Command Palette
Search for a command to run...
Ordinateurs neuronaux
Ordinateurs neuronaux
Résumé
Voici la traduction professionnelle de votre texte en français, respectant les standards de l'écriture scientifique et technologique :« Nous proposons une nouvelle frontière : les Neural Computers (NCs), qui unifient le calcul, la mémoire et les entrées/sorties (I/O) des ordinateurs traditionnels au sein d'un état d'exécution (runtime state) appris. Notre objectif à long terme est le Completely Neural Computer (CNC) : la réalisation mature et polyvalente de cette forme de machine émergente, caractérisée par une exécution stable, une reprogrammation explicite et une réutilisation durable des capacités. Dans un premier temps, nous étudions si des primitives élémentaires de NC peuvent être apprises uniquement à partir de traces d'I/O collectées, sans recourir à l'instrumentation de l'état du programme. Concrètement, nous instancions les NC en tant que modèles vidéo capables de générer des trames d'écran (roll out) à partir d'instructions, de pixels et d'actions utilisateur (lorsqu'elles sont disponibles) dans des environnements CLI et GUI. Nous démontrons que les NC peuvent acquérir des primitives d'interface élémentaires, en particulier l'alignement I/O et le contrôle à court horizon, bien que la réutilisation de routine, les mises à jour contrôlées et la stabilité symbolique demeurent des défis majeurs. Enfin, nous esquissons une feuille de route vers les CNC, afin d'établir un nouveau paradigme informatique dépassant les agents actuels et les ordinateurs conventionnels. »
