Command Palette
Search for a command to run...
MegaStyle : Construction d'un dataset de styles diversifié et scalable via un mapping de style Text-to-Image cohérent
MegaStyle : Construction d'un dataset de styles diversifié et scalable via un mapping de style Text-to-Image cohérent
Junyao Gao Sibo Liu Jiaxing Li Yanan Sun Yuanpeng Tu Fei Shen Weidong Zhang Cairong Zhao Jun Zhang
Résumé
Dans cet article, nous présentons MegaStyle, un nouveau pipeline de curation de données évolutif qui construit un ensemble de données de styles de haute qualité, caractérisé par une cohérence intra-style et une diversité inter-style. Nous y parvenons en exploitant la capacité de mapping texte-image de style cohérent des grands modèles génératifs actuels, capables de générer des images dans le même style à partir d'une description de style donnée. Sur cette base, nous avons constitué une galerie de prompts diversifiée et équilibrée comprenant 170K style prompts et 400K content prompts, puis nous avons généré un ensemble de données de style à grande échelle, MegaStyle-1.4M, via des combinaisons de content-style prompts. À l'aide de MegaStyle-1.4M, nous proposons un apprentissage contrastif supervisé par le style (style-supervised contrastive learning) afin d'affiner un encodeur de style, MegaStyle-Encoder, pour l'extraction de représentations expressives et spécifiques au style ; nous entraînons également un modèle de transfert de style basé sur FLUX, nommé MegaStyle-FLUX. Des expériences approfondies démontrent l'importance de maintenir la cohérence intra-style, la diversité inter-style et une haute qualité pour un ensemble de données de style, ainsi que l'efficacité du MegaStyle-1.4M proposé. De plus, lorsqu'ils sont entraînés sur MegaStyle-1.4M, MegaStyle-Encoder et MegaStyle-FLUX fournissent une mesure de similarité de style fiable et un transfert de style généralisable, apportant ainsi une contribution significative à la communauté du transfert de style. Des résultats supplémentaires sont disponibles sur notre site de projet : https://jeoyal.github.io/MegaStyle/.
One-sentence Summary
The authors propose MegaStyle, a scalable data curation pipeline that leverages consistent text-to-image style mapping to construct the MegaStyle-1.4M dataset, which features high intra-style consistency and inter-style diversity, and they utilize style-supervised contrastive learning to develop MegaStyle-Encoder and MegaStyle-FLUX for reliable style similarity measurement and generalizable style transfer.
Key Contributions
- The paper introduces MegaStyle, a scalable data curation pipeline that leverages the consistent text-to-image mapping of large generative models to create the MegaStyle-1.4M dataset. This dataset is constructed by combining a diverse gallery of 170K style prompts and 400K content prompts to ensure intra-style consistency and inter-style diversity.
- A novel style-supervised contrastive learning objective is proposed to fine-tune the MegaStyle-Encoder for extracting expressive and style-specific representations. This approach enables more reliable style similarity measurements compared to existing semantic-based feature spaces.
- The researchers develop MegaStyle-FLUX, a FLUX-based style transfer model trained on the MegaStyle-1.4M dataset using paired supervision. Experiments demonstrate that this model achieves stable and generalizable style transfer performance.
Introduction
Image style transfer is essential for creative applications like artistic generation and digital filters, yet current methods struggle to decouple style from content. Existing approaches often rely on self-supervised learning which leads to content leakage, or use synthetic datasets generated by prior style transfer models that suffer from low diversity, poor image quality, and inconsistent styles within a single category. The authors leverage the consistent text-to-image mapping capabilities of large generative models to bypass these limitations. They introduce MegaStyle, a scalable data curation pipeline that uses a massive prompt gallery to generate the MegaStyle-1.4M dataset. From this, they develop MegaStyle-Encoder for precise style similarity measurement and MegaStyle-FLUX for stable, generalizable style transfer.
