Command Palette
Search for a command to run...
PixelSmile : Vers une édition fine des expressions faciales
PixelSmile : Vers une édition fine des expressions faciales
Jiabin Hua Hengyuan Xu Aojie Li Wei Cheng Gang Yu Xingjun Ma Yu-Gang Jiang
Résumé
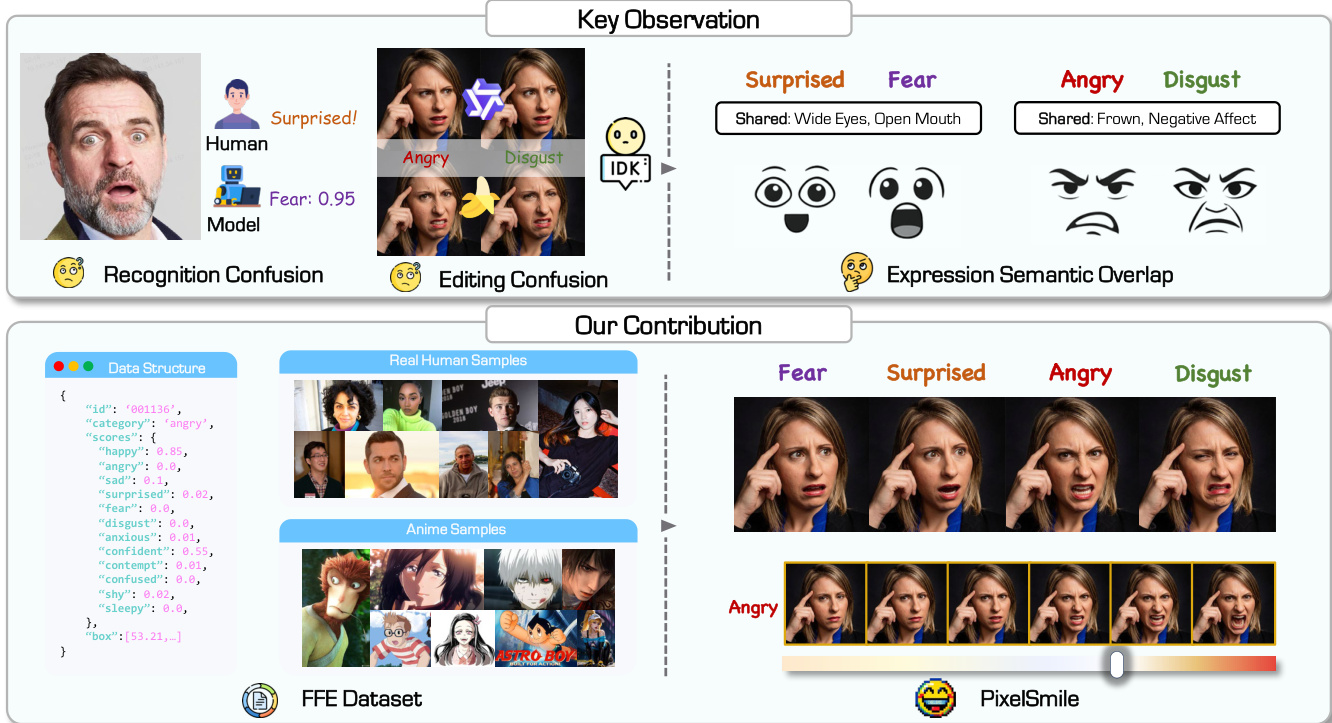
Le montage d'expressions faciales à grain fin a longtemps été limité par un chevauchement sémantique intrinsèque. Pour y remédier, nous avons construit le jeu de données Flex Facial Expression (FFE), doté d'annotations affectives continues, et établi FFE-Bench pour évaluer la confusion structurelle, la précision du montage, la contrôlabilité linéaire ainsi que le compromis entre le montage de l'expression et la préservation de l'identité. Nous proposons PixelSmile, un cadre basé sur Diffusion qui désenchevêtre les sémantiques de l'expression grâce à un entraînement conjoint pleinement symétrique. PixelSmile associe une supervision par l'intensité à un apprentissage contrastif afin de générer des expressions plus intenses et plus distinctives, permettant un contrôle linéaire précis et stable des expressions par interpolation dans l'espace latent textuel. De nombreuses expériences démontrent que PixelSmile offre un désenchevêtrement supérieur et une préservation robuste de l'identité, confirmant son efficacité pour un montage d'expressions continu, contrôlable et à grain fin, tout en supportant naturellement un mélange fluide des expressions.
