Command Palette
Search for a command to run...
OmniVoice : Vers un Text-to-Speech omnilingue en Zero-Shot avec des Diffusion Language Models
OmniVoice : Vers un Text-to-Speech omnilingue en Zero-Shot avec des Diffusion Language Models
Han Zhu Lingxuan Ye Wei Kang Zengwei Yao Liyong Guo Fangjun Kuang Zhifeng Han Weiji Zhuang Long Lin Daniel Povey
Résumé
Voici la traduction de votre texte en français, respectant les standards de rédaction scientifique et technologique :Nous présentons OmniVoice, un modèle massif de text-to-speech (TTS) multilingue en mode zero-shot, capable de s'étendre à plus de 600 langues. Au cœur de ce système se trouve une architecture inédite de type modèle de langage par diffusion, utilisant une structure discrète non-autoregressive (NAR). Contrairement aux modèles NAR discrets conventionnels, qui souffrent de goulots d'étranglement de performance au sein de pipelines complexes en deux étapes (texte → sémantique → acoustique), OmniVoice effectue une correspondance directe entre le texte et des tokens acoustiques multi-codebooks. Cette approche simplifiée est rendue possible par deux innovations techniques majeures : (1) une stratégie de random masking sur l'ensemble du codebook pour un entraînement efficace, et (2) une initialisation à partir d'un LLM pré-entraîné afin de garantir une intelligibilité supérieure. En exploitant un dataset multilingue de 581 000 heures, entièrement constitué à partir de données open-source, OmniVoice atteint la couverture linguistique la plus large à ce jour et offre des performances de l'état de l'art (state-of-the-art) sur les benchmarks chinois, anglais et multilingues divers. Notre code ainsi que nos modèles pré-entraînés sont mis à la disposition du public.
One-sentence Summary
OmniVoice is a massive omnilingual zero-shot text-to-speech model scaling to over 600 languages that utilizes a novel diffusion language model-style discrete non-autoregressive architecture to directly map text to multi-codebook acoustic tokens through full-codebook random masking and LLM initialization, achieving state-of-the-art performance across Chinese, English, and diverse multilingual benchmarks.
Key Contributions
- The paper introduces OmniVoice, a massive multilingual zero-shot text-to-speech model that utilizes a novel single-stage discrete non-autoregressive architecture to directly map text to multi-codebook acoustic tokens.
- This work implements two key technical innovations, including a full-codebook random masking strategy for training efficiency and the initialization of the model backbone with pre-trained large language models to enhance speech intelligibility.
- Experiments demonstrate that training on a 581k-hour multilingual dataset enables the model to support over 600 languages and achieve state-of-the-art performance in intelligibility, speaker similarity, and naturalness across Chinese, English, and diverse multilingual benchmarks.
Introduction
Zero-shot text-to-speech (TTS) technology is essential for creating high-quality synthetic voices from minimal audio samples, yet most current models are restricted to a small subset of languages. While existing discrete non-autoregressive (NAR) models offer fast inference, they typically rely on complex two-stage pipelines that suffer from error propagation and information bottlenecks. The authors introduce OmniVoice, a massive multilingual zero-shot TTS model that supports over 600 languages using a streamlined single-stage architecture. By leveraging a full-codebook random masking strategy and initializing the backbone with pre-trained large language model (LLM) weights, the authors enable the model to map text directly to acoustic tokens with superior intelligibility and training efficiency.
Dataset
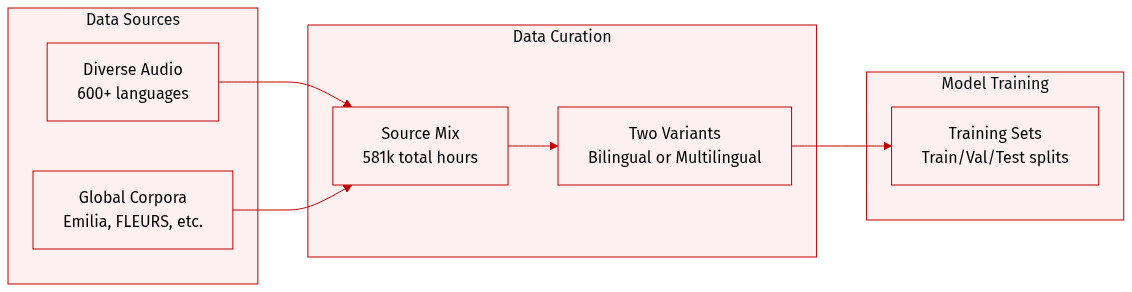
The authors utilize the following data configurations and benchmarks for OmniVoice:
- Dataset Composition and Sources: The training data consists of a massive self-built multilingual corpus totaling 581,000 hours across more than 600 languages. This collection integrates a wide variety of sources, including Emilia, LibriTTS, Common Voice, VoxBox, Meta Omnilingual ASR Corpus, FLEURS, GigaSpeech 2, YODAS-Granary, and numerous regional datasets such as IndicVoices-R, Wenetspeech, and various Arabic and Tibetan corpora.