Dataset

-
Dataset Composition and Sources The authors introduce MegaStyle-1.4M, a large scale dataset designed for high intra-style consistency and inter-style diversity. The construction begins with two primary image pools:
- Style Image Pool (2M images): Comprised of 1M deduplicated images from JourneyDB, 80K images from WikiArt, and 1M stylized images from LAION-Aesthetics filtered by WikiArt style descriptors.
- Content Image Pool (2M images): Consists of the remaining non-stylized images from LAION-Aesthetics.
-
Prompt Curation and Filtering To create a high quality prompt gallery, the authors utilize the VLM Qwen3-VL to generate specialized captions:
- Style Prompts: These focus exclusively on artistic aspects such as color composition, light distribution, medium, texture, and brushwork, while ignoring content.
- Content Prompts: These describe only objects and visual relationships, excluding any style information.
- Filtering and Balancing: The initial 2M prompts undergo a two-stage sampling process. First, exact, fuzzy, and semantic deduplication via Nemo-Curator reduces the pool to 1M prompts. Second, a hierarchical k-means balancing algorithm is applied to ensure a diverse distribution, resulting in a final set of 170K style prompts and 400K content prompts.
-
Dataset Generation and Usage The final MegaStyle-1.4M dataset is synthesized using the consistent text-to-image mapping capabilities of Qwen-Image:
- Generation Strategy: For every style prompt, the authors randomly sample N content prompts to create multiple content-style combinations.
- Final Output: This process generates 1.4M images that share identical style descriptors but depict different semantic contents.
- Training Application: The resulting intra-style consistent pairs are used to train models like MegaStyle-FLUX to capture fine-grained stylistic nuances such as brushwork and texture.
Method
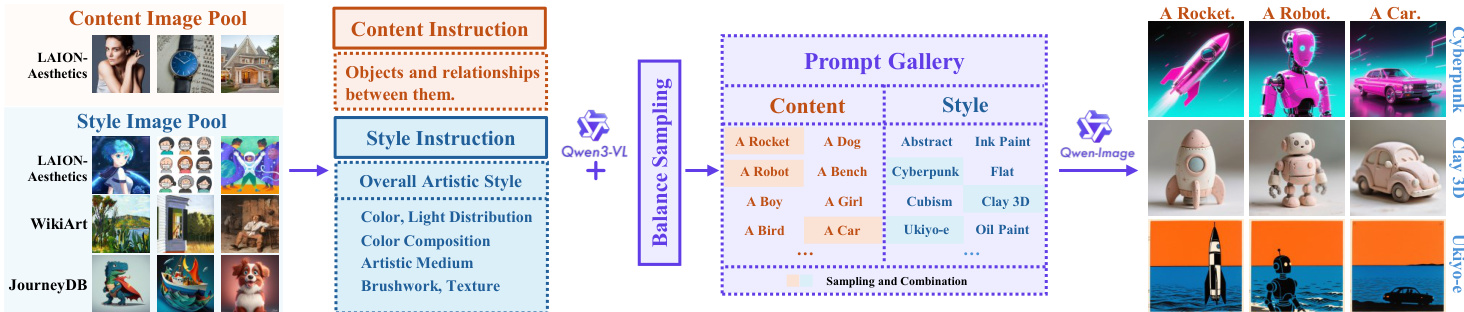
The authors leverage a two-stage framework for style transfer, beginning with a data curation pipeline and proceeding to the design of the MegaStyle-FLUX model. The data curation process, illustrated in the figure below, begins with collecting content and style images from open-source datasets such as LAION-Aesthetics, WikiArt, and JourneyDB. These images are then processed through a prompt generation stage using Qwen3-VL, which produces content and style descriptions based on carefully designed instruction templates. The content prompts focus on object relationships and visual attributes without stylistic elements, while the style prompts emphasize artistic features such as color composition, light distribution, medium, texture, and brushwork. To ensure diversity and balance, the authors employ a hierarchical sampling strategy that groups prompts by semantic similarity and samples from each cluster to form a balanced set of content-style combinations. These combinations are then used to generate style images via Qwen-Image, resulting in a dataset of paired content and style images suitable for training a style transfer model.
