Command Palette
Search for a command to run...
F4Splat : Densification prédictive feed-forward pour le 3D Gaussian Splatting feed-forward
F4Splat : Densification prédictive feed-forward pour le 3D Gaussian Splatting feed-forward
Injae Kim Chaehyeon Kim Minseong Bae Minseok Joo Hyunwoo J. Kim
Résumé
Les méthodes de Splatting 3D par Gaussiennes en feed-forward permettent une reconstruction en un seul passage et un rendu en temps réel. Toutefois, elles adoptent généralement des pipelines rigides de pixel-à-Gaussianes ou de voxel-à-Gaussianes qui allouent les Gaussiennes de manière uniforme, entraînant une redondance de celles-ci à travers les différentes vues. De plus, elles ne disposent pas de mécanisme efficace pour contrôler le nombre total de Gaussiennes tout en préservant la fidélité de la reconstruction. Pour remédier à ces limitations, nous présentons F4Splat, qui réalise une densification prédictive en feed-forward pour le Splatting 3D par Gaussiennes en feed-forward, en introduisant une stratégie d'allocation guidée par un score de densification. Cette stratégie distribue de manière adaptative les Gaussiennes en fonction de la complexité spatiale et du chevauchement multi-vues. Notre modèle prédit, pour chaque région, des scores de densification afin d'estimer la densité de Gaussiennes requise et permet un contrôle explicite du budget final de Gaussiennes sans nécessiter de réentraînement. Cette allocation spatialement adaptative réduit la redondance dans les régions simples et minimise les Gaussiennes dupliquées entre les vues chevauchantes, produisant ainsi des représentations 3D à la fois compactes et de haute qualité. Des expériences extensives démontrent que notre modèle atteint des performances supérieures en synthèse de nouvelles vues par rapport aux méthodes feed-forward non étalonnées antérieures, tout en utilisant un nombre significativement réduit de Gaussiennes.
One-sentence Summary
Researchers from KAIST and Korea University present F4Splat, a feed-forward 3D Gaussian Splatting model that introduces a densification-score-guided allocation strategy to adaptively distribute primitives based on spatial complexity. Unlike prior uniform methods, this technique enables explicit control over the Gaussian budget without retraining, achieving superior novel-view synthesis with significantly fewer primitives.
Key Contributions
- The paper introduces F4Splat, a feed-forward framework that reconstructs 3D Gaussian Splatting representations from sparse, uncalibrated images while enabling explicit control over the final Gaussian count through predictive densification.
- A densification-score-guided allocation strategy is presented to predict spatial complexity and multi-view overlap, allowing the method to adaptively distribute Gaussians without iterative optimization and maintain high fidelity under limited budgets.
- Extensive experiments demonstrate that the approach achieves superior or on-par novel-view synthesis quality compared to prior uncalibrated feed-forward methods while utilizing significantly fewer Gaussians.
Introduction
Feed-forward 3D Gaussian Splatting enables rapid single-pass scene reconstruction and real-time rendering, which is critical for applications requiring immediate 3D visualization from sparse inputs. However, existing methods suffer from inefficient Gaussian allocation because they rely on rigid pixel-to-Gaussian or uniform voxel-to-Gaussian pipelines that ignore spatial complexity. This approach leads to redundant primitives in simple regions and duplicate Gaussians across overlapping views while lacking a mechanism to control the total Gaussian count without retraining. The authors leverage a densification-score-guided allocation strategy to perform predictive densification in a single forward pass, allowing the model to adaptively distribute Gaussians based on spatial detail and multi-view overlap. This contribution enables explicit control over the final Gaussian budget and produces compact, high-fidelity 3D representations that outperform prior uncalibrated methods with significantly fewer primitives.