One-sentence Summary
By instantiating Neural Computers (NCs) as video models that roll out screen frames from instructions, pixels, and user actions, the researchers demonstrate that these models can learn elementary interface primitives, such as I/O alignment and short-horizon control, directly from collected I/O traces.
Key Contributions
- The paper introduces the concept of Neural Computers (NCs), a new machine paradigm that unifies computation, memory, and I/O into a single learned runtime state using a tensor-uniform pipeline.
- This work presents a method for learning elementary NC primitives solely from collected I/O traces, instantiating the models as video generators that roll out screen frames from instructions, pixels, and user actions in CLI and GUI environments.
- Experimental results demonstrate that these NCs can acquire early-stage runtime primitives, specifically achieving I/O alignment and short-horizon control within interface settings.
Introduction
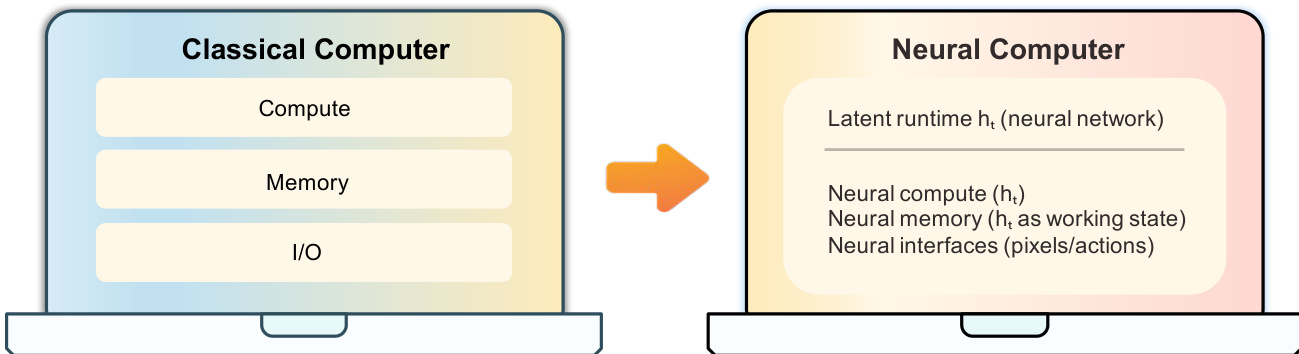
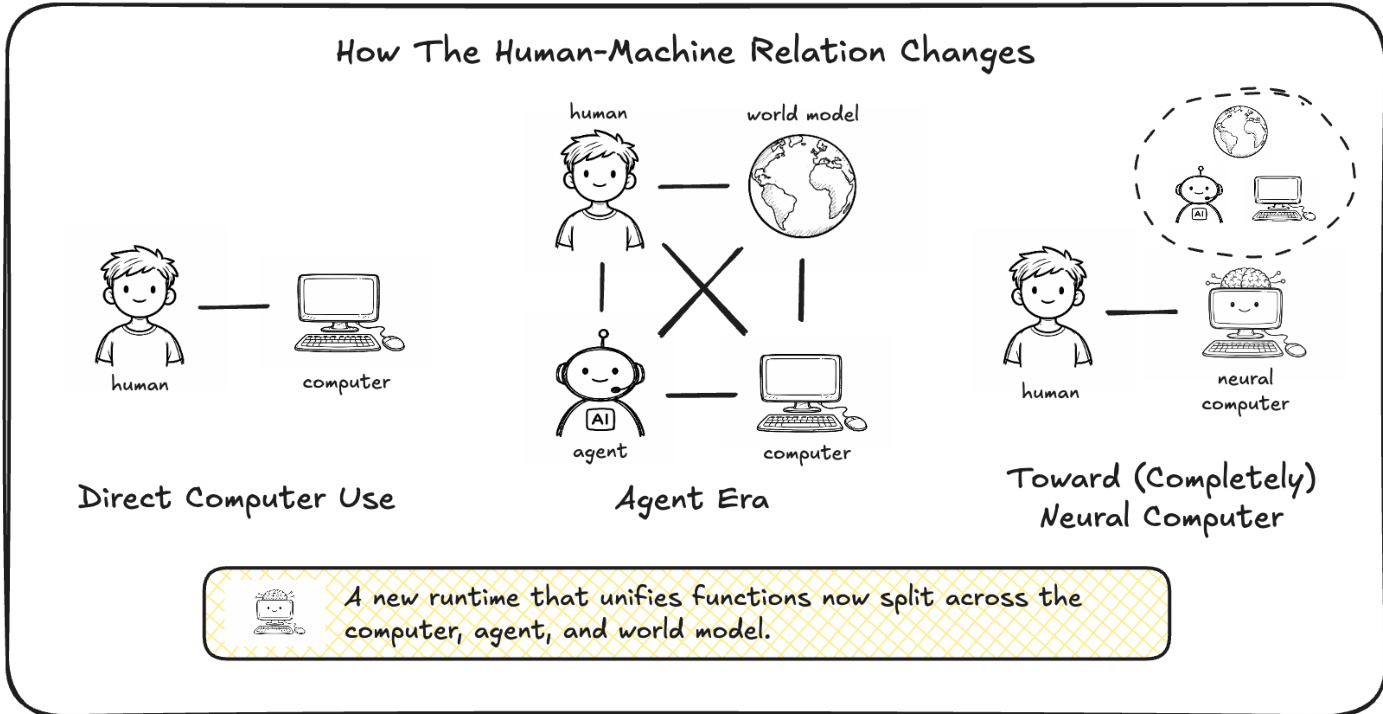
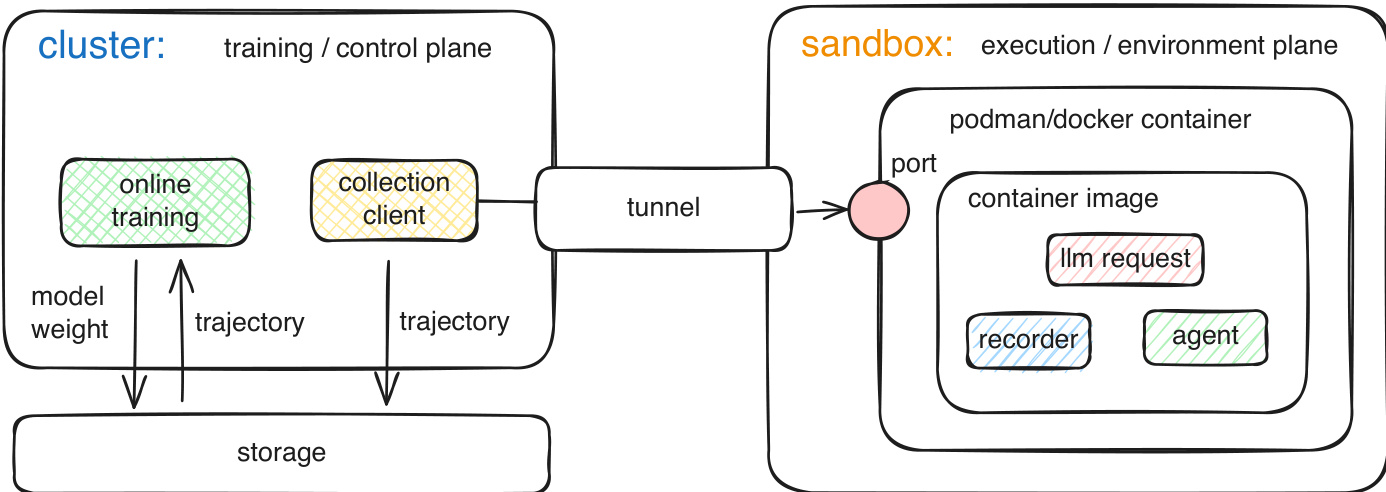
Modern computing relies on a modular stack that separates computation, memory, and I/O into distinct hardware and software layers. While current AI agents and world models attempt to interact with these systems, they remain external to the execution environment, leaving the actual running state outside the neural model. The authors propose a new paradigm called Neural Computers (NCs), which unifies these functions into a single learned runtime state. By