Command Palette
Search for a command to run...
Agentic-MME : Ce que la capacité agentic apporte réellement à l'intelligence multimodale ?
Agentic-MME : Ce que la capacité agentic apporte réellement à l'intelligence multimodale ?
Résumé
Les modèles de langage multimodaux (MLLM) évoluent d'observateurs passifs vers des agents actifs, résolvant des problèmes grâce à l'expansion visuelle (invocation d'outils visuels) et à l'expansion des connaissances (recherche sur le web ouvert). Toutefois, les évaluations existantes présentent des lacunes : elles manquent d'intégration flexible des outils, testent les outils visuels et de recherche séparément, et se concentrent principalement sur les réponses finales. Par conséquent, elles ne permettent pas de vérifier si les outils ont été réellement invoqués, appliqués correctement ou utilisés de manière efficace. Pour remédier à ces limites, nous introduisons Agentic-MME, un benchmark vérifié au niveau du processus pour les capacités agentic multimodales. Il comprend 418 tâches réelles réparties sur 6 domaines et 3 niveaux de difficulté, évaluant la synergie des capacités, avec plus de 2 000 points de contrôle étape par étape, nécessitant en moyenne plus de 10 heures d'annotation manuelle par tâche. Chaque tâche intègre un cadre d'évaluation unifié supportant l'exécution de code et d'API dans des environnements isolés (sandbox), ainsi qu'une trajectoire de référence humaine annotée avec des points de contrôle étape par étape selon deux axes : l'axe S et l'axe V. Afin de permettre une vérification véritable au niveau du processus, nous auditons des états intermédiaires fins plutôt que de nous limiter aux réponses finales, et nous quantifions l'efficacité au moyen d'une métrique de « surréflexion » (overthinking) par rapport aux trajectoires humaines. Les résultats expérimentaux montrent que le meilleur modèle, Gemini3-pro, atteint une précision globale de 56,3 %, qui chute significativement à 23,0 % sur les tâches de niveau 3, soulignant la complexité de la résolution de problèmes agentic multimodaux dans des scénarios réels.
One-sentence Summary
Researchers from CASIA, UCAS, SEU, and other institutions introduce Agentic-MME, a process-verified benchmark that uniquely evaluates the synergy of visual expansion and web search in Multimodal LLMs. By auditing fine-grained intermediate states rather than just final answers, it reveals significant performance gaps in complex real-world agentic tasks.
Key Contributions
- The paper introduces Agentic-MME, a process-verified benchmark containing 418 real-world tasks across six domains that evaluate the synergy between visual tool invocation and open-web search through over 2,000 manually annotated stepwise checkpoints.
- A unified evaluation framework is presented that supports both sandboxed code execution and structured tool APIs to audit fine-grained intermediate states along Strategy and Visual Evidence axes, moving beyond simple final-answer correctness.
- Experimental results demonstrate the benchmark's rigor by showing that while the best model achieves 56.3% overall accuracy, performance drops significantly to 23.0% on the most difficult tasks, highlighting the challenges of real-world multimodal agentic problem solving.
Introduction
Multimodal Large Language Models are evolving from passive observers into active agents that combine Visual Expansion with open-web search to solve complex real-world problems. Prior evaluations fall short because they lack flexible tool integration, test visual and knowledge capabilities in isolation rather than synergy, and rely solely on final answer correctness without verifying if tools were actually invoked or applied efficiently. To address these gaps, the authors introduce Agentic-MME, a process-verified benchmark featuring 418 real-world tasks with over 2,000 stepwise checkpoints that enable fine-grained auditing of intermediate states and measure efficiency against human reference trajectories.
Dataset
Agentic-MME Dataset Overview
The authors introduce Agentic-MME, a process-verified benchmark designed to evaluate multimodal agentic capabilities by integrating active visual manipulation with open-web search.
-
Dataset Composition and Sources
- The dataset comprises 418 real-world tasks spanning 6 heterogeneous domains and 35 sub-categories.
- High-resolution, visually complex images are sourced from the open web, specifically curated to include scenarios requiring diverse visual toolkits such as oversized images, low-light environments, folded documents, and steganographic visuals.
- The collection ensures that over 40% of instances require recovering highly localized information occupying less than 10% of the image area.
-
Key Details for Each Subset
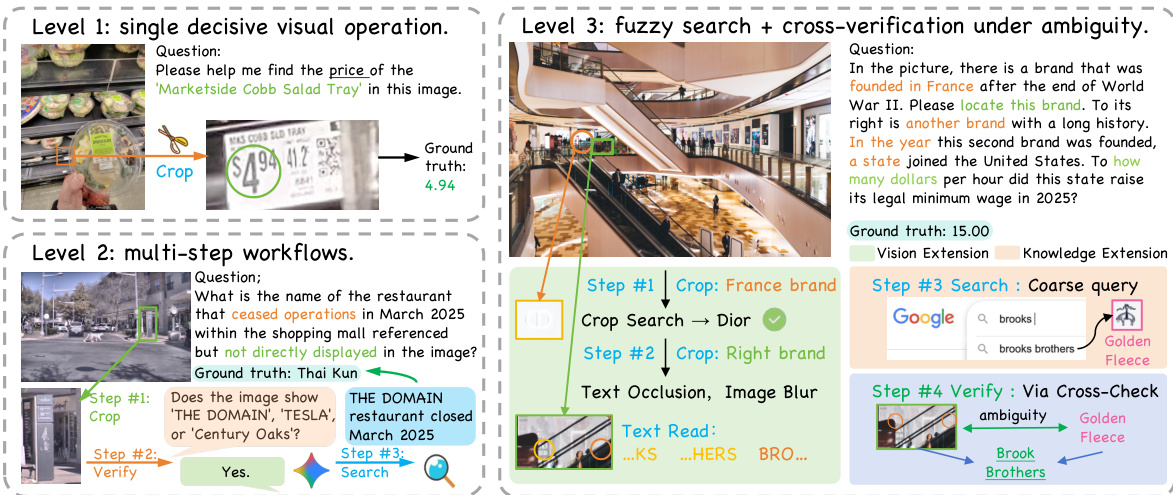
- Level 1 (Visual Expansion Focus): Tasks isolated to a single visual operation like cropping or rotating to surface hidden evidence without external search.