Dataset
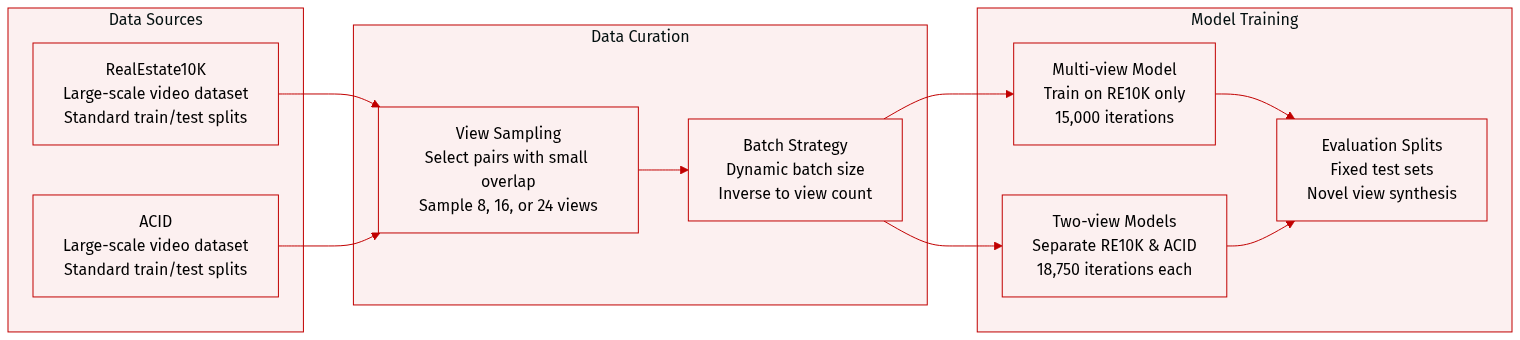
- Dataset Composition and Sources: The authors train F4Splat on two large-scale datasets: RealEstate10K (RE10K) and ACID, adhering to established train/test splits from prior works.
- Subset Details and Evaluation Setup:
- For two-view evaluation, the authors adopt the standard test split used by previous feed-forward methods.
- For multi-view evaluation, they utilize scene categorization from NoPoSplat to select input pairs with small overlap, then sample additional views between the pair to reach target counts of 8, 16, or 24 views without duplication.
- Training Strategy and Mixture:
- The multi-view model is trained exclusively on RE10K for 15,000 iterations.
- During each iteration, the system dynamically samples the number of input views from the set {2, 3, 4, 6, 12, 24} and selects an equal number of target novel views for supervision.
- To maintain a constant total image count per iteration, the authors employ a dynamic batch size that is inversely proportional to the number of context images.
- Separate models for two-view training are built on RE10K and ACID respectively, each running for 18,750 iterations with a fixed batch size of 128.
- Processing and Implementation:
- The model initializes from pretrained VGGT weights and uses three levels of multi-resolution feature maps where the finest level matches the input image resolution.
- Training involves freezing patch embedding weights in the geometry backbone while training remaining parameters with a lower learning rate.
- No specific cropping strategy or metadata construction is mentioned beyond the view sampling and scene categorization logic described above.
Method
The authors propose F4Splat, a feed-forward network designed to generate 3D Gaussian primitives from a collection of images via predictive densification. Unlike prior methods that rely on uniform allocation, this framework enables users to adjust the number of Gaussians on demand through spatially adaptive Gaussian allocation, ensuring more effective use of the available Gaussian budget.
The overall framework consists of a Geometry Backbone, Gaussian Center and Parameter Heads, and a Spatially Adaptive Gaussian Allocation module. As shown in the framework diagram:
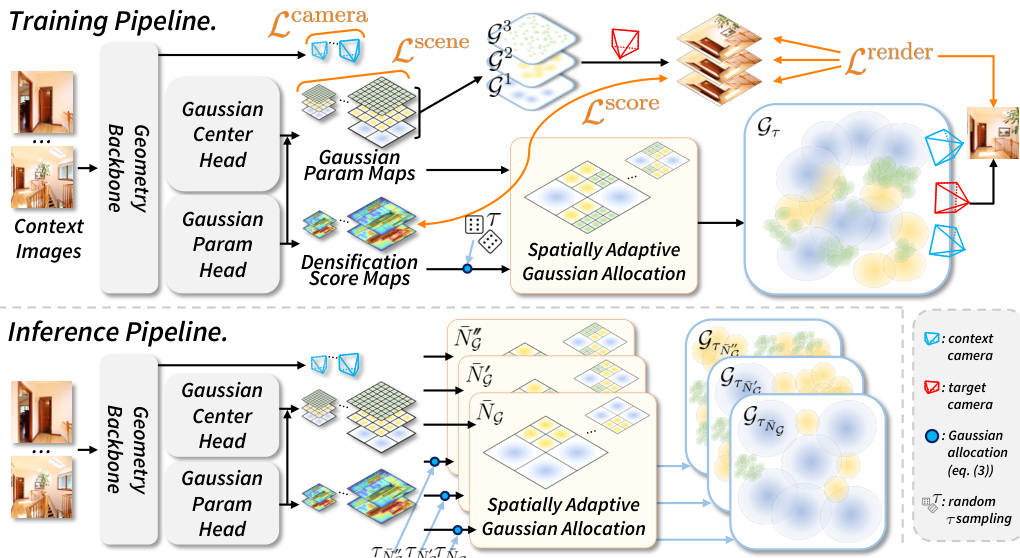 The Geometry Backbone encodes geometric information from the input context images using a DINOv2 encoder and alternating self-attention layers to predict camera parameters. The encoded features are then passed to two parallel heads. The Gaussian Center Head predicts Gaussian centers, while the Gaussian Parameter Head predicts the remaining primitive parameters (opacity, rotation, scale, SH) along with densification score maps. These heads utilize a modified DPT-based decoder to produce multi-scale Gaussian parameter maps and densification score maps at different resolutions.