The core of the proposed method involves training a dedicated style encoder, MegaStyle-Encoder, to extract style-specific representations. Previous approaches rely on vision-language models (VLMs) that are optimized for semantic alignment, which may not capture style effectively. To address this, the authors introduce a style-supervised contrastive learning (SSCL) objective trained on the MegaStyle-1.4M dataset, which provides intra-style consistent and inter-style diverse image pairs. The training objective combines supervised contrastive learning (SCL) with an image-text contrastive loss. For image-style-prompt pairs, the SCL loss encourages the encoder to produce similar representations for images sharing the same style while pushing apart representations from different styles. The image-text contrastive loss further regularizes the model by aligning image features with their corresponding style prompt embeddings. The encoder, based on the SigLIP architecture, is fine-tuned using a large batch size of 8,192 to enhance the diversity of negative samples and prevent the model from learning trivial cues. Only the image encoder parameters are updated during this process.
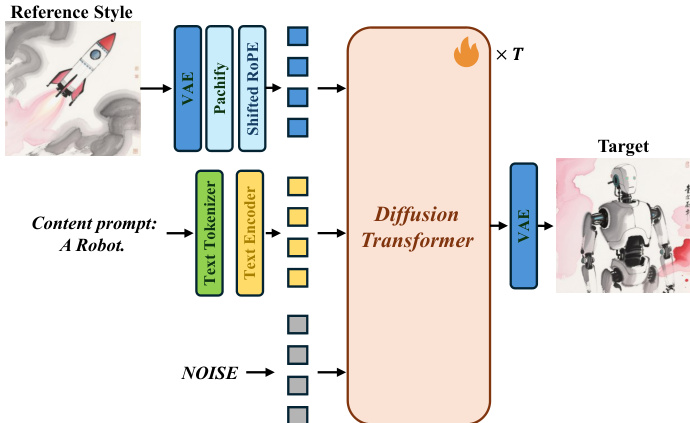
The style transfer model, MegaStyle-FLUX, is built upon the FLUX text-to-image (T2I) model and is designed to transfer the style from a reference image to a target content specified by a text prompt. The framework, as shown in the figure below, takes a reference style image and a content prompt as inputs. The reference style image is encoded and patchified into visual tokens using FLUX's VAE. These style tokens are then concatenated with the noisy image tokens and the text tokens derived from the content prompt. The combined tokens are fed into the diffusion transformer (MM-DiT) backbone, which generates the stylized output. To prevent positional conflicts and cross-image attention bias, a shifted RoPE is applied to the reference style tokens. During training, only the diffusion transformer is updated, while all other components remain frozen. This approach allows MegaStyle-FLUX to achieve generalizable and stable style transfer by leveraging the large-scale MegaStyle-1.4M dataset.
Experiment
The evaluation utilizes a custom StyleRetrieval benchmark to test the MegaStyle-Encoder's ability to extract style-specific representations and compares the MegaStyle-FLUX model against state-of-the-art methods using text alignment, style similarity, and human preference. The results demonstrate that the MegaStyle-Encoder provides superior style retrieval by avoiding the semantic content biases common in other models. Furthermore, MegaStyle-FLUX achieves highly stable and generalizable style transfer, effectively balancing text alignment with stylistic accuracy while avoiding the content leakage or limited color transfer seen in existing approaches.
