Command Palette
Search for a command to run...
Une référence simple pour la compréhension de flux vidéo
Une référence simple pour la compréhension de flux vidéo
Yujiao Shen Shulin Tian Jingkang Yang Ziwei Liu
Résumé
Les méthodes récentes de compréhension de flux vidéo s'appuient de plus en plus sur des mécanismes de mémoire complexes pour traiter des flux vidéo de longue durée. Nous remettons en question cette tendance grâce à une observation simple : une ligne de base à fenêtre glissante, qui alimente un VLM (Vision-Language Model) hors caisse uniquement avec les N images les plus récentes, atteint ou dépasse déjà les performances des modèles de flux publiés. Nous formalisons cette ligne de base sous le nom de SimpleStream et l'évaluons par rapport à 13 lignes de base majeures de LLM vidéo hors ligne et en ligne sur les benchmarks OVO-Bench et StreamingBench. Malgré sa simplicité, SimpleStream offre des performances constamment solides. Avec seulement 4 images récentes, il atteint une précision moyenne de 67,7 % sur OVO-Bench et de 80,59 % sur StreamingBench. Des ablations contrôlées montrent en outre que la valeur d'un contexte plus long dépend de l'architecture de base (backbone) plutôt que d'augmenter uniformément avec l'échelle du modèle, et révèlent un compromis cohérent entre perception et mémoire : l'ajout d'un contexte historique plus étendu peut améliorer la récupération (recall), mais affaiblit souvent la perception en temps réel. Cela suggère que des modules de mémoire, de récupération ou de compression plus puissants ne doivent pas être considérés comme une preuve de progrès, sauf s'ils surpassent clairement SimpleStream selon le même protocole. Nous soutenons donc que les futurs benchmarks de flux devraient séparer la perception des scènes récentes de la mémoire à long terme, afin que les améliorations de performance découlant d'une complexité accrue puissent être évaluées plus clairement.
One-sentence Summary
Researchers from Nanyang Technological University introduce SIMPLESTREAM, a minimal baseline that feeds only recent frames to off-the-shelf VLMs, outperforming complex memory-centric models on OVO-Bench and StreamingBench while revealing a critical perception-memory trade-off.
Key Contributions
- The paper introduces SIMPLESTREAM, a minimal streaming baseline that processes only the most recent N frames with an off-the-shelf VLM, eliminating the need for complex memory banks, retrieval systems, or compression modules.
- Comprehensive evaluations on OVO-Bench and StreamingBench demonstrate that this simple recent-context approach achieves state-of-the-art performance while maintaining lower peak GPU memory usage and competitive latency compared to prior streaming methods.
- Controlled ablation studies reveal that the benefit of longer context is backbone-dependent rather than uniform across model scales, and that adding historical context often improves memory recall at the expense of real-time perception.
Introduction
Streaming video understanding is critical for real-time applications where models must process continuous video feeds under strict causal and memory constraints. Prior research has increasingly relied on complex memory mechanisms, such as external banks, retrieval systems, or compression modules, based on the assumption that managing long-term history requires elaborate architectural designs. However, these sophisticated approaches often yield modest gains while introducing significant computational overhead and a trade-off where enhanced memory recall can degrade real-time scene perception. The authors introduce SIMPLESTREAM, a minimal baseline that feeds only the most recent N frames directly to an off-the-shelf VLM without additional memory or training. They demonstrate that this simple recency-based approach matches or surpasses complex streaming models on major benchmarks like OVO-Bench and StreamingBench, revealing that longer context benefits are backbone-dependent rather than universal and arguing for a new evaluation standard that separates perception from memory performance.
Method
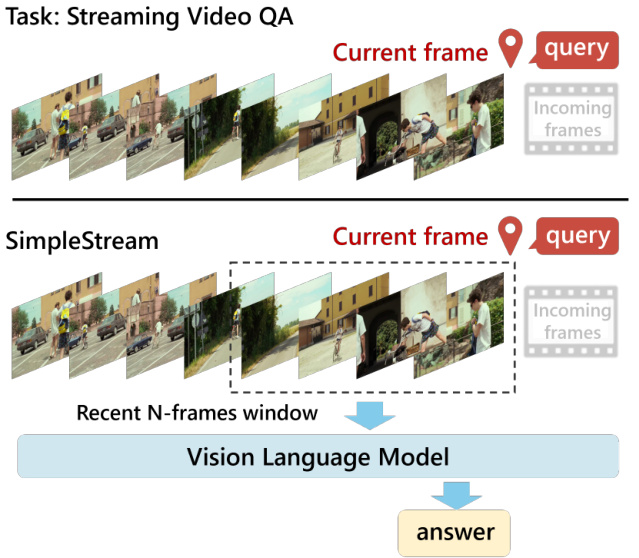
The authors introduce SimpleStream as a deliberately simple baseline designed to isolate the capabilities of current off-the-shelf Vision Language Models (VLMs) using only recent visual context. Unlike prior streaming systems that incorporate mechanisms for managing long-range history, SimpleStream relies on a sliding window approach. Refer to the framework diagram below, which illustrates how the system processes a continuous video stream by selecting a "Recent N-frames window" centered around the current frame to feed into the Vision Language Model.
