Command Palette
Search for a command to run...
TriAttention : une compression KV trigonométrique pour un long raisonnement efficace
TriAttention : une compression KV trigonométrique pour un long raisonnement efficace
Weian Mao Xi Lin Wei Huang Yuxin Xie Tianfu Fu Bohan Zhuang Song Han Yukang Chen
Résumé
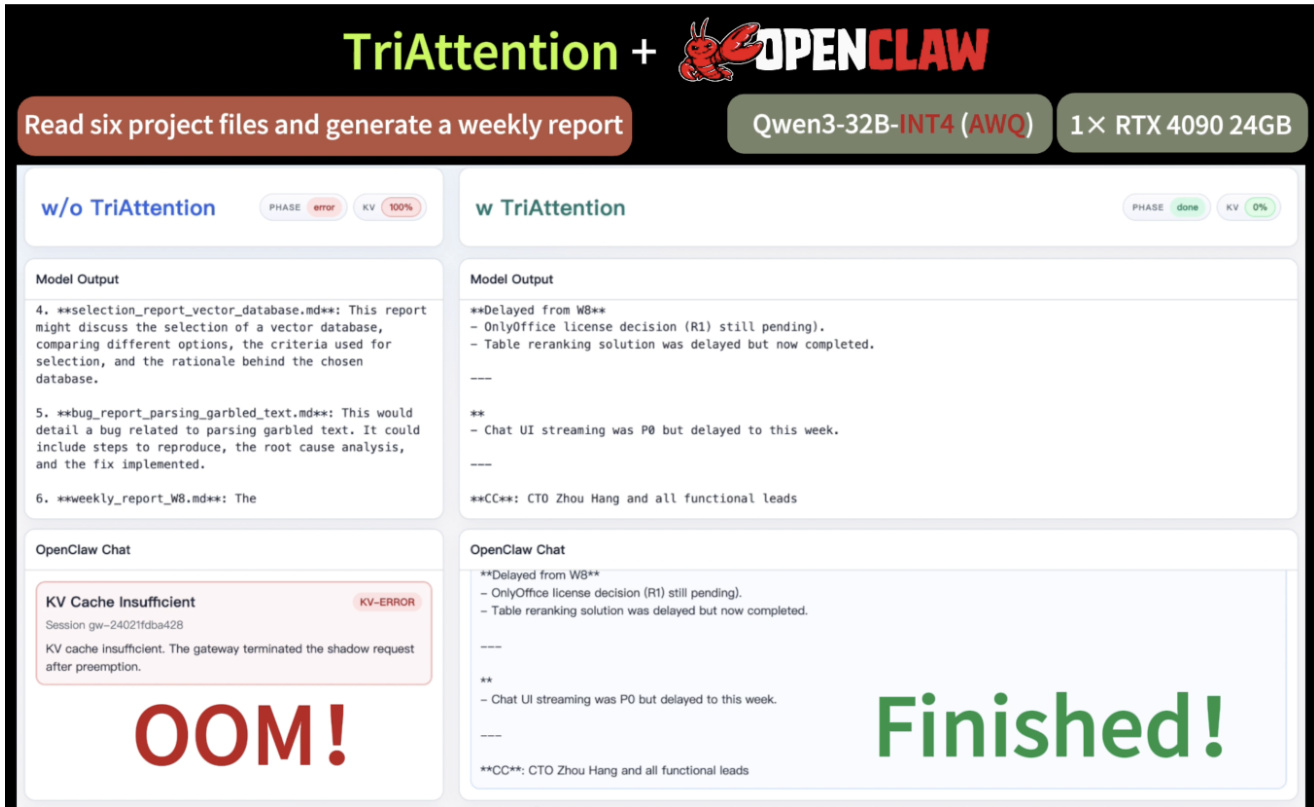
Voici la traduction de votre texte en français, réalisée selon vos exigences de précision technique et de style académique :Le raisonnement étendu dans les grands modèles de langage (LLMs) crée de sévères goulots d'étranglement au niveau de la mémoire du KV cache. Les principales méthodes de compression du KV cache estiment l'importance des KV en utilisant les scores d'attention provenant de requêtes récentes post-RoPE. Cependant, lors du processus RoPE, les requêtes effectuent une rotation avec la position, ce qui réduit considérablement le nombre de requêtes représentatives, entraînant une sélection médiocre des meilleures clés (top-key selection) et une instabilité du raisonnement.Pour éviter ce problème, nous nous tournons vers l'espace pré-RoPE, où nous observons que les vecteurs Q et K sont fortement concentrés autour de centres non nuls fixes et restent stables à travers les positions — un phénomène que nous nommons la concentration Q/K. Nous démontrons que cette concentration amène les requêtes à porter une attention préférentielle aux clés situées à des distances spécifiques (par exemple, les clés les plus proches), les centres déterminant les distances privilégiées via une série trigonométrique.Sur cette base, nous proposons TriAttention pour estimer l'importance des clés en exploitant ces centres. Grâce à la série trigonométrique, nous utilisons la préférence de distance caractérisée par ces centres pour scorer les clés en fonction de leurs positions, tout en exploitant les normes Q/K comme signal supplémentaire pour l'estimation de l'importance.Sur le benchmark AIME25 avec une génération de 32K tokens, TriAttention égale la précision de raisonnement de la Full Attention, tout en atteignant un débit (throughput) 2,5 fois supérieur ou une réduction de la mémoire KV de 10,7 fois, là où les méthodes de référence (baselines) n'atteignent qu'environ la moitié de la précision à efficacité égale. TriAttention permet le déploiement d'OpenClaw sur un seul GPU grand public, là où un contexte long provoquerait autrement une erreur de mémoire (out-of-memory) avec la Full Attention.
One-sentence Summary
To address the instability of post-RoPE importance estimation, researchers propose TriAttention, a KV cache compression method that leverages Q/K concentration in the pre-RoPE space and uses a trigonometric series to model distance-based attention preferences, matching Full Attention accuracy on AIME25 with 32K-token generation while achieving 2.5x higher throughput or 10.7x KV memory reduction.
