Command Palette
Search for a command to run...
Compétence 0 : Apprentissage par renforcement agentic en contexte pour l'intériorisation des compétences
Compétence 0 : Apprentissage par renforcement agentic en contexte pour l'intériorisation des compétences
Zhengxi Lu Zhiyuan Yao Jinyang Wu Chengcheng Han Qi Gu Xunliang Cai Weiming Lu Jun Xiao Yueting Zhuang Yongliang Shen
Résumé
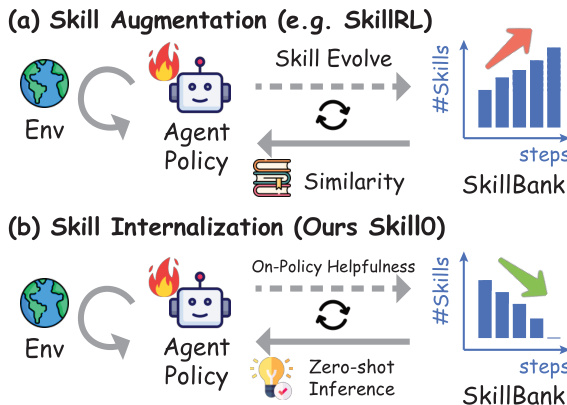
Les compétences d'agent, définies comme des packages structurés de connaissances procédurales et de ressources exécutables chargés dynamiquement par les agents au moment de l'inférence, constituent un mécanisme fiable pour renforcer les agents LLM. Toutefois, le renforcement des compétences au moment de l'inférence présente des limitations fondamentales : le bruit de retrieval introduit des guidages non pertinents, l'injection de contenu de compétence engendre une surcharge substantielle en tokens, et le modèle n'acquiert jamais véritablement les connaissances qu'il se contente de suivre. Nous nous interrogeons sur la possibilité d'intérioriser ces compétences directement dans les paramètres du modèle, afin de permettre un comportement autonome en zero-shot sans aucune recherche de compétences au runtime. Nous présentons SKILL0, un cadre d'apprentissage par renforcement in-context conçu spécifiquement pour l'intériorisation des compétences. SKILL0 met en œuvre un curriculum d'entraînement qui débute avec un contexte de compétence complet et le retire progressivement. Les compétences sont regroupées hors ligne par catégorie et transformées, à l'aide de l'historique des interactions, en un contexte visuel compact, permettant d'enseigner au modèle l'appel d'outils et l'accomplissement de tâches multi-tours. Un Dynamic Curriculum évalue ensuite l'utilité de chaque fichier de compétence selon la politique courante, en ne conservant que celles dont la politique actuelle tire encore bénéfice, dans le cadre d'un budget décroissant linéairement, jusqu'à ce que l'agent opère dans un environnement entièrement zero-shot. Des expériences agentic approfondies démontrent que SKILL0 réalise des améliorations substantielles par rapport à la baseline RL standard (+9,7 % sur ALFWorld et +6,6 % sur Search-QA), tout en maintenant un contexte hautement efficace de moins de 0,5k tokens par étape. Notre code est disponible à l'adresse suivante : https://github.com/ZJU-REAL/SkillZero.
One-sentence Summary
Researchers from Zhejiang University, Meituan, and Tsinghua University propose SKILL0, an in-context reinforcement learning framework that internalizes agent skills into model parameters via a dynamic curriculum. This approach eliminates runtime retrieval noise and token overhead, enabling efficient zero-shot autonomous behavior with significant performance gains on agentic benchmarks.
Key Contributions
- The paper introduces SKILL0, an in-context reinforcement learning framework that formulates skill internalization as an explicit training objective to transition agents from context-dependent execution to fully autonomous zero-shot behavior.
- A Dynamic Curriculum mechanism is presented to evaluate the on-policy helpfulness of each skill file, adaptively withdrawing guidance only when the current policy no longer benefits until the agent operates without any external skill context.
- Extensive experiments on ALFWorld and Search-QA demonstrate that the method achieves substantial performance improvements over standard RL baselines while maintaining an efficient context of fewer than 0.5k tokens per step.