One-sentence Summary
Researchers from Fudan University and StepFun introduce PixelSmile, a Diffusion framework that resolves semantic overlap in facial editing by employing symmetric joint training and contrastive learning. This approach enables precise, continuous control over expression intensity and seamless blending while robustly preserving identity across real-world and anime domains.
Key Contributions
- The paper introduces the Flex Facial Expression (FFE) dataset with continuous 12-dimensional affective annotations and establishes FFE-Bench to evaluate structural confusion, editing accuracy, linear controllability, and the trade-off between expression editing and identity preservation.
- A novel diffusion framework named PixelSmile is presented, which employs fully symmetric joint training and contrastive learning to disentangle overlapping expression semantics and produce stronger, more distinguishable facial expressions.
- Experiments demonstrate that the proposed method achieves precise and stable linear expression control through textual latent interpolation while maintaining robust identity preservation and supporting smooth expression blending across real-world and anime domains.
Introduction
Facial expression editing is critical for realistic portrait manipulation in applications ranging from digital avatars to content creation, yet current diffusion-based models struggle with fine-grained control. Prior approaches rely on discrete one-hot labels that force continuous human emotions into rigid categories, causing semantic entanglement where similar expressions like fear and surprise become indistinguishable and leading to identity drift during editing. The authors address these limitations by introducing the Flex Facial Expression (FFE) dataset with continuous affective annotations and proposing PixelSmile, a diffusion framework that uses symmetric joint training and textual latent interpolation to disentangle overlapping emotions for precise, linearly controllable editing.
Dataset
-
Dataset Composition and Sources: The authors construct the FFE dataset through a four-stage pipeline to support fine-grained facial expression editing across real-world and anime domains. The final collection comprises 60,000 images, split evenly with 30,000 images per domain. The real-world subset draws from public portrait datasets like the Human Images Dataset and Matting Human Dataset, while the anime subset is curated from 207 productions covering 629 characters.
-
Key Details for Each Subset:
- Real Domain: Contains approximately 6,000 base identities featuring diverse demographics and scene compositions, including close-ups and full-body shots.
- Anime Domain: Includes stylized portraits from various styles such as CG, 2D, chibi, and manga, with a flatter age distribution but higher ambiguity in gender and age labels.
- Expression Variety: Both subsets utilize a structured prompt library for 12 target expressions (six basic and six extended emotions) decomposed into facial attributes to ensure anatomical consistency.
-
Data Usage and Training Strategy:
- Generation: The authors use the Nano Banana Pro image editing model to synthesize multiple target expressions with varying intensities for each base identity.
- Training Framework: A joint fully symmetric training approach is adopted where the model samples a source image and a confusing expression pair to construct triplets.
- Loss Components: The training objective combines a Flow-Matching loss for intensity alignment, a contrastive loss for expression separation, and an identity preservation loss.
- Ablation Study: For comparison, the authors also process the MEAD dataset by sampling front-view frames and mapping discrete intensity levels to continuous values.
-
Processing and Annotation Details:
- Continuous Annotation: Instead of one-hot labels, each image receives a 12-dimensional continuous score vector predicted by the Gemini 3 Pro vision-language model to capture semantic overlap between expressions.
- Quality Control: The pipeline includes automated face detection, manual verification for identity clarity, and consistency checks to remove ambiguous or low-confidence samples.
- Metadata Construction: Prompts based on Qwen3-VL-235B-A22B are used to extract structured semantic attributes, while no personal metadata is retained to ensure privacy and ethical compliance.
Method
The authors propose PixelSmile, a diffusion framework designed for fine-grained facial expression editing that addresses intrinsic semantic overlap. As shown in the figure below, the method leverages the Flex Facial Expression (FFE) dataset with continuous affective annotations to establish a benchmark for structural confusion and editing accuracy.