Key Contributions
- The paper identifies a phenomenon called Q/K concentration in the pre-RoPE space, where query and key vectors cluster around stable, non-zero centers regardless of position.
- This work introduces TriAttention, a method that estimates key importance by using a trigonometric series to characterize distance preferences based on these stable centers and incorporating Q/K norms as an additional signal.
- Experimental results on benchmarks such as AIME25 demonstrate that TriAttention matches Full Attention reasoning accuracy while achieving 2.5x higher throughput or 10.7x KV memory reduction compared to existing baselines.
Introduction
As large language models engage in extended reasoning, the growing KV cache creates significant memory bottlenecks that hinder long-context performance. Existing compression methods typically estimate token importance in the post-RoPE space, but these approaches struggle because positional rotations cause query vectors to shift constantly. This rotation makes it difficult to identify representative queries and leads to unstable importance estimation or the loss of critical directional information. The authors leverage a discovered property called Q/K concentration in the pre-RoPE space, where vectors cluster around stable, fixed centers. By using a trigonometric series to model how these centers determine distance-based attention preferences, they propose TriAttention to estimate key importance more reliably and efficiently.
Dataset
Please provide the paper paragraphs you would like me to summarize. The text provided in your prompt only contains a title and a placeholder sentence regarding a benchmark, which does not contain the necessary technical details (composition, sources, sizes, or processing rules) required to draft the description.
Once you provide the full text, I will generate the concise dataset description following all your requirements.
Method
The authors leverage Rotary Position Embedding (RoPE) to model positional information through rotations in vector space, which is a foundational component of their method. RoPE operates by dividing a d-dimensional vector into d/2 two-dimensional subspaces, each associated with a frequency band f. For each band, a rotation by angle ωfp is applied at position p, where ωf=θ−2f/d and θ=10000 is a fixed constant. This rotation is expressed as a linear transformation on the vector components (x2f,x2f+1), resulting in post-RoPE vectors. The authors observe that queries and keys in the pre-RoPE space are highly concentrated around non-zero centers, a phenomenon consistent across different positions and contexts, as illustrated in the distribution plots shown in the figure below.