- Level 2 (Visual + Knowledge Expansion): Tasks requiring a simple combination of visual manipulation and web search, typically solvable within three interaction rounds.
- Level 3 (Synergistic Coupling): Advanced scenarios demanding iterative, interleaved execution of visual and search tools to resolve ambiguity or cross-validate hypotheses.
- The benchmark includes 13 distinct visual operations and 4 open-web retrieval tools available to agents.
-
Data Usage and Training Strategy
- The dataset is used for evaluation rather than training, providing a standardized execution harness for both sandboxed Python code and function-calling APIs.
- Evaluation relies on over 2,000 human-annotated stepwise checkpoints to audit intermediate behavior along two axes: the V-axis for visual tool intent and artifact faithfulness, and the S-axis for search strategy and retrieved answer correctness.
- The authors employ an "Overthink" metric to penalize redundant tool calls by comparing agent behavior against human reference trajectories.
-
Processing and Annotation Details
- Model-in-the-Loop Backward Drafting: Annotators use state-of-the-art models to identify visual details missed during passive inspection, then apply tools to isolate evidence and verify the model can perceive the processed image before drafting the final question.
- Granular Step-wise Annotation: Every step in the reference trajectory includes a natural-language intent description, specific tool operations, ground-truth intermediate visual artifacts paired with test questions, and documented search keywords with verified URLs.
- Quality Control: Tasks undergo human-model co-verification where independent verifiers solve tasks end-to-end and models are tested via step-wise oracle guidance to ensure evidence is perceptible.
- Cropping and Coordinate Strategy: Visual operations use normalized coordinates [0-1000] where (0,0) is the top-left, and processed images are tracked by index (e.g., Image 1 corresponds to transformed_image_1.png) to maintain consistency across heterogeneous coding patterns.
Method
The authors propose a process-aware agentic framework designed to handle complex multimodal reasoning tasks through a combination of visual manipulation and external knowledge retrieval. The system categorizes tasks into three distinct levels of complexity to ensure comprehensive evaluation of agent capabilities. Refer to the framework diagram illustrating the progression from single decisive visual operations to multi-step workflows and fuzzy search with cross-verification under ambiguity.
To generate high-quality training and evaluation data, the authors employ a structured pipeline. As shown in the figure below, the process begins with sourcing high-resolution, visually complex images from the open internet. This is followed by backward drafting where a SOTA MLLM verifies perceivability, annotation of intent and tool operations, and finally quality assurance through consensus and audit.

During the reasoning phase, the agent operates in a ReAct pattern, interleaving thought, action, and observation. Each step is accompanied by Visual Ground Truth (V-GT) to ensure the agent correctly isolates relevant regions. Refer to the example of step-by-step reasoning with Visual Ground Truth and Tool Actions, where the agent isolates a black board, enhances contrast, and reads the text "Eat. Drink. Talk."

The framework relies on a standardized, OpenAI-compatible function calling interface for tool execution. Atomic image tools include geometric transformations such as crop, rotate, flip, and resize, as well as enhancement filters like autocontrast, sharpen, and denoise. Additionally, web retrieval tools allow for knowledge expansion via Google Search, Google Lens, and webpage fetching.
Evaluation is performed along two orthogonal axes: Strategy (S-axis) and Visual Evidence (V-axis). The S-axis verifies the correctness of the high-level plan and tool invocation, while the V-axis explicitly checks whether intermediate visual artifacts contain the decisive evidence required to answer the question.
Experiment
- A unified evaluation harness was established to compare heterogeneous agents across two interaction modes: sandboxed code generation and structured atomic tool calls, validating that a standardized artifact protocol enables fair benchmarking despite differing model behaviors.
- Experiments on the Agentic-MME benchmark reveal that all current models fall significantly short of human performance, particularly on complex multi-step tasks, confirming that tools are essential for hard problems but that agents still lack reliable planning and execution capabilities.
- Closed-source models consistently outperform open-source alternatives, with the gap primarily driven by superior search planning and retrieval strategies rather than basic tool invocation skills.
- Structured atomic APIs generally yield higher accuracy and efficiency than code generation by reducing cognitive load and syntax errors, though code mode retains unique potential for flexible, custom visual transformations.
- Analysis of failure modes indicates that models often suffer from reluctance to act, unfaithful execution of visual operations, and overthinking loops, while stepwise human annotations prove effective in guiding better planning without saturating performance.
- Validation studies confirm that the benchmark genuinely requires active visual grounding and synergistic tool use, as tasks cannot be solved by text-only or passive perception alone, and that automated evaluation aligns closely with human judgment.