Introduction
Large Language Model agents currently rely on inference-time skill augmentation, where structured behavioral primitives are retrieved and injected into the prompt to guide complex tasks. While effective, this approach suffers from retrieval noise that corrupts context, significant token overhead that limits scalability, and a fundamental dependency where competence resides in the prompt rather than the model itself. The authors propose SKILL0, the first reinforcement learning framework designed to internalize these skills directly into model parameters so that agents operate autonomously without external guidance at inference. They achieve this through In-Context Reinforcement Learning, which provides skill scaffolding during training rollouts and systematically removes it via a Dynamic Curriculum that withdraws support only when the policy no longer benefits from it.
Dataset
-
Dataset Composition and Sources: The authors evaluate their methods on two primary benchmarks: ALFWorld, a text-based game with 3,827 task instances across six household activity categories, and Search-based QA, which aggregates single-hop datasets (NQ, TriviaQA, PopQA) and multi-hop datasets (HotpotQA, 2Wiki, MuSiQue, Bamboogle).
-
Training Data Selection and Splitting: For ALFWorld, the training data follows the split from GiGPO, while Search-QA training draws specifically from NQ and HotpotQA to serve as in-domain data, leaving the remaining QA datasets for out-of-domain evaluation.
-
Training Configuration and Mixture: The Qwen2.5-VL series is trained for up to 180 steps using 4 H800 GPUs. The ALFWorld setup samples 16 tasks with 8 rollouts per prompt and a maximum length of 3,072 tokens, whereas the Search-QA setup samples 128 tasks per batch with a maximum length of 4,096 tokens.
-
Visual Context and Rendering Strategy: The authors construct visual context by rendering text in a monospace font with specific sizing and width constraints (10pt/392px for ALFWorld, 12pt/560px for Search-QA). They apply a semantic color coding scheme where task instructions appear in black, observations in blue, and actions or search queries in red to help the vision encoder distinguish between states, actions, and retrieved content.
-
Curriculum and Skill Initialization: A curriculum learning schedule is implemented with three stages and a validation subset of 1,000 examples. The SkillBank is initialized using skills from SkillRL to provide structured procedural knowledge for both environments.
Method
The authors introduce SKILL0, a framework designed to internalize agent skills into model parameters, enabling zero-shot autonomous behavior without runtime skill retrieval. Unlike traditional skill augmentation which accumulates skills and incurs token overhead, SKILL0 progressively withdraws external guidance. Refer to the framework diagram for a comparison between standard skill augmentation and the proposed skill internalization approach.
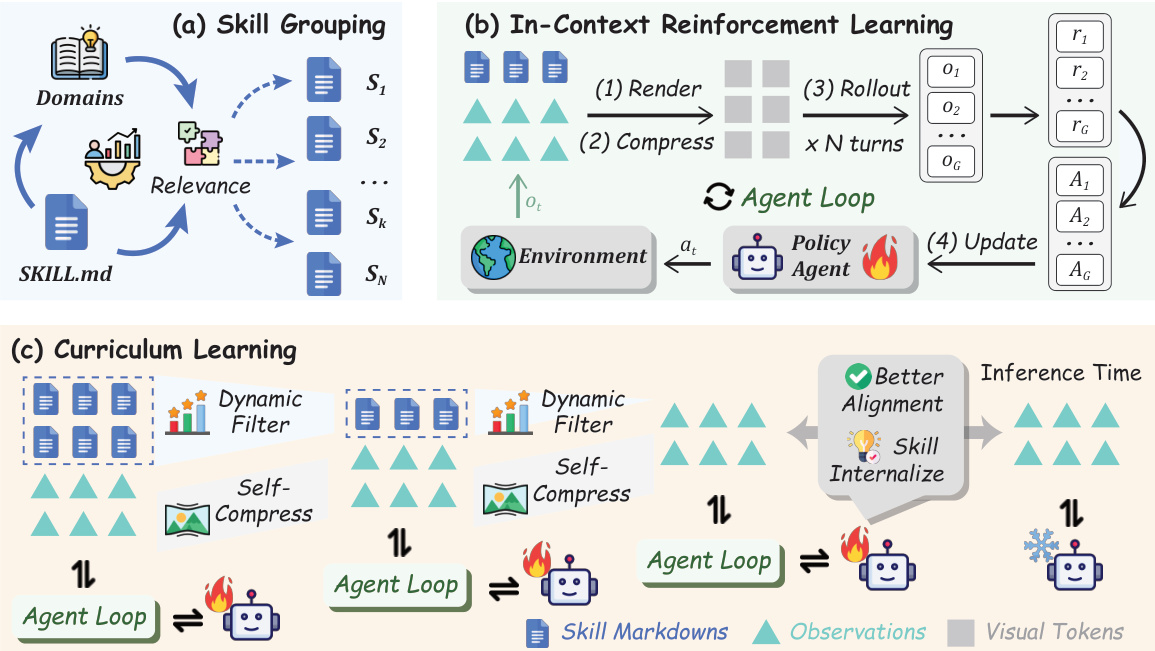