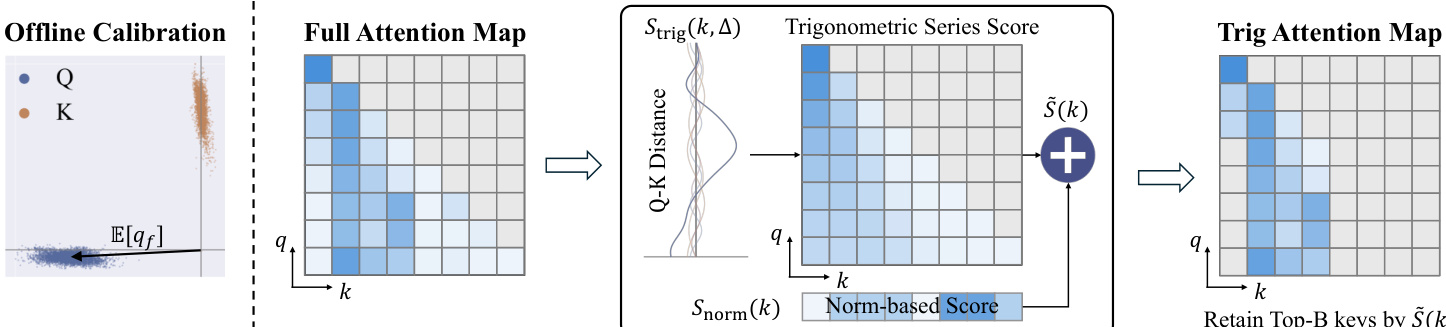
This concentration is quantified using the Mean Resultant Length R=∥E[q]∥/E[∥q∥], where values approaching 1 indicate strong directional concentration. The authors show that this concentration enables the attention computation to be approximated by a trigonometric series. When query and key vectors are approximately constant, the attention logit simplifies to a sum of cosine and sine terms in the relative position Δ=pq−pk, forming a trigonometric series with coefficients determined by the magnitudes and phases of the vectors.
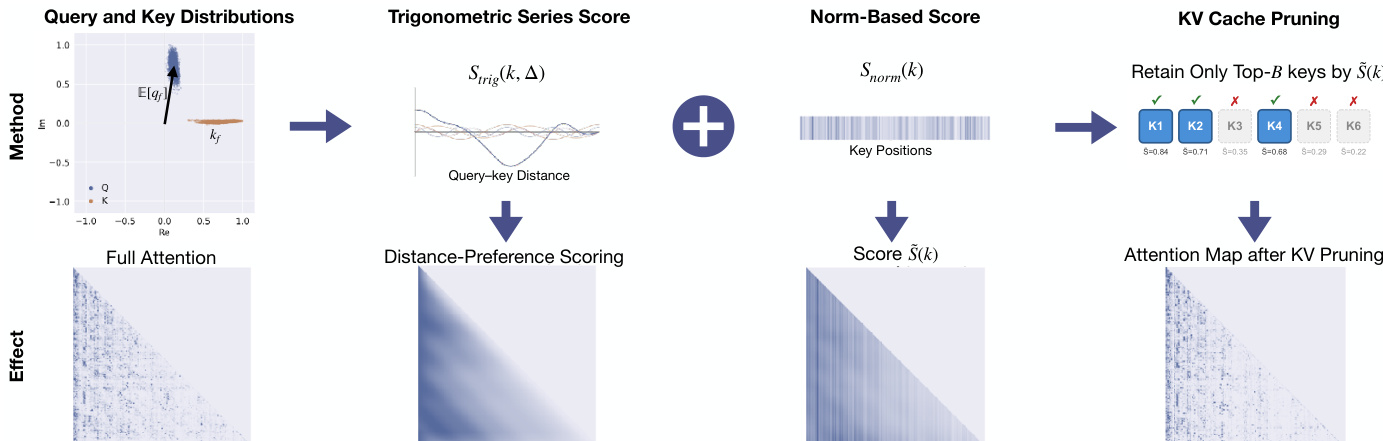
Based on this analysis, the authors propose TriAttention, a KV cache compression method that scores key importance for pruning. The scoring function combines two components: a trigonometric series score Strig and a norm-based score Snorm. The trigonometric series score estimates attention based on distance preference, using the expected query center E[qf] as a proxy for future queries and computing a cosine similarity weighted by vector magnitudes and phase differences. The norm-based score accounts for variations around the center by using the expected query norm E[∥qf∥] and key magnitude ∥kf∥. The final combined score is S(k,Δ)=Strig(k,Δ)+Snorm(k).