- Training Configurations: The authors employ two distinct training strategies:
- Bilingual Variant: This version is trained specifically on the Chinese and English subsets of the Emilia dataset. It is designed to facilitate a fair comparison with existing state of the art zero-shot TTS models. In this configuration, prompt denoising is omitted to isolate the architectural advantages.
- Multilingual Variant: This version utilizes the full 581k hour multilingual dataset to support extensive language coverage.
- Evaluation Benchmarks: To assess performance, the authors use four specific benchmarks:
- LibriSpeech-PC: A standard benchmark for English zero-shot TTS.
- Seed-TTS: A bilingual benchmark covering Chinese and English.
- MiniMax-Multilingual-24: A multilingual benchmark spanning 24 languages.
- FLEURS-Multilingual-102: A benchmark using the dev and test splits of the FLEURS dataset to evaluate 102 languages, representing one of the widest language coverage benchmarks for zero-shot TTS.
Method
The authors propose OmniVoice, a single-stage non-autoregressive (NAR) text-to-speech (TTS) model designed with a diffusion language model-style architecture. Unlike traditional two-stage cascaded pipelines that often suffer from error propagation and information bottlenecks, OmniVoice directly maps text to multi-codebook acoustic tokens in an end-to-end fashion.
The architecture of OmniVoice is designed to process multiple input streams to generate high-fidelity speech. The input consists of a text token sequence Y, which is a concatenated sequence of instruct and transcript tokens providing linguistic and task-oriented guidance, and an acoustic token matrix X∈RT×C, where T represents the number of time steps and C represents the number of codebooks. This acoustic matrix is partitioned along the temporal dimension into a prompt segment Xprompt, containing the prefix acoustic context, and a target masked segment Xtarget, where tokens are replaced with a special mask token [M].
Refer to the framework diagram:
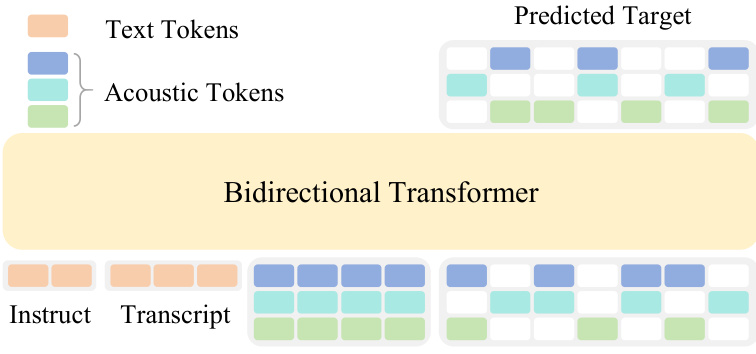
The model utilizes a bidirectional Transformer backbone, initialized with pre-trained LLM weights. Text tokens are processed through a text embedding layer, while acoustic tokens are processed via codebook-specific embedding layers. To integrate the multi-codebook information, the embeddings of all C codebooks at the same temporal position are summed into a unified embedding before being fed into the Transformer. On the output side, the model employs C independent, codebook-specific prediction heads that project the final hidden states to output probability distributions over the vocabulary for each corresponding codebook.
The training process is driven by a discrete diffusion objective. The model is trained to recover the original tokens in the masked positions of Xtarget by leveraging the text conditions Y, the prompt Xprompt, and the unmasked tokens. Let M denote the set of indices (t,c) corresponding to masked positions within the target segment, where t∈{Tp+1,…,T} and c∈{1,…,C}. The training loss L is formulated as:
L=−∑(t,c)∈MlogP(xt,c∣X,Y;θ)
where xt,c is the ground-truth acoustic token at time step t and codebook index c, and P(xt,c∣…;θ) is the probability distribution predicted by the model parameterized by θ.