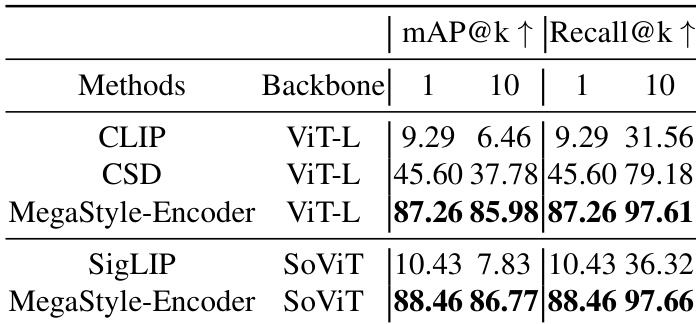
The authors compare MegaStyle-Encoder with other style encoders on a retrieval benchmark, showing that it achieves superior performance in both mAP and Recall metrics across different backbones. Results indicate that MegaStyle-Encoder consistently outperforms other methods, demonstrating its effectiveness in extracting style-specific representations. MegaStyle-Encoder achieves higher mAP and Recall scores than all other methods across all backbones. MegaStyle-Encoder outperforms CLIP, CSD, and SigLIP in style retrieval tasks. The model demonstrates strong performance with both ViT-L and SoViT backbones, showing robustness across architectures.
The authors compare MegaStyle-Encoder with CLIP and CSD across multiple benchmarks. Results show that MegaStyle-Encoder achieves superior performance in style retrieval across all evaluated metrics and datasets, demonstrating its effectiveness in extracting style-specific representations. MegaStyle-Encoder outperforms CLIP and CSD on all benchmarks and metrics. MegaStyle-Encoder achieves the highest scores in style retrieval across multiple datasets. The model demonstrates consistent performance improvements over baselines in both mAP and Recall.

The authors compare MegaStyle-FLUX with other style transfer methods, showing that it achieves the highest text alignment and competitive style alignment. Results indicate that MegaStyle-FLUX outperforms baselines in aligning generated images with text prompts while maintaining strong style representation. MegaStyle-FLUX achieves the highest text alignment score among all methods. MegaStyle-FLUX demonstrates strong style alignment, ranking second best in the comparison. MegaStyle-FLUX outperforms other methods in aligning generated images with text descriptions.

The the the table compares different style datasets on style and text alignment metrics. MegaStyle-1.4M achieves the highest scores across both metrics, demonstrating its effectiveness in providing high-quality style and text alignment. MegaStyle-1.4M outperforms other datasets in style alignment MegaStyle-1.4M achieves the highest text alignment score MegaStyle-1.4M shows superior performance compared to JourneyDB and OmniStyle-150K

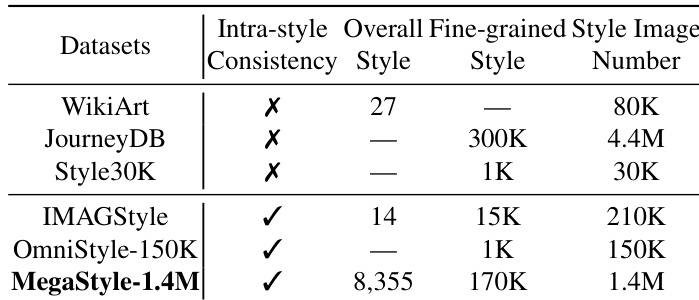
The the the table compares different style datasets based on intra-style consistency, number of styles, and total images. MegaStyle-1.4M achieves high intra-style consistency and a large number of styles and images, outperforming other datasets in these aspects. MegaStyle-1.4M achieves high intra-style consistency MegaStyle-1.4M has a large number of styles and images Other datasets lack intra-style consistency or have fewer styles and images
The authors evaluate the MegaStyle framework through retrieval benchmarks, style transfer comparisons, and dataset analyses to validate its effectiveness in capturing style-specific representations. The results demonstrate that MegaStyle-Encoder consistently outperforms existing methods across various backbones, while MegaStyle-FLUX achieves superior text alignment during style transfer. Furthermore, the MegaStyle-1.4M dataset is shown to provide higher quality style and text alignment along with greater intra-style consistency compared to existing datasets.