The overall architecture integrates skill grouping, in-context reinforcement learning, and adaptive curriculum learning. As shown in the figure below, the process begins with offline skill grouping where domains are mapped to relevant skill files. During the agent loop, textual interaction history and skills are rendered into a compact visual context. The curriculum learning component dynamically filters skills based on on-policy helpfulness, reducing the skill budget over time until the agent operates in a fully zero-shot setting.
To facilitate this process, the agent is instructed via specific prompts that define the task, history, and required output format. An example of the prompt structure used for search-based QA tasks is provided below.
 The prompt requires the agent to conduct reasoning, select an action such as calling a search engine or providing an answer, and specify the next image compression factor.
The prompt requires the agent to conduct reasoning, select an action such as calling a search engine or providing an answer, and specify the next image compression factor.
The training process utilizes In-Context Reinforcement Learning (ICRL) with a composite reward function that jointly optimizes task success and compression efficiency. The reward is defined as:
rtcomp={ln(ct),0,if Isucc(τ)=1,otherwise,r~t=rt+λ⋅rtcompwhere ct is the compression ratio and λ controls the trade-off. The training objective follows a PPO-style loss:
LSKILL0(θ)=τi∼πθold(q),q∼DE∑i=1G∣τi∣1i=1∑Gt=1∑∣τi∣clip(ri,t(θ),Ai,ϵ)−β⋅DKL[πθ∣∣πref]Adaptive curriculum learning manages the skill context by linearly decaying the skill budget M(s) at each stage s:
∣S(s)∣≤M(s)=⌈N⋅NS−1NS−s⌉This ensures the distribution shift of the policy remains smooth as the agent transitions from relying on external skills to operating independently.
Experiment
- Main performance experiments validate that SKILL0 significantly outperforms zero-shot, skill-augmented, and memory-augmented baselines on ALFWorld and Search-QA, demonstrating successful internalization of complex reasoning and tool-use behaviors into model parameters without relying on external prompts during inference.
- Training dynamics analysis confirms a clear skill internalization trend where models initially benefit from skill scaffolding but gradually achieve superior performance in skill-free settings as the curriculum reduces external support, proving the method learns robust internal knowledge rather than superficial prompt dependency.
- Ablation studies on skill budget and dynamic curriculum design reveal that a progressive annealing strategy with helpfulness-driven filtering is essential for stable learning, as static or unfiltered skill sets lead to performance collapse or over-reliance on prompts, while the proposed approach ensures effective knowledge transfer.
- Token efficiency evaluations show that SKILL0 achieves state-of-the-art results with substantially lower context token costs compared to text-based or skill-augmented methods, highlighting the efficiency gains from visual context modeling and skill internalization.
- Generalization tests on out-of-domain multi-hop datasets demonstrate that the approach maintains strong performance on unseen reasoning tasks without domain-specific adaptation, confirming its robustness and adaptability across diverse benchmarks.