To adapt the scoring to varying levels of concentration, the authors introduce an adaptive weighting mechanism. The Mean Resultant Length Rf for each frequency band f is used to scale the norm-based score. When Rf is high (strong concentration), the contribution of Snorm is reduced, emphasizing the trigonometric series. When Rf is low (weak concentration), the full norm contribution is preserved. The final score Sfinal(k) is derived by averaging the score over multiple future query positions and applying a normalize-then-aggregate strategy for Grouped-Query Attention, where scores from different query heads are z-score normalized and combined via a maximum operation.
The method is implemented with window-based pruning, where key scoring and pruning are triggered every 128 generated tokens to reduce computational overhead. Keys are retained based on their final score, and the top-B keys are kept in the KV cache. The overall framework, as illustrated in the figure below, begins with offline calibration to compute query and key distribution centers, followed by the scoring process during inference, and concludes with the retention of top-scoring keys to produce a pruned attention map.
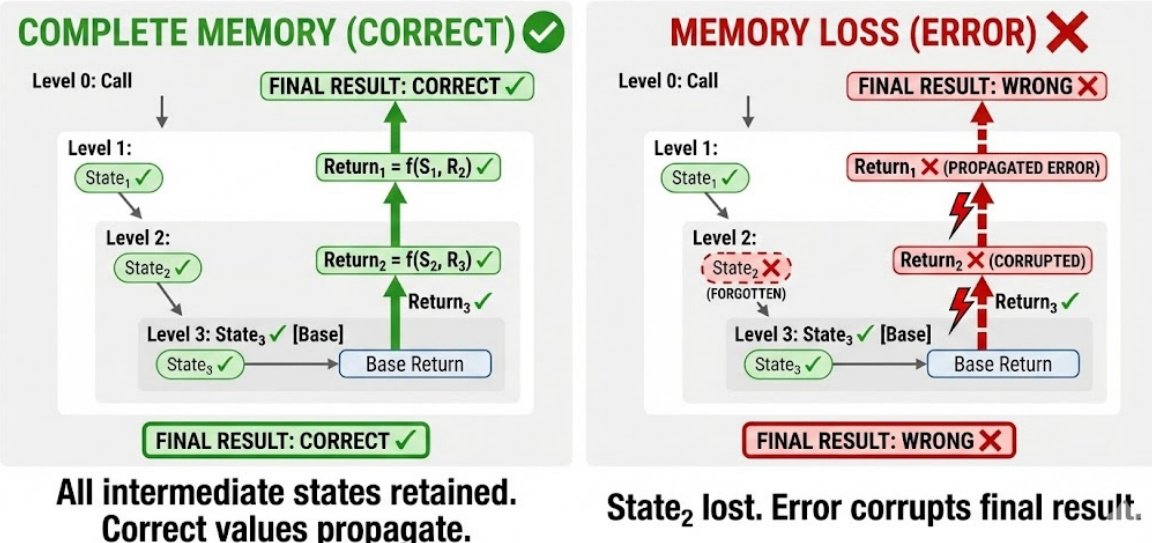
The effectiveness of this approach is demonstrated by its ability to maintain correct memory retention in recursive tasks, where losing intermediate states leads to error propagation and a corrupted final result, as shown in the figure below.
Experiment
The researchers evaluate TriAttention, a KV cache compression method, by testing its ability to reconstruct attention patterns through trigonometric series and its performance on mathematical reasoning, retrieval, and agentic tasks. Experiments across various architectures and benchmarks demonstrate that TriAttention effectively preserves essential information for long-chain reasoning and memory retention while significantly improving throughput and reducing memory footprints. The results show that the method maintains accuracy comparable to full attention even under aggressive compression, outperforming existing observation-based pruning baselines.
