Command Palette
Search for a command to run...
SpecEyes : Accélération des LLMs multimodaux agentic grâce à une perception et une planification spéculatives
SpecEyes : Accélération des LLMs multimodaux agentic grâce à une perception et une planification spéculatives
Haoyu Huang Jinfa Huang Zhongwei Wan Xiawu Zheng Rongrong Ji Jiebo Luo
Résumé
Les modèles de langage multimodaux (MLLM) dotés de capacités agentic (par exemple, OpenAI o3 et Gemini Agentic Vision) atteignent des performances remarquables en matière de raisonnement grâce à l'appel itératif d'outils visuels. Cependant, les boucles en cascade de perception, de raisonnement et d'appel d'outils introduisent une surcharge séquentielle significative. Cette surcharge, qualifiée de « profondeur agentic », entraîne une latence prohibitive et limite sévèrement la concurrence au niveau du système. Pour y remédier, nous proposons SpecEyes, un cadre d'accélération spéculative au niveau agentic qui brise ce goulot d'étranglement séquentiel. Notre idée centrale est qu'un MLLM léger, sans outil, peut servir de planificateur spéculatif pour prédire la trajectoire d'exécution, permettant ainsi une terminaison anticipée de chaînes d'outils coûteuses sans compromettre la précision. Pour réguler cette planification spéculative, nous introduisons un mécanisme de contrôle cognitif fondé sur la séparabilité des réponses, qui quantifie la confiance du modèle en une auto-vérification sans nécessiter d'étiquettes de référence (oracle). Par ailleurs, nous concevons un entonnoir parallèle hétérogène qui exploite la concurrence sans état du petit modèle pour masquer l'exécution sérielle avec état du grand modèle, maximisant ainsi le débit du système. Des expériences extensives sur les benchmarks V* Bench, HR-Bench et POPE démontrent que SpecEyes réalise un gain de vitesse de 1,1 à 3,35 fois par rapport à la ligne de base agentic, tout en préservant, voire en améliorant, la précision (jusqu'à +6,7 %), augmentant ainsi le débit de service dans des charges de travail concurrentes.
One-sentence Summary
Researchers from Xiamen University, University of Rochester, and The Ohio State University propose SpecEyes, an agentic-level speculative acceleration framework that employs a lightweight tool-free MLM as a planner to predict execution trajectories. This approach reduces sequential overhead in multimodal LLMs through cognitive gating and parallel funnels, achieving significant speedups while maintaining accuracy on complex reasoning benchmarks.
Key Contributions
- The paper introduces SpecEyes, an agentic-level speculative acceleration framework that employs a lightweight, tool-free model to predict execution trajectories and bypass expensive tool chains for queries that do not require deep reasoning.
- A cognitive gating mechanism based on answer separability is presented to quantify model confidence for self-verification, enabling reliable switching between the small speculative model and the large agentic model without requiring oracle labels.
- Experiments on V* Bench, HR-Bench, and POPE demonstrate that the approach achieves a 1.1 to 3.35 times speedup over agentic baselines while preserving or improving accuracy, alongside increased serving throughput under concurrent workloads.
Introduction
Agentic multimodal LLMs achieve superior reasoning by iteratively invoking visual tools, yet this process creates a severe efficiency crisis where strict data dependencies between perception and reasoning steps cause latency to explode and prevent GPU batching. Prior optimization methods like token-level speculative decoding or token pruning fail to address this issue because they only accelerate individual steps within the fixed, serial tool-use loop rather than questioning the necessity of the loop itself. The authors leverage a lightweight, tool-free model to speculate on answers for queries that do not require deep tool interaction, introducing SpecEyes as the first framework to lift speculative acceleration from the token level to the agentic level. By employing a novel cognitive gating mechanism based on answer separability to verify confidence and a heterogeneous parallel funnel to mask serial execution, SpecEyes bypasses expensive tool chains for simple queries while preserving or improving accuracy.
Method
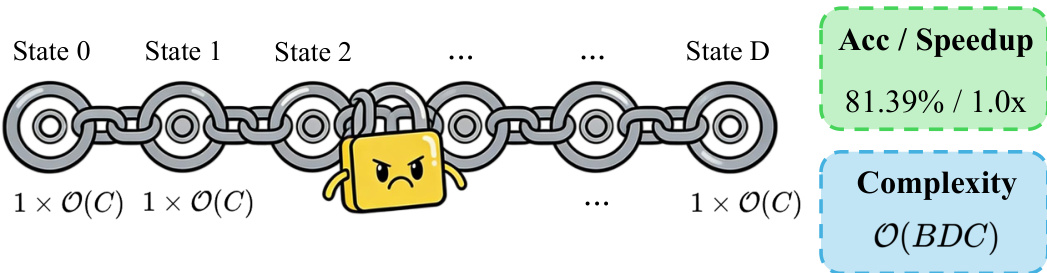
The authors formalize the agentic multimodal large language model (MLLM) as a stateful reasoning system where the model maintains a state trajectory over multiple reasoning steps. A critical property of this system is that subsequent tool selections depend causally on prior observations, creating a strict data dependency. This dependency renders the agentic pipeline inherently sequential, as step d+1 cannot begin until step d completes. Consequently, the end-to-end latency for a single query scales linearly with the agentic depth.
To address this bottleneck, the authors propose SpecEyes, a four-phase speculative acceleration framework designed to bypass expensive tool chains whenever a smaller, non-agentic model is sufficiently confident. The pipeline processes a batch of queries through a funnel that splits them into tool-free and tool-required paths.
