Command Palette
Search for a command to run...
WildWorld : un jeu de données à grande échelle pour la modélisation dynamique du monde avec actions et état explicite en vue de la génération d'ARPG
WildWorld : un jeu de données à grande échelle pour la modélisation dynamique du monde avec actions et état explicite en vue de la génération d'ARPG
Zhen Li Zian Meng Shuwei Shi Wenshuo Peng Yuwei Wu Bo Zheng Chuanhao Li Kaipeng Zhang
Résumé
La théorie des systèmes dynamiques et l'apprentissage par renforcement considèrent l'évolution du monde comme des dynamiques d'état latent pilotées par des actions, les observations visuelles fournissant une information partielle sur l'état. Les modèles de monde vidéo récents tentent d'apprendre ces dynamiques conditionnées par l'action à partir de données. Cependant, les jeux de données existants répondent rarement à ces exigences : ils manquent généralement d'espaces d'action diversifiés et sémantiquement significatifs, et les actions y sont directement liées aux observations visuelles plutôt que médiatisées par des états sous-jacents. Par conséquent, les actions sont souvent entrelacées avec des changements au niveau des pixels, ce qui rend difficile pour les modèles l'apprentissage de dynamiques mondiales structurées et le maintien d'une évolution cohérente sur des horizons temporels longs. Dans cet article, nous proposons WildWorld, un jeu de données à grande échelle pour la modélisation de mondes conditionnée par l'action, doté d'annotations explicites d'état et automatiquement collecté à partir d'un jeu de rôle d'action AAA photoréaliste (Monster Hunter: Wilds). WildWorld contient plus de 108 millions d'images et propose plus de 450 actions, incluant les déplacements, les attaques et l'exécution de compétences, accompagnées d'annotations synchronisées par image des squelettes des personnages, des états du monde, des poses de caméra et des cartes de profondeur. Nous dérivons également WildBench pour évaluer les modèles selon deux critères : le suivi des actions (Action Following) et l'alignement des états (State Alignment). Des expériences extensives révèlent des défis persistants dans la modélisation d'actions riches sémantiquement et dans le maintien de la cohérence des états sur de longs horizons, soulignant la nécessité d'une génération vidéo consciente de l'état. La page du projet est disponible à l'adresse : https://shandaai.github.io/wildworld-project/.
One-sentence Summary
Researchers from Alaya Studio and multiple universities introduce WildWorld, a 108-million-frame dataset from Monster Hunter: Wilds featuring explicit state annotations to overcome the limitations of existing video models that struggle with long-horizon consistency and semantically rich action spaces.
Key Contributions
- The paper introduces WildWorld, a large-scale video dataset containing over 108M frames from a photorealistic AAA game, which provides explicit ground-truth annotations for player actions, character skeletons, world states, camera poses, and depth maps to support state-aware world modeling.
- This work presents WildBench, a benchmark designed to evaluate interactive world models using two specific metrics: Action Following to measure agreement with ground-truth sub-actions and State Alignment to quantify the accuracy of state transitions via skeletal keypoints.
- Extensive experiments conducted on WildBench compare baseline models against existing approaches, revealing current limitations in state transition modeling and offering insights for improving long-horizon consistency in generative ARPG environments.
Introduction
Understanding how the world evolves is central to building AI agents capable of long-horizon planning and reasoning, yet current approaches struggle because they rely on datasets with limited action semantics and lack explicit state information. Prior work often treats actions as direct visual changes or infers latent states implicitly from noisy observations, which fails to capture critical internal variables like ammunition counts that drive future outcomes. To address these gaps, the authors introduce WildWorld, a large-scale dataset of over 108M frames from a photorealistic game that provides explicit ground-truth annotations for actions, skeletons, and world states. They also present WildBench, a new benchmark with Action Following and State Alignment metrics, to rigorously evaluate how well models can disentangle state transitions from visual variations and maintain consistency over time.