The Geometry Backbone encodes geometric information from the input context images using a DINOv2 encoder and alternating self-attention layers to predict camera parameters. The encoded features are then passed to two parallel heads. The Gaussian Center Head predicts Gaussian centers, while the Gaussian Parameter Head predicts the remaining primitive parameters (opacity, rotation, scale, SH) along with densification score maps. These heads utilize a modified DPT-based decoder to produce multi-scale Gaussian parameter maps and densification score maps at different resolutions.
To control the final number of Gaussians, the method employs a spatially adaptive allocation strategy. The network predicts densification score maps that estimate where additional Gaussian density is required. During inference, a user-specified target Gaussian budget NˉG is provided. A budget-matching algorithm computes a threshold τ that satisfies this budget. The allocation module then selects Gaussians from the multi-scale maps based on this threshold. Specifically, if the densification score at a spatial region exceeds τ, Gaussians from a finer scale level are allocated to that region. This process ensures that more Gaussians are assigned to geometrically or visually complex regions while avoiding redundancy in simple areas or overlapping views.
The training process involves optimizing the network to predict accurate camera parameters and Gaussian primitives while learning the densification scores. The authors leverage a rendering loss Lrender computed between the rendered novel view and the ground-truth target image. To train the densification score prediction, the method backpropagates the rendering loss to obtain the homodirectional view-space positional gradient vg for each Gaussian. As illustrated in the score calculation figure:
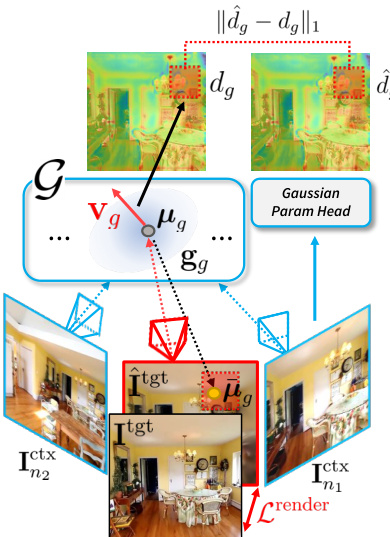 The gradient norm is converted into a target densification score dg=log(1+104⋅∥vg∥2). The network is then trained to predict this score d^g using an ℓ1 loss LGscore. Additionally, the training objective includes a camera loss Lcamera and a scene-scale regularization loss Lscene to normalize the average distance of Gaussian centers. By supervising the model with novel views rather than just context views, the method learns densification scores that generalize better across viewpoints, allowing for high-fidelity reconstruction with a compact Gaussian representation.
The gradient norm is converted into a target densification score dg=log(1+104⋅∥vg∥2). The network is then trained to predict this score d^g using an ℓ1 loss LGscore. Additionally, the training objective includes a camera loss Lcamera and a scene-scale regularization loss Lscene to normalize the average distance of Gaussian centers. By supervising the model with novel views rather than just context views, the method learns densification scores that generalize better across viewpoints, allowing for high-fidelity reconstruction with a compact Gaussian representation.
Experiment
- Main experiments on RE10K and ACID datasets validate that the method achieves high-fidelity novel view synthesis with significantly fewer Gaussian primitives than baselines, maintaining competitive performance even under sparse two-view inputs.
- Qualitative results demonstrate sharper structures and reduced blurring artifacts compared to existing approaches, confirming that explicit density control enables compact yet accurate 3D representations.
- Ablation studies confirm that the learned densification score outperforms random and frequency-based allocation strategies by prioritizing complex regions while avoiding redundancy in overlapping areas.
- Experiments show that level-wise Gaussian supervision is essential for stable multi-scale optimization, while scene-scale regularization is critical for preventing training failure in uncalibrated settings.
- Additional evaluations indicate that the model generalizes effectively to unseen datasets for relative pose estimation and introduces minimal computational overhead for spatially adaptive Gaussian allocation.