To enhance training efficiency, the authors move away from conventional per-layer masking schedules, which only optimize a sparse subset of the token matrix per iteration. Instead, OmniVoice adopts a full-codebook random masking strategy. In this approach, a binary mask mi,j∼Bernoulli(pt) is independently sampled for every entry in the T×C token matrix, with the masking ratio pt drawn from a uniform distribution pt∼U(0,1) for each instance. This strategy ensures that, on average, 50% of the tokens are used for loss computation, significantly accelerating convergence and improving generative quality.
Experiment
The evaluation employs a combination of objective metrics for speaker similarity, intelligibility, and naturalness alongside subjective human assessments to validate the OmniVoice model. Experiments across English, Chinese, and extensive multilingual benchmarks demonstrate that the model achieves commercial-grade performance, showing strong generalization even in low-resource language scenarios. Ablation studies further confirm that key architectural choices, such as full-codebook random masking, LLM initialization, and prompt denoising, are essential for optimizing speech quality and linguistic accuracy. Additionally, the model exhibits high inference efficiency, outperforming existing baselines in real-time generation speed.
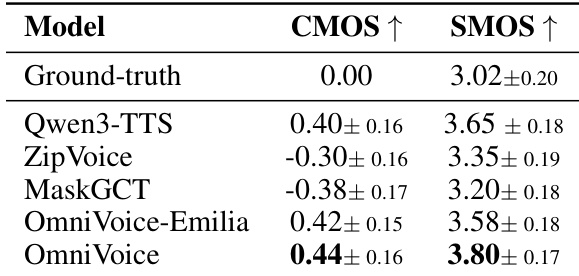
The authors conduct a subjective evaluation comparing OmniVoice and its variants against several state-of-the-art TTS models using CMOS and SMOS metrics. The results demonstrate that OmniVoice achieves superior performance in both relative speech quality and absolute speaker similarity. OmniVoice achieves the highest scores in both CMOS and SMOS among all tested models OmniVoice-Emilia outperforms existing NAR baselines in subjective quality and similarity The multilingual OmniVoice model shows competitive advantages in speaker similarity compared to other baseline models
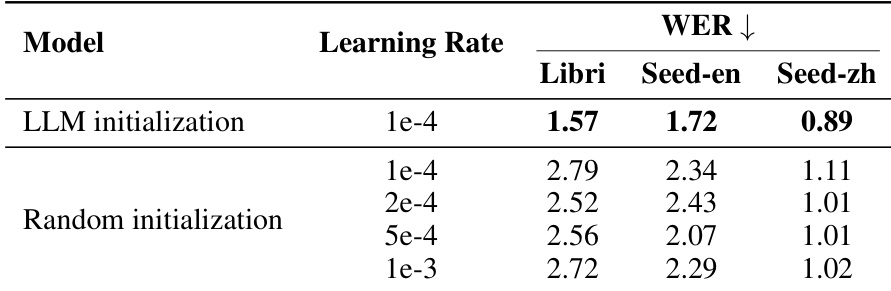
The authors evaluate the impact of LLM initialization on model intelligibility by comparing it against various random initialization configurations. Results show that models utilizing LLM initialization achieve lower word error rates across all tested datasets compared to those with random initialization. LLM initialization consistently yields better intelligibility than random initialization regardless of the learning rate used. The performance advantage of LLM initialization remains superior even after extensive learning rate tuning for the random initialization models. The benefit of inheriting linguistic knowledge from pre-trained LLMs is evident across English and Chinese benchmarks.
The authors evaluate OmniVoice on the FLEURS-Multilingual-102 benchmark to assess its multilingual capabilities. The results show that the model achieves high intelligibility and speaker similarity compared to the ground-truth reference. OmniVoice achieves a lower average character error rate than the ground-truth audio. The model demonstrates high intelligibility with a large number of languages meeting strict error rate thresholds. OmniVoice outperforms the ground-truth in the proportion of languages falling below both 5% and 10% character error rate limits.

