Command Palette
Search for a command to run...
Kernels de déquantification NF4 rapides pour l'inférence de Large Language Model
Kernels de déquantification NF4 rapides pour l'inférence de Large Language Model
Xiangbo Qi Chaoyi Jiang Murali Annavaram
Résumé
Voici la traduction de votre texte en français, respectant les standards de la rédaction scientifique et technologique :Les Large Language Models (LLMs) ont désormais dépassé la capacité de mémoire des dispositifs GPU uniques, rendant nécessaire l'utilisation de techniques de quantification pour leur déploiement pratique. Bien que la quantification NF4 (4-bit NormalFloat) permette une réduction de la mémoire par un facteur de 4, l'inférence sur les GPU NVIDIA actuels (par exemple, l'Ampere A100) nécessite une déquantification coûteuse vers le format FP16, ce qui crée un goulot d'étranglement critique en termes de performance. Cet article présente une optimisation légère de la mémoire partagée (shared memory) qui comble cette lacune en exploitant de manière rigoureuse la hiérarchie de la mémoire, tout en maintenant une compatibilité totale avec l'écosystème existant. Nous comparons notre technique à l'implémentation open-source BitsAndBytes, en atteignant une accélération du kernel de 2,0 à 2,2× sur trois modèles (Gemma 27B, Qwen3 32B et Llama3.3 70B), et une amélioration end-to-end allant jusqu'à 1,54× en tirant parti de l'avantage de latence de 12 à 15× de la shared memory par rapport à l'accès à la mémoire globale (global memory). Notre optimisation réduit le nombre d'instructions grâce à une logique d'indexation simplifiée, tout en n'utilisant que 64 octets de shared memory par bloc de threads (thread block), démontrant ainsi que des optimisations légères peuvent générer des gains de performance substantiels avec un effort d'ingénierie minimal. Ce travail fournit une solution « plug-and-play » pour l'écosystème HuggingFace, démocratisant l'accès aux modèles avancés sur les infrastructures GPU existantes.
One-sentence Summary
By utilizing a lightweight shared memory optimization to replace expensive global memory access, this method achieves up to 2.2x kernel speedup and 1.54x end-to-end improvement across the Gemma 27B, Qwen3 32B, and Llama3.3 70B models while maintaining full compatibility with the HuggingFace ecosystem.
Key Contributions
- The paper introduces a lightweight shared memory optimization that exploits the memory hierarchy of the Ampere architecture to address dequantization bottlenecks in NF4 quantized models.
- This method transforms redundant per-thread global memory accesses into efficient per-block loading, reducing lookup table traffic by 64x per thread block and simplifying indexing logic to reduce instruction counts by 71%.
- Experimental evaluations on Gemma 27B, Qwen3 32B, and Llama3.3 70B demonstrate 2.0 to 2.2x kernel speedups and up to 1.54x end-to-end performance improvements while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Introduction
As large language models grow beyond the memory capacity of single GPUs, NF4 quantization has become essential for reducing memory footprints by 4x. However, because current NVIDIA Ampere architectures lack native 4-bit compute support, weights must be dequantized to FP16 during every matrix multiplication. This process creates a major performance bottleneck, with dequantization accounting for up to 40% of end-to-end latency due to redundant and expensive global memory accesses. The authors leverage a lightweight shared memory optimization to address this inefficiency by transforming per-thread global memory loads into efficient per-block loads. This approach exploits the significant latency advantage of on-chip memory to achieve a 2.0 to 2.2x kernel speedup while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Experiment
The evaluation uses a single NVIDIA A100 GPU to test optimized NF4 dequantization kernels against baseline implementations across three models: Gemma 27B, Qwen3 32B, and Llama3.3 70B. The experiments validate that the original dequantization process creates a significant bottleneck due to high memory overhead and warp divergence caused by complex tree-based decoding. Results demonstrate that the shared memory optimization consistently accelerates kernel execution, leading to substantial end-to-end latency and throughput improvements that are particularly pronounced in larger models.
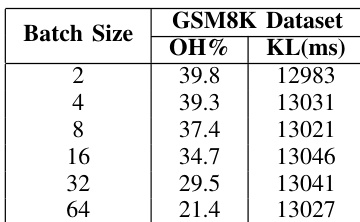
The authors analyze the dequantization overhead and kernel latency for the Qwen3-32B model using the GSM8K dataset. The results show that dequantization remains a significant portion of total inference time across various batch sizes. Dequantization overhead percentage decreases as the batch size increases Kernel latency remains relatively consistent regardless of the batch size The dequantization process represents a substantial bottleneck in end-to-end inference
The authors evaluate the kernel-level speedup of their optimized NF4 dequantization implementation across different model architectures and batch sizes. Results show that the optimization provides consistent performance gains regardless of the specific model or workload scale. The optimization achieves a consistent speedup across all tested models and batch sizes. Larger models and different batch configurations all experience similar levels of kernel-level improvement. The performance gains remain stable across varying batch sizes from small to large workloads.
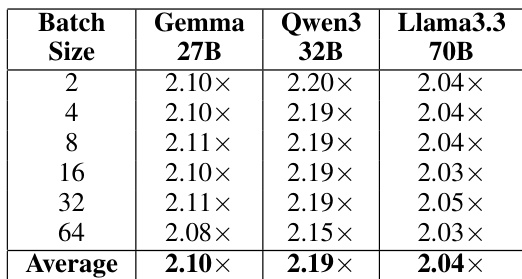
The authors evaluate dequantization overhead and the effectiveness of an optimized NF4 implementation using the Qwen3-32B model and various architectures. While dequantization is identified as a significant bottleneck in end-to-end inference, the optimized kernel provides consistent performance gains across different models and batch sizes. These results demonstrate that the optimization maintains stable speedups regardless of the specific workload scale or model architecture.