instantiating NCs as video models for CLI and GUI interfaces, the authors demonstrate that these systems can learn elementary primitives such as I/O alignment and short-horizon control directly from raw interaction traces. Although current prototypes struggle with symbolic stability and long-horizon reasoning, this work provides a technical foundation and a roadmap toward Completely Neural Computers (CNCs) that are Turing complete and universally programmable.
Dataset
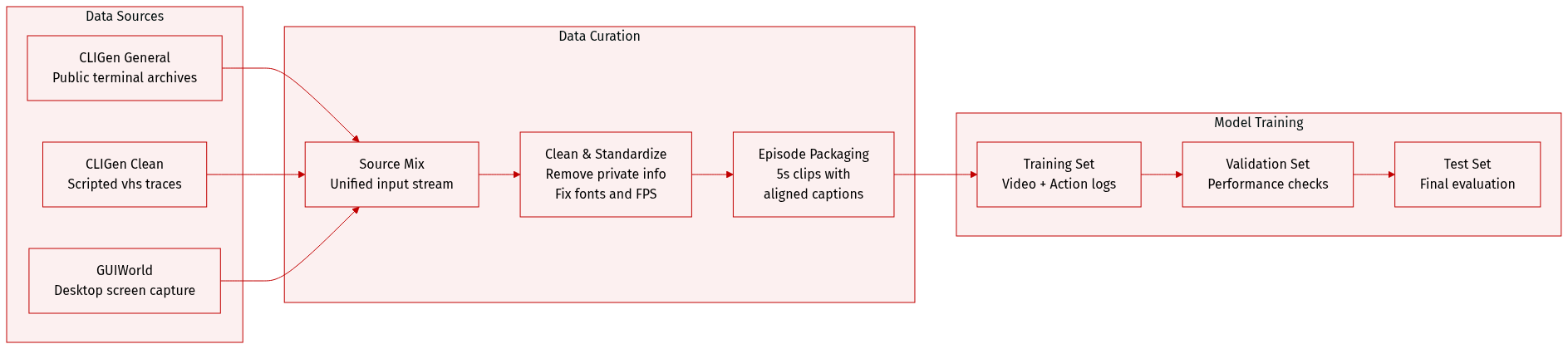
Dataset Overview
The authors constructed a multi-source dataset designed for terminal and GUI interaction modeling, comprising three primary components: CLIGen (General), CLIGen (Clean), and GUIWorld.
1. Dataset Composition and Sources
- CLIGen (General): Derived from public asciinema .cast archives. The authors replay these sessions using official tools to preserve ANSI-faithful decoding, terminal geometry, and palette transitions.
- CLIGen (Clean): Created using the open-source vhs toolkit. The authors authored approximately 250k deterministic scripts executed in Dockerized environments to ensure repeatable, well-paced terminal demonstrations.
- GUIWorld: Captured via a controlled desktop-capture rig using an Ubuntu 22.04 environment (XFCE4). This includes "Random Slow" (1,000 hours of deliberate, sparse movement), "Random Fast" (400 hours of dense typing and motion), and supervised trajectories (110 hours) collected via Claude CUA.
2. Key Subset Details
- CLIGen (General): Consists of 823,989 video streams totaling approximately 1,100 hours.