Dataset
-
Dataset Composition and Sources: The authors introduce WildWorld, a large-scale dataset automatically collected from the AAA action role-playing game Monster Hunter: Wilds. It contains over 108 million frames featuring more than 450 distinct actions, including movement, attacks, and skill casting. The data captures diverse interactions across 29 monster species, 4 player characters, and 4 weapon types within 5 distinct environmental stages.
-
Key Details for Each Subset:
- Observations: Includes RGB frames, lossless depth maps, and synchronized camera poses (intrinsic and extrinsic parameters).
- States and Actions: Provides explicit ground truth such as character skeletons, absolute locations, rotations, velocities, animation IDs, and gameplay attributes like health and stamina.
- Annotations: Features 119 annotation columns per frame, including fine-grained action-level captions and sample-level summaries generated by large language models.
- WildBench: A derived benchmark subset of 200 manually curated samples designed to evaluate action following and state alignment, covering both cooperative and one-on-one combat scenarios.
-
Data Usage and Processing:
- Collection Pipeline: The authors utilize an automated gameplay system that navigates menus and leverages rule-based companion AI to generate diverse combat and traversal trajectories without human intervention.
- Synchronization: A custom recording system based on OBS Studio and Reshade captures RGB and depth streams simultaneously, embedding timestamps to align data from multiple sources.
- Training Application: The dataset supports training action-conditioned world models by providing structured state dynamics rather than relying solely on visual observations.
-
Filtering and Construction Strategies:
- Quality Filters: The authors apply multi-dimensional filters to remove low-quality samples, including discarding clips shorter than 81 frames, eliminating temporal gaps exceeding 50 ms, and removing sequences with extreme luminance levels.
- Occlusion Handling: Samples with camera occlusions (detected via spring-arm contraction) or severe character overlap (exceeding 30% projected area) are excluded to ensure visual clarity.
- Caption Generation: Hierarchical captions are created by segmenting samples into action sequences, sampling frames at 1 FPS, and using a vision-language model to generate detailed descriptions enriched with action and state ground truth.
- Visual Cleanup: The pipeline disables HUD shaders to produce clean, HUD-free frames that better reflect the game world for model training.
Method
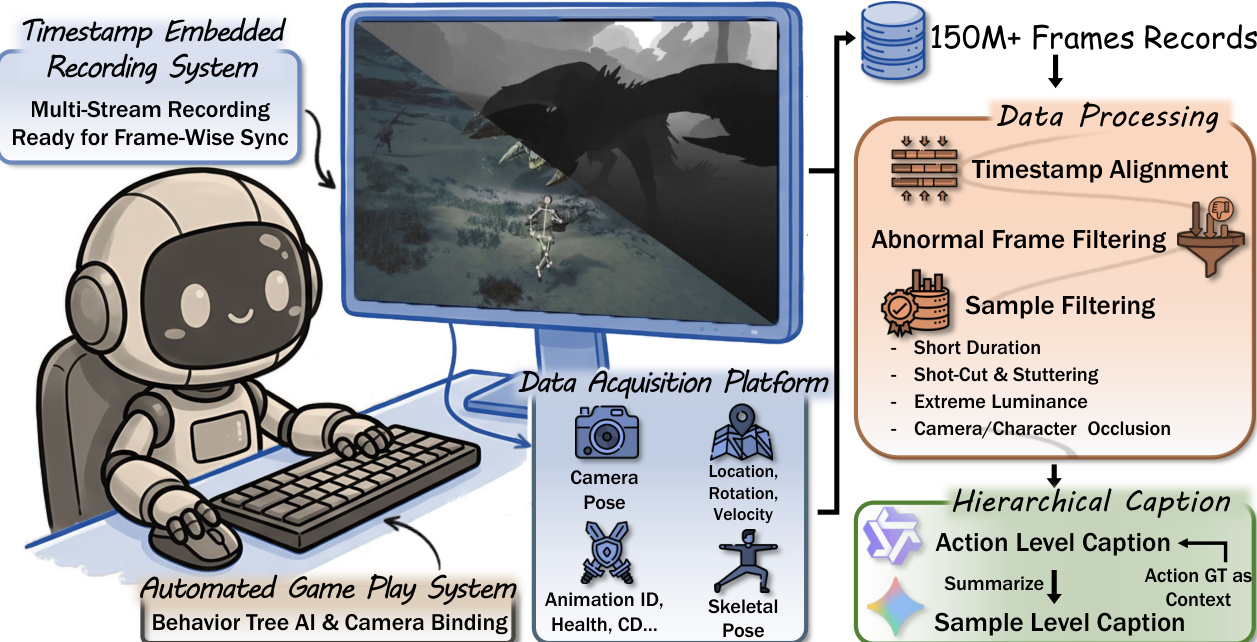
The authors establish a robust data foundation through an automated game play system designed for high-fidelity recording. Refer to the framework diagram. This system employs a timestamp-embedded recording mechanism to ensure frame-wise synchronization across multiple data streams. The Data Acquisition Platform captures diverse modalities including camera pose, location, rotation, velocity, animation IDs, health status, and skeletal pose. Following collection, the data undergoes a rigorous processing pipeline involving timestamp alignment and filtering for abnormal frames and samples with issues such as short duration, shot-cuts, extreme luminance, or occlusion.