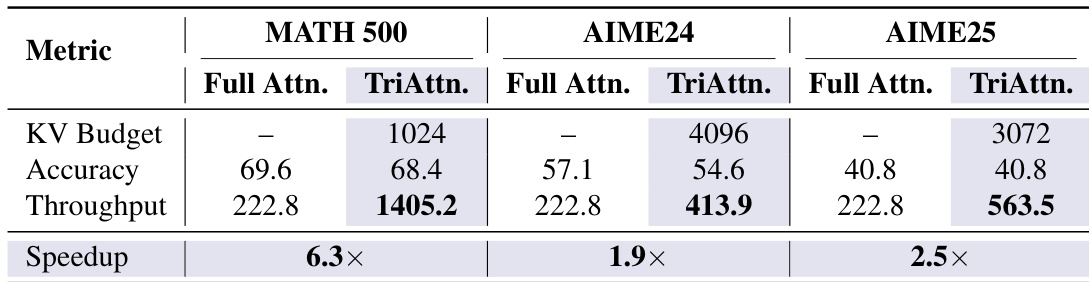
TriAttention achieves significant throughput improvements over Full Attention while maintaining comparable accuracy across multiple benchmarks. The method shows substantial speedup, particularly on MATH 500, and reduces KV cache memory requirements, enabling efficient long-context reasoning. TriAttention achieves up to 6.3× higher throughput than Full Attention on MATH 500. TriAttention matches Full Attention accuracy while reducing KV budget significantly on AIME24 and AIME25. TriAttention enables efficient long-context reasoning, allowing successful task completion within limited GPU memory.
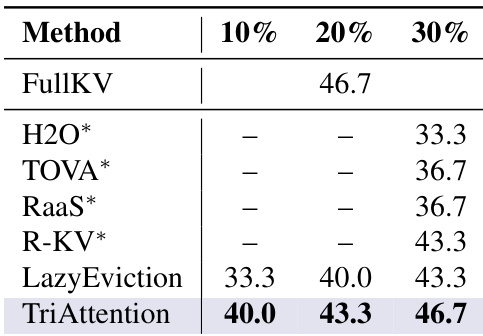
TriAttention achieves the highest accuracy across all tested KV cache budgets compared to other compression methods. It matches or exceeds the performance of FullKV at lower memory usage, demonstrating superior efficiency and accuracy. TriAttention achieves the highest accuracy at all budget levels compared to other methods. TriAttention matches FullKV performance at lower memory usage, showing improved efficiency. TriAttention outperforms all baselines, including H2O, TOVA, and RaaS, across different KV cache budgets.
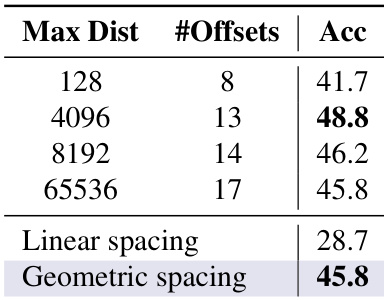
The experiment evaluates the impact of future offset range and spacing strategy on model accuracy. Results show that increasing the maximum distance improves performance, while geometric spacing outperforms linear spacing in maintaining accuracy. Increasing the maximum distance improves accuracy Geometric spacing outperforms linear spacing Accuracy varies with the number of offsets
{"caption": "AIME performance on reasoning and coding", "summary": "The the the table compares performance on AIME24 and AIME25 benchmarks between coding and reasoning tasks. Reasoning tasks show lower performance than coding tasks on both benchmarks, indicating a gap in model capabilities across domains.", "highlights": ["Reasoning tasks achieve lower scores than coding tasks on both AIME24 and AIME25.", "Performance is consistently higher on AIME24 compared to AIME25 for both coding and reasoning tasks.", "The gap between coding and reasoning performance is larger on AIME25 than on AIME24."]
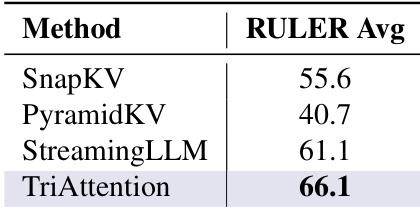
TriAttention achieves the highest average score on the RULER benchmark, surpassing other methods. The results demonstrate superior performance compared to SnapKV and PyramidKV, highlighting its effectiveness in retrieval tasks. TriAttention achieves the highest RULER average score among all methods TriAttention significantly outperforms SnapKV and PyramidKV on RULER TriAttention demonstrates strong retrieval capabilities on the RULER benchmark
TriAttention is evaluated across various benchmarks to validate its throughput, memory efficiency, and retrieval capabilities compared to full attention and existing compression methods. The results demonstrate that TriAttention significantly improves throughput and reduces KV cache requirements while maintaining or exceeding the accuracy of baseline models. Furthermore, ablation studies indicate that performance is optimized through specific offset ranges and geometric spacing strategies.