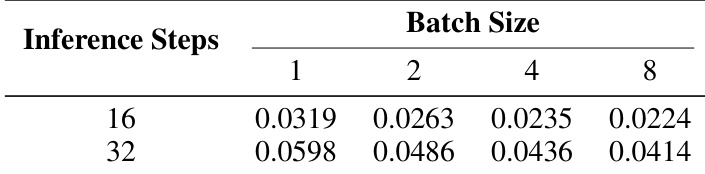
The authors evaluate the inference speed of OmniVoice by measuring the real-time factor across various inference steps and batch sizes. The results show that increasing the batch size reduces the real-time factor, indicating higher efficiency during batch inference. Larger batch sizes lead to a lower real-time factor across all tested inference steps Increasing the number of inference steps results in a higher real-time factor The model demonstrates improved inference efficiency when processing multiple samples simultaneously
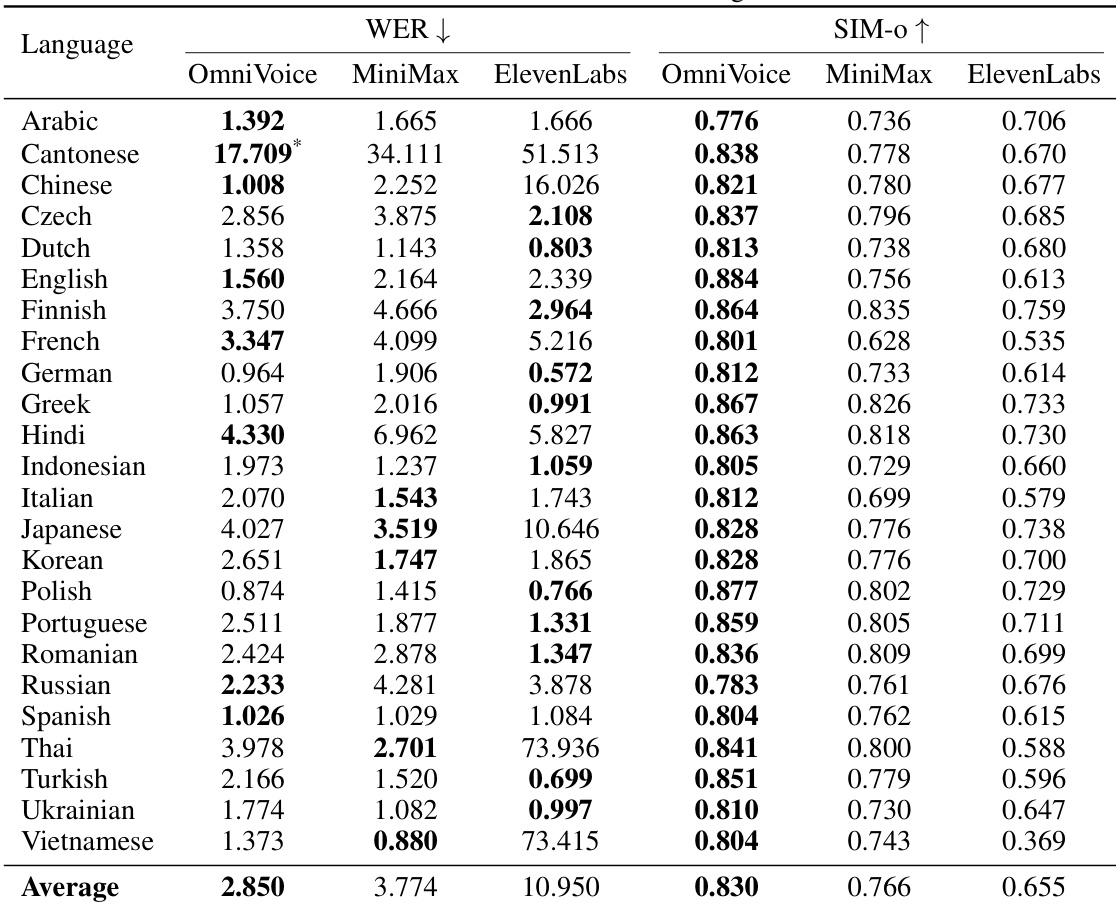
The authors compare OmniVoice against ElevenLabs across various languages using Word Error Rate (WER) and speaker similarity (SIM-o) metrics. The results demonstrate that OmniVoice achieves competitive or superior performance in both intelligibility and speaker similarity across a wide range of languages. OmniVoice achieves a lower average WER compared to ElevenLabs across the evaluated languages. The model shows higher average speaker similarity than the ElevenLabs baseline. OmniVoice maintains strong performance in both intelligibility and similarity across diverse linguistic groups.
The authors conduct a series of subjective and objective evaluations to validate OmniVoice's speech quality, speaker similarity, multilingual capabilities, and inference efficiency. Through comparisons with state-of-the-art models and baselines, the results demonstrate that OmniVoice provides superior intelligibility and similarity across diverse languages, particularly when utilizing LLM initialization to inherit linguistic knowledge. Furthermore, the model exhibits high efficiency during batch inference and maintains competitive performance against commercial benchmarks.