Command Palette
Search for a command to run...
Étude comparative en chirurgie assistée par l'IA : jeux de données, modèles de fondation et obstacles à l'AGI médicale
Étude comparative en chirurgie assistée par l'IA : jeux de données, modèles de fondation et obstacles à l'AGI médicale
Résumé
Les modèles récents d'intelligence artificielle (IA) ont atteint, voire dépassé, les experts humains sur plusieurs benchmarks de tâches biomédicales, mais ils restent en retrait sur les benchmarks d'analyse d'images chirurgicales. Étant donné que la chirurgie nécessite l'intégration de tâches hétérogènes — notamment l'intégration de données multimodales, l'interaction humaine et la prise en compte des effets physiques — des modèles d'IA à capacités générales pourraient s'avérer particulièrement attrayants en tant qu'outils collaboratifs, à condition que leurs performances soient améliorées. D'un côté, l'approche canonique consistant à augmenter la taille de l'architecture et le volume des données d'entraînement est séduisante, d'autant plus que des millions d'heures de vidéos chirurgicales sont générées chaque année. De l'autre, la préparation des données chirurgicales pour l'entraînement de modèles d'IA exige un niveau d'expertise professionnelle nettement supérieur, et l'entraînement sur ces données nécessite des ressources computationnelles coûteuses. Ces compromis dessinent un tableau incertain quant à la capacité et à l'étendue de l'apport que l'IA moderne pourrait offrir à la pratique chirurgicale. Dans cet article, nous explorons cette question à travers une étude de cas portant sur la détection d'instruments chirurgicaux, en utilisant les méthodes d'IA les plus avancées disponibles en 2026. Nous démontrons que, même avec des modèles comportant plusieurs milliards de paramètres et un entraînement extensif, les modèles de vision-langage actuels échouent dans la tâche apparemment simple de détection d'instruments en neurochirurgie. Par ailleurs, nos expériences d'échelle montrent que l'augmentation de la taille des modèles et du temps d'entraînement ne conduit qu'à des améliorations décroissantes des métriques de performance pertinentes. Ainsi, nos résultats suggèrent que les modèles actuels pourraient encore faire face à des obstacles significatifs dans les cas d'usage chirurgicaux. De plus, certains obstacles ne peuvent être simplement « éliminés par mise à l'échelle » avec une puissance de calcul supplémentaire et persistent à travers diverses architectures de modèles, soulevant la question de savoir si la disponibilité des données et des annotations constitue le seul facteur limitant. Nous discutons des principaux contributeurs à ces contraintes et proposons des solutions potentielles.
One-sentence Summary
Researchers from Chicago Booth and the Surgical Data Science Collective demonstrate that scaling Vision Language Models fails to solve surgical tool detection, revealing that specialized architectures like YOLOv12-m significantly outperform billion-parameter systems in neurosurgery and laparoscopy despite massive computational investment.
Key Contributions
- The paper evaluates zero-shot surgical tool detection across 19 open-weight Vision Language Models on the SDSC-EEA neurosurgical dataset, revealing that despite increased model scale, only one model marginally exceeds the majority class baseline.
- A specialized classification head replacing off-the-shelf JSON generation is introduced for fine-tuned Gemma 3 27B, achieving 51.08% exact match accuracy and outperforming the baseline and standard fine-tuning approaches.
- Experiments demonstrate that a specialized 26M-parameter YOLOv12-m model achieves 54.73% exact match accuracy, outperforming all tested Vision Language Models while using 1,000 times fewer parameters and generalizing effectively to the CholecT50 laparoscopic dataset.
Introduction
Surgical AI aims to create collaborative tools capable of integrating multimodal data and physical effects to assist in complex procedures, yet current systems struggle to match human performance on surgical image-analysis benchmarks. While the prevailing scaling hypothesis suggests that increasing model size and training data will solve these issues, prior work faces significant challenges including the high cost of data annotation, the need for specialized expertise, and the risk that simply adding compute cannot overcome domain-specific distribution shifts. The authors leverage a case study on surgical tool detection to demonstrate that even multi-billion parameter Vision Language Models fail to surpass trivial baselines in zero-shot settings and show diminishing returns when scaled, ultimately proving that specialized, smaller models like YOLOv12-m outperform large foundation models with far fewer parameters.