- CLIGen (Clean): After a 51.21% retention filter, this subset includes:
- ~78k regular traces (e.g., package installations, interactive REPL usage).
- ~50k Python math validation traces.
- GUIWorld: Provides a mix of exploration data (random interactions) and high-signal, goal-directed supervised traces.
3. Processing and Training Preparation
- Temporal Normalization: All clips are segmented into roughly five-second episodes. To maintain a fixed length, shorter clips repeat their final frame, while longer clips are uniformly subsampled.
- Frame Rate: Video streams are resampled to 15 FPS.
- Captioning and Metadata:
- For CLIGen (General), the authors use Llama 3.1 70B to generate three distinct captioning styles (semantic, regular, and detailed) based on underlying buffers and logs.
- For CLIGen (Clean), captions are derived directly from the raw vhs scripts.
- GUIWorld data is packaged with both raw-action and meta-action views to allow for flexible encoder training.
- Sanitization: The pipeline applies filters to remove sensitive strings and redacts GUI regions likely to contain private content.
4. Standardization and Rendering
- Terminal Consistency: To remove typographic confounds, the authors standardize CLIGen (Clean) by fixing a single monospace font and size, using consistent color palettes for success/error states, and locking resolutions.
- GUI Consistency: GUIWorld recordings use a fixed 1024x768 virtual display with a specific set of open-source applications (e.g., Firefox, VS Code, Terminal) to ensure environmental stability.
- Alignment: All modalities share a single monotonic clock to ensure pointer, key, and text events are temporally aligned with the rendered frames.
Method
The authors propose a framework for Neural Computers (NCs) that shifts the paradigm from classical computing to a unified neural runtime. In this architecture, the latent runtime state ht is realized by the model's time-indexed video latents zt. The diffusion transformer serves as the state-update map, consuming prior latents alongside current observations and conditioning inputs to produce the updated state.
The framework is instantiated through two primary prototypes: CLIGen for command-line interfaces and GUIWorld for graphical user interfaces. For CLIGen, the model treats generation as a text-and-image-to-video task. The first terminal frame is encoded via a VAE into a conditioning latent, while a CLIP image encoder and a text encoder extract visual and semantic features, respectively. These features are concatenated with diffusion noise and processed by a diffusion transformer (DiT) stack.
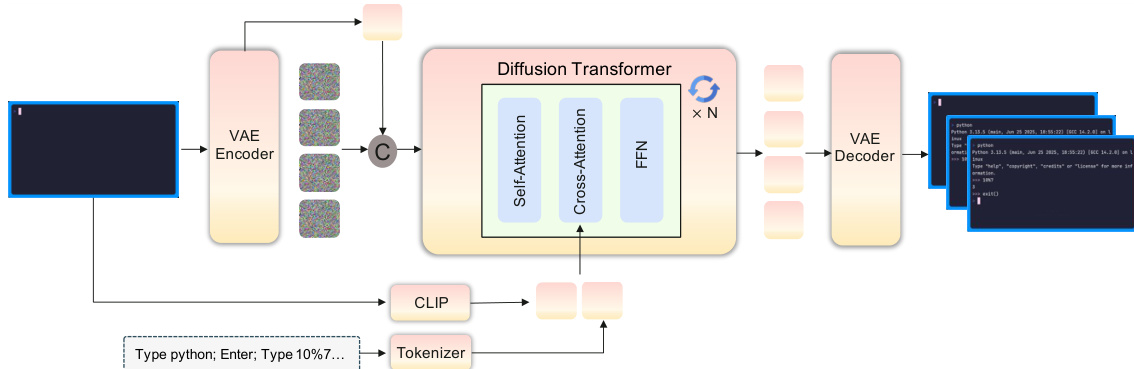
In the GUIWorld setting, the architecture incorporates explicit action-conditioning modules to handle fine-grained interactions such as cursor tracking and keyboard inputs. The authors evaluate two types of encoders: a raw-action encoder that preserves fine-grained event streams and a meta-action encoder that abstracts interactions into a typed schema. To integrate these action features into the diffusion backbone, the authors explore four distinct injection modes.

The four injection modes are:
- External conditioning: Action information modulates the VAE latents before they enter the transformer.
- Contextual conditioning: Action tokens are concatenated with visual tokens, and a structured temporal mask ensures causal alignment.