Let the video stream be represented as a sequence of frames where fi denotes the visual frame at time step i. Given a question qt at time t, the method feeds the base VLM only the most recent N frames and the text query. This process is formalized as:
SIMPLESTREAM(t)=VLM({ft−N+1,…,ft},qt)
By construction, SimpleStream omits additional memory mechanisms, meaning frames outside the sliding window are discarded. Consequently, per-query memory and computation remain bounded by N and do not grow with the stream length. The method introduces no architectural modification, memory module, or additional training; it functions strictly as an inference-time input policy applied to an off-the-shelf VLM.
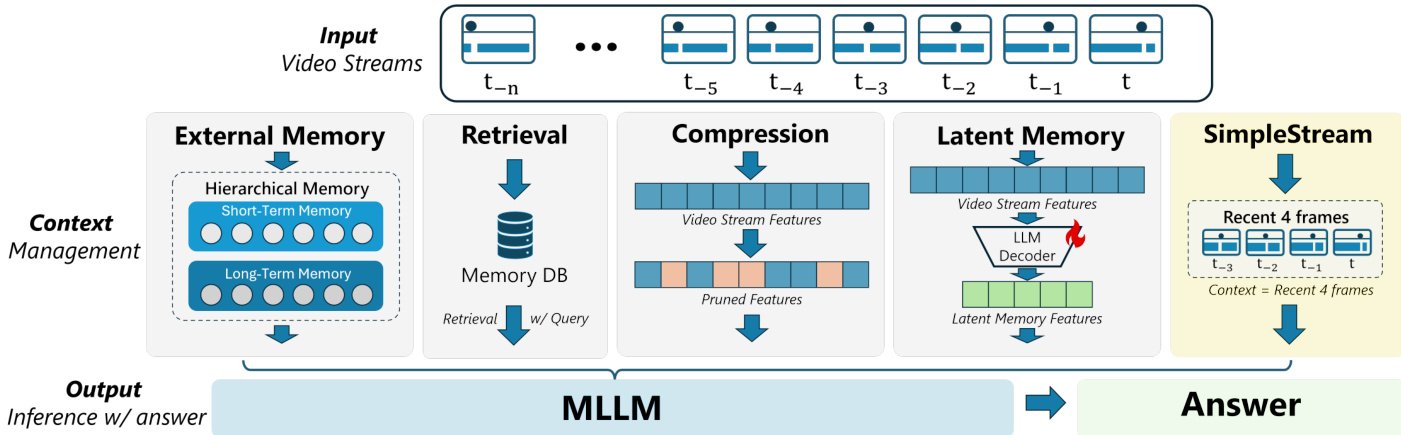
The architectural comparison below highlights how SimpleStream differs from other context management strategies. While alternative approaches utilize External Memory, Retrieval, Compression, or Latent Memory to handle long-term dependencies, SimpleStream bypasses these components entirely. It serves as a controlled reference baseline to determine how much streaming performance can be obtained from recent visual context alone while minimizing confounding effects from additional training or system-level engineering.
Experiment
- Experiments on OVO-Bench and StreamingBench validate that SIMPLESTREAM, a minimalist approach using only a fixed recent frame window, outperforms complex streaming systems with dedicated memory banks or retrieval modules, particularly in real-time visual perception tasks.
- Ablation studies on recency window size and model scale demonstrate that performance does not improve monotonically with longer context; while modest window expansions help, further increases often yield diminishing returns or degradation, indicating that more historical context is not universally beneficial.
- Visual-RAG analysis reveals a distinct perception-memory trade-off where retrieving historical chunks improves episodic memory recall but consistently degrades real-time perception, suggesting that current memory injection techniques often corrupt the model's understanding of the present scene.
- Efficiency evaluations confirm that SIMPLESTREAM maintains low latency and stable GPU memory usage regardless of stream length, proving that persistent historical state is not required for competitive streaming inference.
- Overall conclusions indicate that current benchmarks heavily favor recent perception capabilities, and future progress requires methods that can leverage historical evidence without sacrificing the clarity of current-scene understanding.