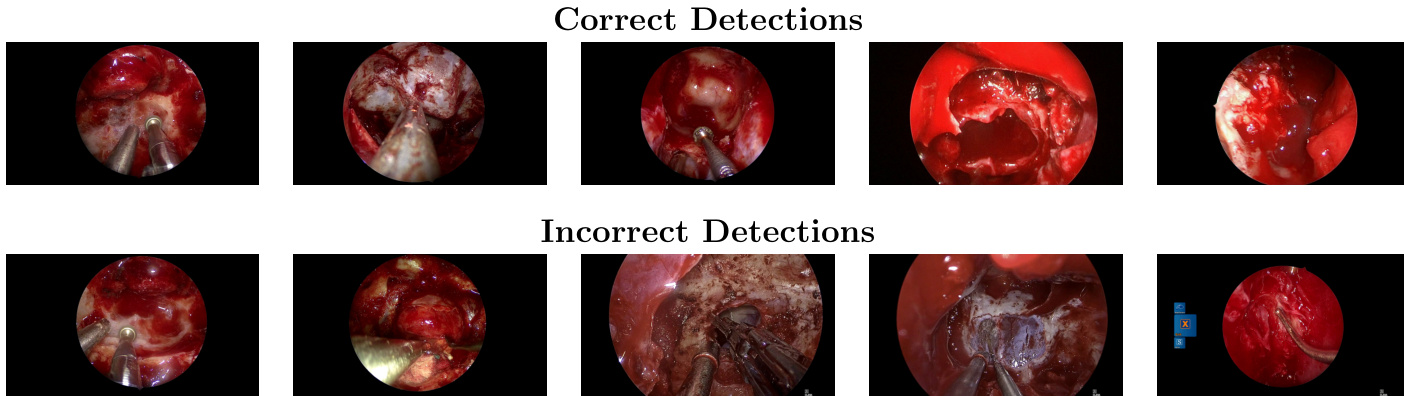
Dataset
-
Dataset Composition and Sources: The authors utilize the SDSC-EEA dataset, which contains 67,634 annotated frames extracted from 66 unique endoscopic endonasal approach (EEA) neurosurgical procedures. These video recordings were donated by 10 surgeons across 7 institutions in the United States, France, and Spain, with no exclusion criteria applied to the selection.
-
Key Details for Each Subset:
- Annotation Quality: Ground truth labels for 31 distinct surgical instrument classes were generated by three non-clinical annotators, reviewed by a senior annotator and SDSC members, with fewer than 10% of frames requiring correction.
- Format and Distribution: Annotations are provided in YOLO format with bounding boxes. The dataset shows significant class imbalance, with Suction appearing in 63.3% of frames, while other tools like Cotton Patty and Grasper appear less frequently.
- Split Strategy: To prevent data leakage, the data is split by surgical procedure rather than individual frames. This results in a training set of 47,618 frames from 53 procedures and a validation set of 20,016 frames from 13 procedures.
-
Usage in the Model:
- Fine-tuning: The training split is used for LoRA fine-tuning of the Vision-Language Model (VLM).
- Zero-Shot Evaluation: The authors evaluate zero-shot VLM performance using a specific prompt template that lists all 31 valid tool names and requires the model to return detected tools in a strict JSON format.
- External Validation: The methodology includes validation on the external CholecT50 dataset to assess generalizability.
-
Processing and Metadata Details:
- Data Leakage Prevention: The procedure-level split ensures that frames from the same surgery never appear in both training and validation sets, leading to uneven tool distributions across splits (e.g., the Sonopet pineapple tip appears only in the training set).
- Labeling Protocol: Annotators received tool descriptions and representative images prior to labeling to ensure consistency, and the final dataset includes multi-label ground truth indicating the presence or absence of instruments in each frame.
Experiment
- Zero-shot evaluation of 19 open-weight vision-language models across two years of development shows that even the largest models fail to surpass a trivial majority class baseline for surgical tool detection, indicating that general multimodal benchmark performance does not transfer to specialized surgical perception.
- Fine-tuning with LoRA adapters improves performance over zero-shot baselines, with a dedicated classification head outperforming autoregressive JSON generation, yet a persistent gap between training and validation accuracy reveals limited generalization to held-out procedures.
- Scaling LoRA adapter rank by nearly three orders of magnitude saturates training accuracy near 99% while validation accuracy remains below 40%, demonstrating that the performance bottleneck is caused by distribution shift rather than insufficient model capacity.
- A specialized 26M-parameter object detection model (YOLOv12-m) outperforms all fine-tuned vision-language models on the primary dataset while using over 1,000 times fewer parameters, suggesting that task-specific data and architecture are more critical than model scale.
- Replication on an independent laparoscopic dataset (CholecT50) confirms that zero-shot performance remains poor, fine-tuning is necessary for high accuracy, and smaller specialized models continue to outperform large foundation models, including proprietary frontier systems.
- The overall findings suggest that progress in surgical AI is currently constrained by the availability of large-scale, standardized domain-specific data rather than the scale of AI architectures, pointing toward hybrid systems that combine generalist models with specialized perception modules.