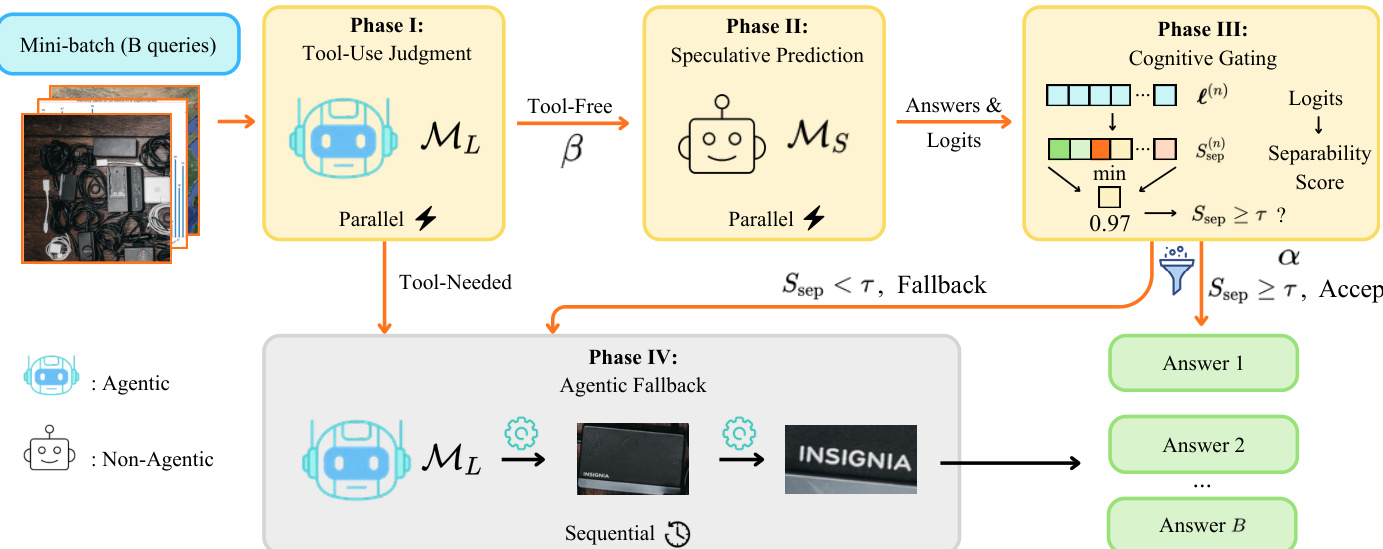
The execution flow begins with Phase I, Tool-Use Judgment. The large agentic model ML determines whether tool invocation is necessary by generating a single binary token. Queries judged as tool-free proceed to Phase II, Speculative Prediction. Here, a small stateless model MS generates an answer and the full output logit distribution without any tool execution. This inference is performed concurrently for all queries in the batch.
In Phase III, Cognitive Gating, the logits from the small model are passed to a gating function that quantifies answer confidence. The authors introduce an answer separability score Ssep that measures the decision margin between the top prediction and its competitors, rather than relying on raw softmax probabilities. If the score exceeds a threshold τ, the answer is accepted immediately. Otherwise, the query falls back to Phase IV, Agentic Fallback, where the full agentic model ML executes the complete stateful perception-reasoning loop.
Beyond per-query latency reduction, the framework enables system-level throughput gains by organizing these phases into a heterogeneous parallel funnel. The front-end screening and speculative inference are stateless and fully batch-parallelizable, while the fallback remains sequential. This architecture decouples stateless concurrency from stateful execution, significantly reducing the number of queries that incur the full agentic cost.
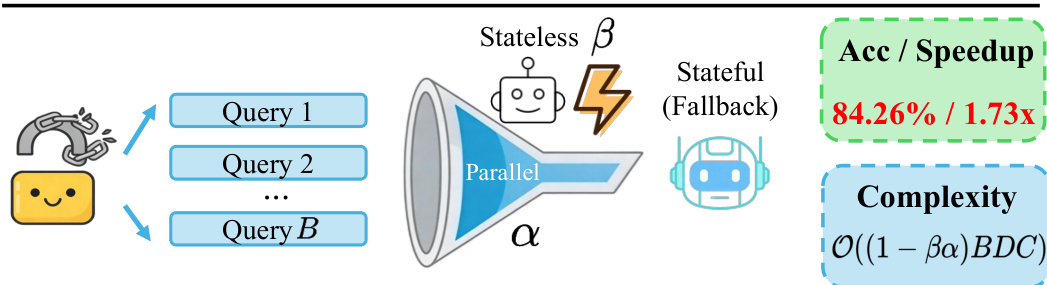
The expected per-query latency is dominated by the lightweight front-end cost when the screening ratio and gate acceptance rate are high. The resulting throughput speedup is approximately 1/(1−βα), where β is the tool-free screening ratio and α is the cognitive gate acceptance rate. This approach effectively converts per-query latency savings into system-level throughput gains while maintaining accuracy comparable to the agentic baseline.
Experiment
- Experiments on V*, HR-Bench, and POPE benchmarks validate that SpecEyes achieves significant speedups while improving or maintaining accuracy compared to agentic baselines, with the most substantial gains observed in hallucination reduction and spatial reasoning tasks.
- Qualitative analysis confirms that the min-token confidence aggregation strategy provides the best accuracy-speed trade-off by effectively distinguishing correct from incorrect answers, whereas other aggregation methods suffer from distribution overlap.
- Ablation studies demonstrate that the gating threshold serves as a robust control knob for balancing efficiency and performance, while larger serving batch sizes improve throughput by amortizing the stateless speculative stage without affecting model accuracy.
- Results indicate that SpecEyes generalizes across different agentic backbones and outperforms alternative speculative approaches that incur high token overhead, though high-resolution tasks remain a bottleneck due to the frequent necessity of tool-assisted inspection.