gains on both text and box prompt settings, with the largest improvements on rare categories.
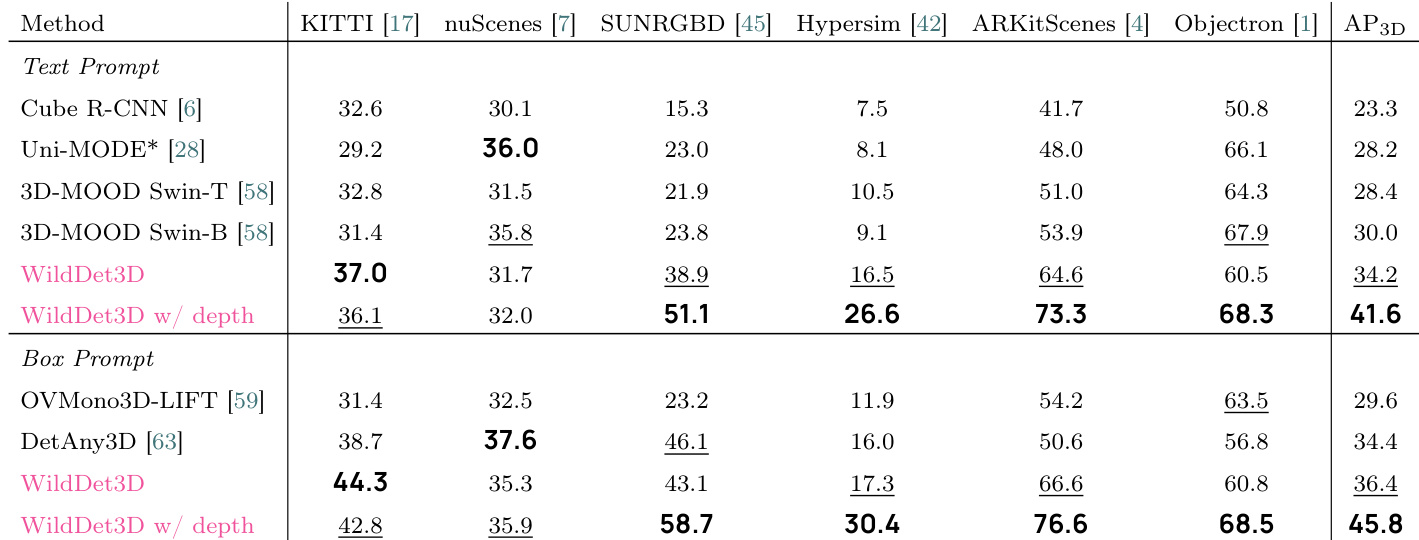
The the the table presents validation results for the annotation pipeline, showing how different candidate models are selected and rejected by human annotators, and how VLM scores correlate with human judgment. The data indicates that model quality varies significantly across candidates and that VLM scoring effectively predicts human acceptance, though it cannot fully replace human evaluation. Human annotators select and reject candidate models at rates that vary substantially across different methods. VLM scores show a perfect monotonic correlation with human rejection rates, indicating strong predictive power. Despite strong correlation, VLM scoring alone cannot replace human judgment due to a significant gap in rejection rates even at high scores.
The model is evaluated through a multi-stage training pipeline and tested across various benchmarks including Argoverse 2, ScanNet, and WildDet3D-Bench to validate detection accuracy and geometric precision. The results demonstrate that incorporating depth information and diverse training data significantly enhances localization and generalization, particularly for rare categories. Additionally, an annotation pipeline validation shows that while VLM scores correlate strongly with human judgment, they serve as a predictive tool rather than a complete replacement for human evaluation.