Building upon this dataset, the authors develop three distinct video generation approaches. For camera-conditioned generation, they fine-tune the Wan2.2-Fun-5B-Control-Camera model using ground-truth per-frame camera poses, creating the CamCtrl model. This contrasts with baseline approaches that rely on rule-based conversions of discrete actions. For skeleton-conditioned generation, the SkelCtrl model is introduced. This approach utilizes per-frame 3D skeleton keypoints projected into screen coordinates under the ground-truth camera pose to render colored-skeleton videos as control signals for the Wan2.2-Fun-5B-Control model.
The most comprehensive approach is the state-conditioned StateCtrl model. This architecture injects structured state information into the video generation process. States are categorized into discrete types, such as monster type and weapon category, and continuous types, such as coordinates and health. Discrete states are mapped via trainable embeddings, while continuous states are encoded using an MLP. The authors adopt a hierarchical modeling strategy that distinguishes between entity-level states and global-level states, such as recording time. A Transformer architecture models the relationships between entities to produce a unified state embedding. This embedding is aligned with video frames and injected into the intermediate layers of the DiT as a conditioning signal. To ensure the quality of these representations, a state decoder recovers state information from the embedding, and a state predictor forecasts the next-frame state. During training, decoder loss and predictor loss are applied to preserve state fidelity and enhance temporal consistency. For inference, the model supports autoregressive prediction of subsequent states based on the first frame's ground-truth state, denoted as StateCtrl-AR.
All models are trained at a resolution of 544×960 with 81 frames per sample at a frame rate of 16 FPS. The training process utilizes a batch size of 1 and a learning rate of 1×10−5, running for 250,000 iterations with a batch size of 8 using the Adam optimizer. During inference, the system maintains the same resolution and frame rate while employing 50 sampling steps.
Experiment
- WildBench benchmark validates interactive world models by evaluating video quality, camera control, action following, and state alignment, distinguishing itself from existing benchmarks that focus primarily on perceptual quality.
- Reliability experiments confirm that the proposed Action Following metric aligns with human judgments at 85% agreement, while the State Alignment metric effectively measures consistency between generated and ground-truth state evolution.
- Comparative evaluations demonstrate that diverse approaches trained on the WildWorld dataset outperform baselines on interaction-related metrics, proving the dataset's utility for improving camera control and action responsiveness.
- Analysis reveals that standard video quality metrics like VBench are saturated and fail to capture nuanced differences in dynamic motion, whereas action and state metrics provide necessary fine-grained assessment.
- Qualitative findings indicate a trade-off where models using visual signals for control achieve better interaction fidelity but suffer from reduced aesthetic and image quality compared to those using learned embeddings.
- Experiments on autoregressive models show promise for future development but currently exhibit degraded action following due to error accumulation in iterative state prediction.