Command Palette
Search for a command to run...
Auto-distillation par RLVR
Auto-distillation par RLVR
Chenxu Yang Chuanyu Qin Qingyi Si Minghui Chen Naibin Gu Dingyu Yao Zheng Lin Weiping Wang Jiaqi Wang Nan Duan
Résumé
La distillation on-policy (OPD) est devenue un paradigme d'entraînement populaire au sein de la communauté des LLM. Ce paradigme sélectionne un modèle de plus grande capacité comme enseignant afin de fournir des signaux denses et granulaires pour chaque trajectoire échantillonnée, contrairement à l'apprentissage par renforcement avec récompenses vérifiables (RLVR), qui ne reçoit que des signaux épars issus des résultats vérifiables dans l'environnement. Récemment, la communauté a exploré l'auto-distillation on-policy (OPSD), dans laquelle un même modèle joue à la fois le rôle d'enseignant et d'élève, l'enseignant bénéficiant d'informations privilégiées supplémentaires, telles que des réponses de référence, afin de permettre une auto-évolution. Cet article montre que des signaux d'apprentissage dérivés exclusivement de l'enseignant privilégié entraînent une fuite d'information sévère et une instabilité de l'entraînement à long terme. En conséquence, nous identifions le créneau optimal pour l'auto-distillation et proposons RLSD (RLVR avec auto-distillation). Plus précisément, nous exploitons l'auto-distillation pour obtenir des différences de politique au niveau des tokens, afin de déterminer des amplitudes de mise à jour fines, tout en continuant à utiliser RLVR pour dériver des directions de mise à jour fiables à partir des retours de l'environnement (par exemple, la correction de la réponse). Cette approche permet à RLSD de tirer simultanément parti des forces de RLVR et d'OPSD, atteignant ainsi un plafond de convergence plus élevé et une stabilité d'entraînement supérieure.
One-sentence Summary
Researchers from the Chinese Academy of Sciences and JD.COM propose RLSD, a novel training paradigm that combines RLVR with self-distillation to determine fine-grained update magnitudes while maintaining reliable directions from environmental feedback. This approach overcomes information leakage in prior methods, achieving superior stability and faster convergence for LLM post-training.
Key Contributions
- The paper introduces RLSD, a training paradigm that combines RLVR with self-distillation by using environmental feedback to determine reliable update directions while leveraging token-level policy differences from a privileged teacher to modulate update magnitudes.
- This work provides a theoretical proof that information asymmetry in on-policy self-distillation creates an irreducible mutual information gap, explaining why relying solely on privileged teacher signals leads to information leakage and unstable long-term training.
- Experimental results on reasoning tasks demonstrate that the proposed method achieves a higher convergence ceiling and superior stability compared to standard RLVR, reaching performance levels that surpass baselines trained for twice as many steps.
Introduction
Large reasoning models increasingly rely on Reinforcement Learning with Verifiable Rewards (RLVR) to optimize against checkable outcomes, yet this approach suffers from sparse sequence-level signals that fail to distinguish critical reasoning steps from filler tokens. While On-Policy Self-Distillation (OPSD) attempts to solve this by using a model's own privileged outputs as dense training signals, it introduces a fatal information asymmetry where the student learns to leak reference answers it cannot access during inference, causing performance to degrade after initial gains. The authors address this by proposing RLSD, a paradigm that decouples update direction from update magnitude by anchoring gradient directions to reliable environment rewards while using self-distillation solely to modulate the fine-grained intensity of token-level updates.
Dataset
-
Dataset Composition and Sources: The authors train their models on MMFineReason-123K, a challenging subset derived from the larger MMFineReason-1.8M corpus. This dataset focuses on multimodal reasoning problems that require both visual perception and domain knowledge.
-
Key Details and Filtering Rules: The subset was created using a difficulty-based filtering strategy. The authors performed inference on every sample in the original corpus using Qwen3-VL-4B-Thinking with four independent rollouts. They retained only the samples where the model failed on all four attempts. This conservative approach discards trivial examples to concentrate the training signal on difficult problems.
-
Usage in Training: The filtered dataset serves as the primary training data for the Qwen3-VL-8B-Instruct base model. The training setup uses a batch size of 256 with 8 rollouts sampled per prompt at a temperature of 1.0. The maximum context length is set to 8192, split evenly between a 4096 token prompt and a 4096 token response.
-
Processing and Privileged Information: Unlike other methods that require verified reasoning traces or successful rollouts as privileged context, this approach requires only the final ground-truth answer. The teacher model parameters are synchronized with the student model every 10 training steps to maintain a stable self-distillation signal. The evaluation phase utilizes five distinct benchmarks including MMMU, MathVista, MathVision, ZeroBench, and WeMath to assess performance across diverse mathematical and general reasoning capabilities.
Method
The authors propose Reinforcement Learning with Self-Distillation (RLSD) to address the limitations of standard distribution matching approaches like On-Policy Self-Distillation (OPSD). Instead of treating the teacher model as a generative target for behavioral cloning, RLSD repurposes the discrepancy between the teacher and student distributions as a token-level credit assignment signal within a policy gradient framework. This approach allows the model to leverage privileged information (such as reference solutions) to refine the magnitude of updates without compromising the direction of optimization, which remains anchored to the environment's verifiable reward.
The core mechanism of RLSD operates through a three-step process to construct a token-level advantage A^t from a sequence-level advantage A. First, the method computes the privileged information gain Δt at each token position t. This is defined as the stop-gradient difference between the log-probability of the token under the teacher context (conditioned on the question x and privileged information r) and the student context (conditioned only on x):
Δt=sg(logPT(yt)−logPS(yt)).This metric isolates the marginal contribution of the privileged information to the prediction of the specific token generated by the student. A positive Δt indicates that the privileged information supports the token, while a negative value suggests it disfavors it.
