Command Palette
Search for a command to run...
Génération unifiée de texte vers mouvement sans nombre via l'appariement de flux
Génération unifiée de texte vers mouvement sans nombre via l'appariement de flux
Guanhe Huang Oya Celiktutan
Résumé
Les modèles génératifs excellent dans la synthèse de mouvements pour un nombre fixe d'agents, mais peinent à généraliser lorsque le nombre d'agents varie. À partir de données limitées et spécifiques à un domaine, les méthodes existantes recourent à des modèles autorégressifs pour générer des mouvements de manière récursive, ce qui entraîne une inefficacité et une accumulation d'erreurs. Nous proposons Unified Motion Flow (UMF), composé de Pyramid Motion Flow (P-Flow) et de Semi-Noise Motion Flow (S-Flow). UMF décompose la génération de mouvements indépendamment du nombre d'agents en une étape unique de génération d'un prior de mouvement et en plusieurs étapes de génération de réactions. Plus précisément, UMF exploite un espace latent unifié pour combler l'écart de distribution entre des ensembles de données de mouvements hétérogènes, permettant ainsi un entraînement unifié efficace. Pour la génération du prior de mouvement, P-Flow opère à des résolutions hiérarchiques conditionnées par différents niveaux de bruit, réduisant ainsi les surcoûts computationnels. Pour la génération de réactions, S-Flow apprend un chemin probabiliste conjoint qui effectue de manière adaptative une transformation de réaction et une reconstruction de contexte, atténuant l'accumulation d'erreurs. Des résultats exhaustifs et des études utilisateurs démontrent l'efficacité d'UMF en tant que modèle généraliste pour la génération de mouvements multi-personnes à partir de texte. Page du projet : https://githubhgh.github.io/umf/.
One-sentence Summary
Authors from King's College London propose Unified Motion Flow, a generalist model for multi-person motion generation that replaces inefficient autoregressive methods with a single-pass prior and multi-pass reaction stages. By leveraging a unified latent space and hierarchical noise conditioning, it effectively handles variable agent counts while mitigating error accumulation.
Key Contributions
- The paper introduces Unified Motion Flow (UMF), a framework that utilizes a unified latent space to bridge distribution gaps between heterogeneous motion datasets, enabling effective unified training for number-free text-to-motion generation.
- A Pyramid Motion Flow module is presented to generate motion priors across hierarchical resolutions conditioned on noise levels, which mitigates computational overheads by handling different resolutions within a single Transformer.
- The method incorporates a Semi-Noise Motion Flow component that learns a joint probabilistic path to adaptively perform reaction transformation and context reconstruction, thereby alleviating error accumulation in multi-pass reaction generation.
Introduction
Text-conditioned human motion synthesis is critical for applications like virtual reality and animation, yet existing methods often struggle with scalability and flexibility. Prior approaches typically focus on single or dual-agent scenarios, while unified models that handle variable numbers of actors frequently suffer from inefficiency and error accumulation during autoregressive generation. To address these challenges, the authors propose a unified number-free text-to-motion generation framework based on flow matching that eliminates the need for explicit agent counting and avoids the error propagation issues found in previous multi-person systems.
Dataset
- The authors utilize two primary datasets for evaluating text-conditioned motion generation: InterHuman, which contains 7,779 interaction sequences, and HumanML3D, which includes 14,616 individual sequences.
- Each sequence in both datasets is paired with three textual annotations, while the InterHuman-AS subset adds specific actor-reactor order annotations to the standard InterHuman data.
- The paper employs these datasets strictly for evaluation rather than training, using established metrics such as Frechet Inception Distance (FID), R-precision, Multimodal Distance (MM Dist), Diversity, and Multimodality scores to assess fidelity and variety.
- Model training relies on the AdamW optimizer with an initial learning rate of 10−4 and a cosine decay schedule, utilizing a mini-batch size of 128 for the VAE stage and 64 for the flow matching stages.
- The training process spans 6K epochs for the VAE stage, followed by 2K epochs each for the P-Flow and S-Flow stages, with no specific cropping strategies or metadata construction details mentioned beyond the existing annotations.
Method
The authors propose Unified Motion Flow (UMF), a generalist framework designed for number-free text-to-motion generation. Unlike standard methods restricted to fixed agent counts or autoregressive approaches that suffer from error accumulation, UMF leverages a heterogeneous motion prior as the adaptive start point of the reaction flow path. This design mitigates error accumulation and allows for effective unified training across heterogeneous datasets. Refer to the framework diagram for a visual comparison of naive methods, inherent prior approaches, and the proposed UMF architecture.
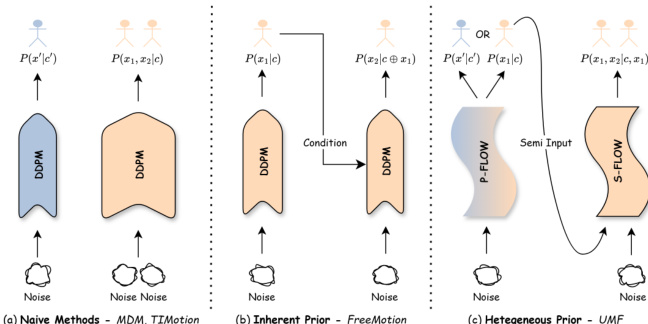
To bridge the distribution gap between heterogeneous motion datasets, UMF establishes a unified latent space. As shown in the figure below, the framework consists of three main stages. The first stage involves a single motion tokenizer that encodes raw motions from heterogeneous datasets into a regularized multi-token latent representation. This VAE-based encoder-decoder utilizes latent adapters to decouple internal token representation from the final latent dimension. The training loss of the VAE is defined as:
LVAE=Lgeometric+Lreconstruction+λKLLKL.This regularized latent space stabilizes flow matching training on heterogeneous single-agent and multi-agent datasets.