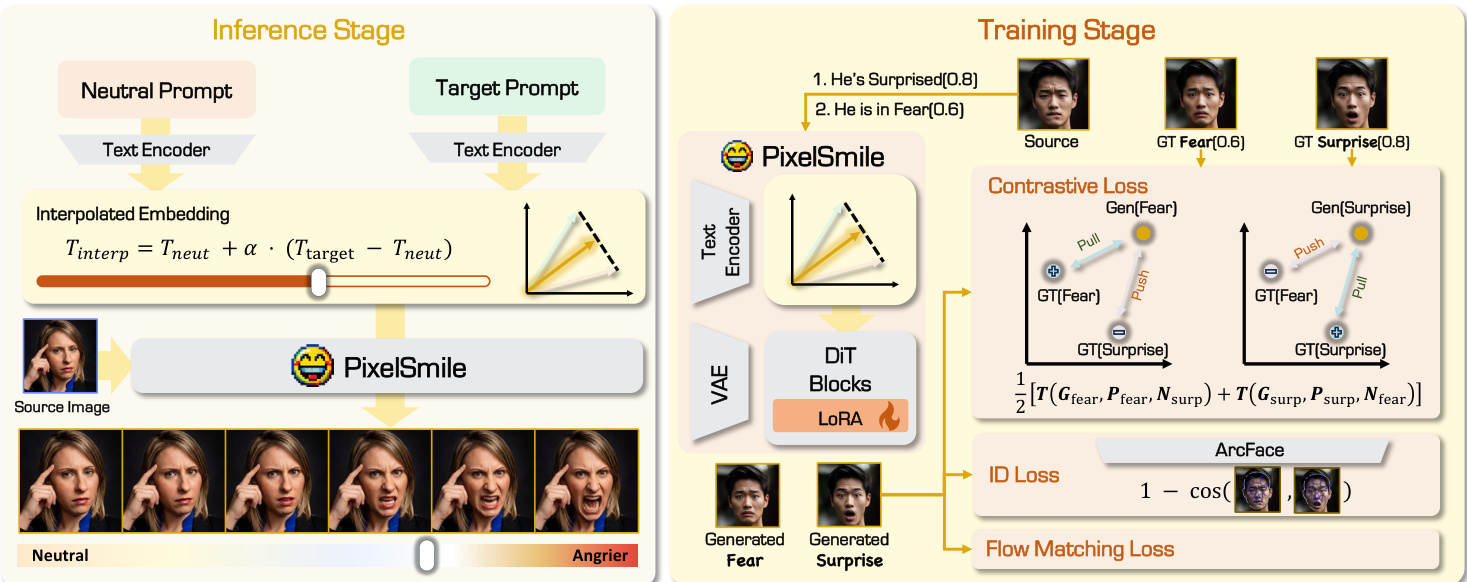
The core architecture builds upon a pretrained Multi-Modal Diffusion Transformer (MMDiT) with LoRA adaptation. To enable continuous intensity control, the authors introduce a textual latent interpolation mechanism. Given a neutral prompt Pneu and a target expression prompt Ptgt, the frozen text encoder maps them to embeddings eneu and etgt. The residual direction Δe=etgt−eneu captures the semantic shift from neutral to the target expression. A continuous conditioning embedding is then constructed as econd(α)=eneu+α⋅Δe, where α∈[0,1] determines the expression strength.
Refer to the framework diagram for the complete training and inference pipeline. The training stage employs a Fully Symmetric Joint Training framework to disentangle expression semantics. The model is fine-tuned under a symmetric dual-branch scheme where a pair of confusing expressions is optimized jointly. The overall objective combines a score-supervised Flow Matching loss, which explicitly couples the interpolation coefficient with visual transformation, and a symmetric contrastive loss. The contrastive loss pulls generated samples toward their target expression while pushing them away from confusing counterparts in the feature space. Additionally, an identity preservation loss based on ArcFace is applied to stabilize biometric features during strong intensity extrapolation.
Experiment
- The FFE-Bench benchmark was established to evaluate facial expression editing across structural confusion, the trade-off between expression strength and identity preservation, control linearity, and editing accuracy.
- Comparisons with general editing models demonstrate that the proposed method achieves superior expression editing accuracy and significantly reduces semantic confusion between similar expressions while maintaining natural identity fidelity.
- Evaluations against linear control models reveal that the method enables smooth, monotonic expression transitions across a wide intensity range, effectively avoiding the identity collapse or unstable responses seen in existing baselines.
- Ablation studies confirm that identity loss is essential for preventing facial attribute drift, while contrastive loss is critical for disentangling semantically overlapping expressions, with a symmetric training framework providing the most stable optimization.
- User studies and qualitative analyses validate that the method offers the best balance between editing continuity and identity consistency, while also supporting the generation of plausible compound expressions through linear interpolation.