Second, the method performs direction-aware evidence reweighting. The authors construct a per-token weight wt by exponentiating the privileged information gain, modulated by the sign of the sequence-level advantage A:
wt=exp(sign(A)⋅Δt)=(PS(yt)PT(yt))sign(A).This formulation ensures that the environment reward retains exclusive authority over the direction of the update (reinforcement vs. penalization), while the teacher's assessment modulates the relative magnitude of credit across tokens within a trajectory. When A>0, tokens supported by the privileged information receive higher weights; when A<0, tokens disfavored by the privileged information bear greater blame.
Refer to the framework diagram below to visualize how the sequence-level advantage and token-level weights are combined to produce the final token-level advantages.
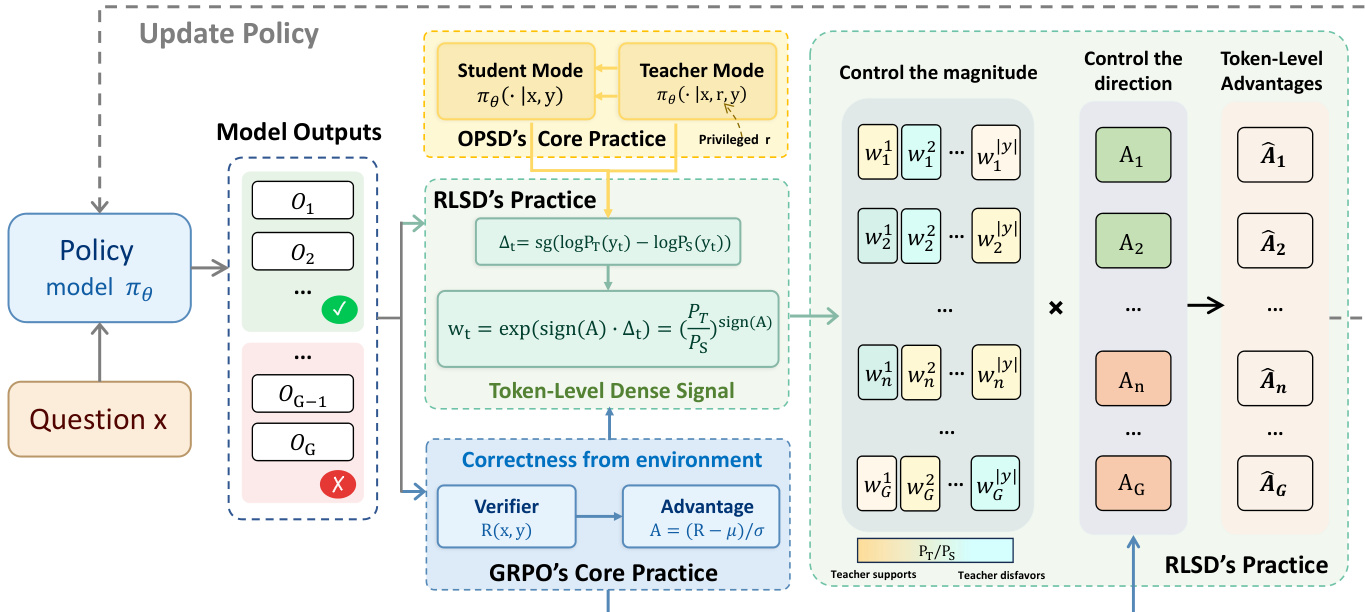
Finally, to ensure training stability, the evidence weights are clipped to bound the maximum influence of any single token, similar to the trust-region constraints in PPO and GRPO. The final token-level advantage A^t is computed as:
A^t=A⋅clip(wt, 1−ϵw, 1+ϵw).The training process follows a standard Group Relative Policy Optimization (GRPO) pipeline with this modified advantage. For each question x, the policy model samples a group of G responses. A verifier provides a binary reward for each response, from which the group-relative sequence-level advantage A is calculated. The model then performs an additional forward pass with the privileged information r to compute the teacher logits and derive the token-level weights wt. The policy parameters θ are updated by maximizing the objective function using the reweighted advantages A^t:
LRLSD(θ)=E⎩⎨⎧G1i=1∑G∣y(i)∣1t=1∑∣y(i)∣min[wtA(i),clip(wt,1−ϵw,1+ϵw)A(i)]⎭⎬⎫.This design allows RLSD to function as a drop-in replacement for the uniform advantage in GRPO, providing dense token-level guidance without introducing auxiliary distillation losses or requiring an external teacher model.
Experiment
- Empirical observations reveal that OPSD-trained models progressively leak privileged information unavailable at inference, leading to performance degradation and stagnation in KL divergence, which indicates an irreducible gap preventing meaningful convergence.
- Main results demonstrate that RLSD outperforms baseline methods including GRPO, OPSD, and SDPO across multimodal reasoning benchmarks by leveraging dense token-level credit assignment to achieve superior accuracy on complex mathematical tasks.
- Training dynamics analysis shows that RLSD avoids the late-stage performance collapse seen in OPSD and prevents the rapid entropy collapse of GRPO by maintaining higher entropy through selective strengthening of critical reasoning tokens.
- Case studies confirm that RLSD effectively redistributes sequence-level rewards to the token level, assigning higher credit to decisive reasoning steps and stronger blame to specific errors while down-weighting generic narration.