- Residual conditioning: A lightweight action module applies residual updates to the hidden states at specific transformer layers.
- Internal conditioning: Action cross-attention sub-layers are integrated directly within the transformer blocks.
To ensure high-fidelity cursor rendering, the authors employ an explicit cursor pipeline. Instead of relying solely on global diffusion loss, they render the cursor as a first-class conditioning signal using SVG templates and apply a masked patch loss to supervise the reconstructed cursor region. Furthermore, a temporal contrastive loss is utilized to align the action pathway with the latent video timeline, pushing matching pairs of frame and action features together while accounting for the natural lag between user actions and visual feedback.
Experiment
Evaluations of the neural computer (NC) prototypes demonstrate that the models achieve high-fidelity terminal rendering and character-level accuracy, particularly when using detailed, literal captions for text-to-pixel alignment. While the models struggle with native symbolic reasoning in arithmetic tasks, performance on these probes improves significantly through system-level conditioning and reprompting rather than requiring reinforcement learning. In interactive GUI environments, results indicate that high-quality, goal-directed data and deep action injection schemes are more critical for stable responsiveness than sheer dataset scale. Furthermore, providing explicit visual supervision for cursor dynamics is essential for achieving precise control and overcoming the limitations of abstract coordinate-based encodings.
The authors evaluate different supervision methods for improving cursor control accuracy in a neural computer. Results show that while coordinate-based supervision provides minimal accuracy, explicit visual conditioning significantly enhances precision. Supervision based solely on coordinates yields low accuracy. Adding Fourier features to position data provides only a marginal improvement. Using explicit SVG masks and reference frames leads to a substantial increase in cursor accuracy.

The authors compare two different action encoding methods under an internal injection mode to evaluate their impact on GUI interaction fidelity. Results show that using a structured meta-action representation leads to better performance across all measured post-action metrics compared to a raw event-stream encoding. Meta-action encoding improves structural consistency and reduces temporal distortion compared to raw-action encoding. The API-like representation achieves lower perceptual distance than the event-stream approach. Encoding granularity provides modest improvements relative to the larger gains seen from varying the action injection scheme.

The authors evaluate different action injection schemes to determine how the depth of conditioning affects post-action interface fidelity. Results show that deeper integration of action information into the model backbone leads to better structural consistency and lower temporal distortion. Internal injection achieves the highest structural similarity and lowest temporal distortion among the tested schemes. Residual injection provides the best results in terms of minimizing perceptual distance. Moving from external conditioning to deeper token-level fusion significantly improves both structural and perceptual metrics.

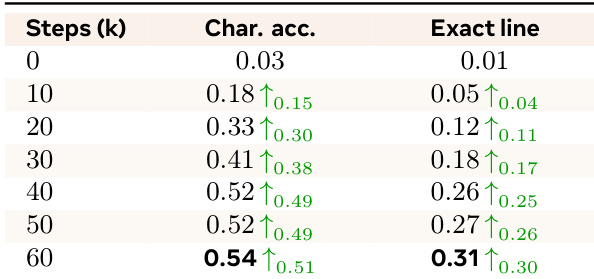
The authors evaluate the character-level text rendering accuracy of their model over the course of training. Results show that both character accuracy and exact-line accuracy improve significantly during the early stages of training before reaching a plateau. Character accuracy increases steadily from initialization through the first 40k steps. Exact-line accuracy shows a consistent upward trend as training progresses. Most performance gains in OCR-based metrics are achieved within the first 40k to 60k steps.
The authors evaluate the symbolic reasoning capabilities of various video models through an arithmetic probe task. Results indicate that most current models struggle significantly with these symbolic operations compared to human performance. Most tested video models show very low accuracy on fundamental arithmetic tasks Sora2 is a notable outlier with significantly higher performance than the other models The low scores suggest that native symbolic reasoning remains a major challenge for these neural computer instantiations

The authors evaluate various components of neural computer performance, including supervision methods, action encoding, injection schemes, text rendering, and symbolic reasoning. Findings indicate that explicit visual conditioning and deeper internal action injection significantly enhance cursor precision and interface fidelity, while structured meta-action representations outperform raw event streams. Although text rendering accuracy improves steadily during early training, most current video models still struggle with fundamental symbolic reasoning tasks.