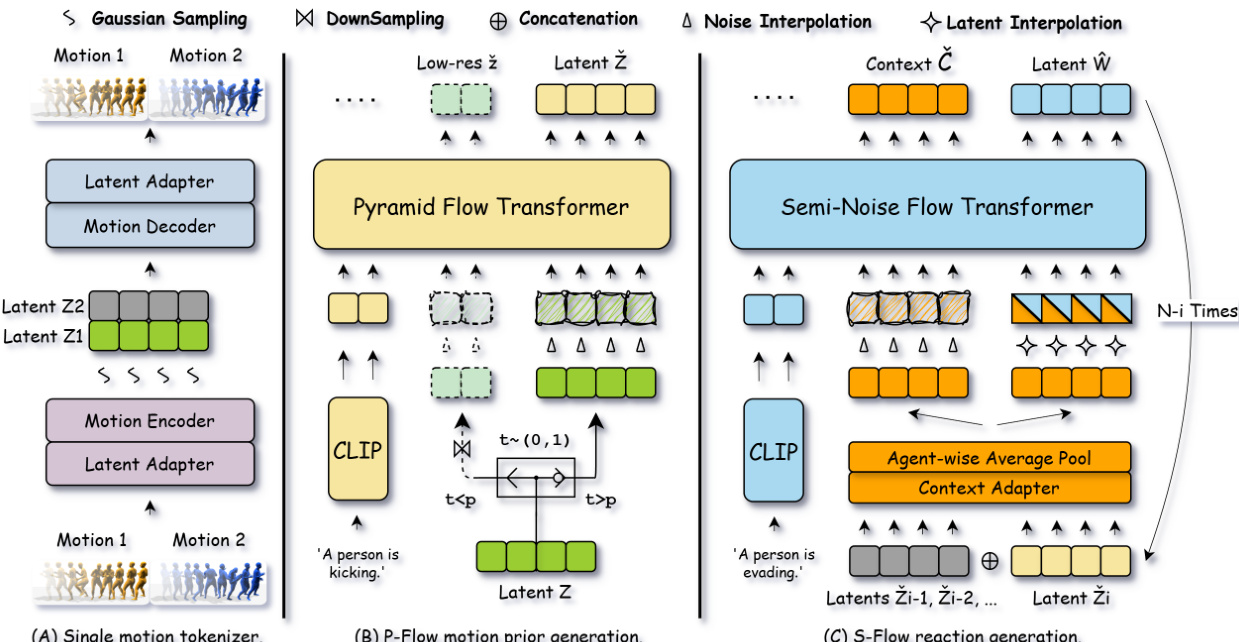
For efficient individual motion synthesis, the authors introduce Pyramid Motion Flow (P-Flow). This module operates on hierarchical resolutions conditioned on the noise level to alleviate computational overheads. P-Flow decomposes the motion prior generation into continuous hierarchical stages based on the timestep. It processes downsampled, low-resolution latents for early timesteps and switches to original-resolution latents for later stages within a single transformer model. The model is trained to regress the flow model GθP on the conditional vector field with the following objective:
LP−Flow=Ek,t,z^ek,z^skGθP(z^t;t,c)−(z^ek−z^sk)2.For reaction and interaction synthesis, the framework employs Semi-Noise Motion Flow (S-Flow). S-Flow learns a joint probabilistic path by balancing reaction transformation and context reconstruction. Instead of using generated motions as a static condition, S-Flow integrates them to define the context distribution. This source distribution initializes the reaction generation path, enabling the model to focus on learning the dynamic transformation between motion distributions while simultaneously reconstructing the context from noise distributions as a regularizer. The S-Flow training objective is a weighted sum of the reaction transformation loss and the context reconstruction loss:
LS−Flow=Ltrans+λreconLrecon.This joint training balances between reaction prediction and context awareness, making the model less prone to error accumulation during autoregressive generation.
Experiment
- Quantitative evaluations on InterHuman and InterHuman-AS benchmarks demonstrate that the method substantially outperforms generalist and specialist baselines in text adherence, motion fidelity, and diversity, validating its superior ability to generate realistic multi-agent interactions.
- Qualitative comparisons and user studies confirm the model's capacity to produce coherent physical interactions and correct agent positioning in complex scenarios, including zero-shot generation for variable group sizes where baseline methods fail.
- Ablation studies validate that leveraging heterogeneous priors from single-agent datasets enhances multi-agent performance, while the proposed latent adapter and multi-token design are essential for effective number-free generation.
- Efficiency analysis reveals that the Pyramid Flow structure significantly reduces computational cost and inference time compared to baselines, with asymmetric step allocation identified as the optimal strategy for balancing speed and quality.
- Component analysis confirms that the semi-noise flow design, context adapter, and reconstruction loss are critical for preventing error accumulation and maintaining high generation fidelity.