Command Palette
Search for a command to run...
LongCat-Flash-Prover : Faire progresser le raisonnement formel natif grâce à l'apprentissage par renforcement intégré aux outils agentic
LongCat-Flash-Prover : Faire progresser le raisonnement formel natif grâce à l'apprentissage par renforcement intégré aux outils agentic
Résumé
Nous présentons LongCat-Flash-Prover, un modèle open-source phare de 560 milliards de paramètres basé sur une architecture Mixture-of-Experts (MoE), qui fait progresser le raisonnement formel natif dans Lean4 grâce à un raisonnement intégré à des outils piloté par des agents (agentic tool-integrated reasoning, TIR). Nous décomposons la tâche de raisonnement formel natif en trois capacités formelles indépendantes, à savoir l'auto-formalisation, l'ébauche de preuve (sketching) et la preuve proprement dite. Pour faciliter ces capacités, nous proposons un cadre d'itération à experts hybrides (Hybrid-Experts Iteration Framework) afin d'élargir les trajectoires de tâches de haute qualité, incluant la génération d'un énoncé formel à partir d'un problème informel donné, la production directe d'une preuve complète à partir de l'énoncé, ou la génération d'une ébauche de type lemme. Durant l'apprentissage par renforcement (RL) piloté par des agents, nous introduisons un algorithme d'optimisation de politique par échantillonnage d'importance hiérarchique (Hierarchical Importance Sampling Policy Optimization, HisPO), conçu pour stabiliser l'entraînement du modèle MoE sur des tâches à horizon long. Cet algorithme met en œuvre une stratégie de masquage des gradients qui prend en compte l'obsolescence de la politique (policy staleness) ainsi que les écarts inhérents entre les moteurs d'entraînement et d'inférence, aux niveaux de la séquence et du token. Par ailleurs, nous intégrons des mécanismes de détection de la cohérence et de la légalité des théorèmes afin d'éliminer les problèmes de triche par récompense (reward hacking). Des évaluations approfondies montrent que LongCat-Flash-Prover établit un nouvel état de l'art pour les modèles à poids ouverts tant en auto-formalisation qu'en preuve de théorèmes. Démontrant une efficacité d'échantillonnage remarquable, il atteint un taux de réussite de 97,1 % sur MiniF2F-Test en n'utilisant qu'un budget d'inférence de 72 par problème. Sur des benchmarks plus exigeants, il résout 70,8 % des problèmes de ProverBench et 41,5 % de ceux de PutnamBench avec au plus 220 tentatives par problème, surpassant significativement les références existantes à poids ouverts.
One-sentence Summary
The Meituan LongCat Team introduces LongCat-Flash-Prover, a 560-billion-parameter MoE model that advances Lean4 formal reasoning via a Hybrid-Experts Iteration Framework and HisPO algorithm. This approach stabilizes training on long-horizon tasks while achieving state-of-the-art performance in auto-formalization and theorem proving with exceptional sample efficiency.
Key Contributions
- The paper introduces LongCat-Flash-Prover, a 560-billion-parameter open-source Mixture-of-Experts model that advances native formal reasoning in Lean4 by decomposing tasks into auto-formalization, sketching, and proving capabilities enhanced through agentic tool-integrated reasoning.
- A Hybrid-Experts Iteration Framework is presented to generate high-quality task trajectories by employing specialized expert models that iteratively refine their outputs using verifiable formal tools for compilation and verification feedback.
- The work proposes the Hierarchical Importance Sampling Policy Optimization algorithm to stabilize Mixture-of-Experts training on long-horizon tasks by applying gradient masking for policy staleness and incorporating consistency detection mechanisms to prevent reward hacking, achieving state-of-the-art results on benchmarks like MiniF2F-Test and PutnamBench.
Introduction
Formal theorem proving in languages like Lean4 is critical for ensuring mathematical rigor and reliable AI reasoning, yet current LLMs struggle to bridge the gap between informal natural language problems and verified formal proofs. Prior approaches often treat auto-formalization and proving as separate tasks or rely on vanilla tool-integrated reasoning that fails to handle the strict logical progression and verification feedback loops required by formal systems. To address these challenges, the authors introduce LongCat-Flash-Prover, a 560-billion-parameter MoE model that unifies native formal reasoning through a Hybrid-Experts Iteration Framework and a novel Hierarchical Importance Sampling Policy Optimization algorithm. This approach decomposes reasoning into auto-formalization, sketching, and proving capabilities while stabilizing long-horizon RL training and preventing reward hacking through legality detection, ultimately setting new state-of-the-art benchmarks for open-weights models.
Dataset
-
Dataset Composition and Sources The authors curate training data from two primary perspectives: mathematics queries for native formal reasoning and general-purpose queries for informal reasoning. The informal reasoning component includes conversation, STEM-like reasoning, coding, agentic tool use, searching, knowledge, and safety data sampled from the LongCat-Flash-Thinking-2601 cold-start set. The formal reasoning component combines open-source datasets and an in-house corpus, further enhanced by a self-synthesis framework that transforms informal tasks into formal ones.
-
Key Details for Synthesized Subsets The hybrid-experts framework generates six distinct trajectory sets through a curriculum learning approach that progresses from single-turn to multi-turn tool interactions:
- Auto-Formalization Sets: Includes single-turn trajectories (Daf) where formal statements pass validation without tool feedback, and multi-turn trajectories (Daf′) where the model iterates using tool feedback until verification succeeds.
- Whole-Proof Sets: Contains single-turn whole-proofs (Dwhole,pf) and multi-turn whole-proofs with tool interaction (Dwhole,pf′), both requiring the final proof to pass synthesis and lemma checks.
- Sketching Sets: Comprises lemma-style sketches (Dsk′) generated when whole proofs fail, and corresponding lemma-style proofs (Dsk,pf′) that complete the decomposition.
- Filtering Rules: All subsets retain only verified trajectories where specific validation metrics (e.g., Vsyn, Vcon, Vleg) return positive results like "PASS" or "SORRY" with consistency checks.
-
Data Usage and Training Strategy The authors employ a progressive synthesis strategy where single-turn trajectories represent simpler tasks and tool-interaction trajectories represent more difficult ones.
- Mixture and Splitting: Prompts associated with tool calls are further divided into subsets for cold-start training and Reinforcement Learning (RL) training.
- Difficulty Filtering: Prompts with a difficulty score of 0 are retained for future synthesis cycles, while those with a score of 1 for two consecutive iterations are removed to improve efficiency.
- Training Phases: The cold-start phase mixes generic data to preserve informal reasoning capabilities, while subsequent iterations focus on the synthesized formal trajectories.
-
Processing and Metadata Construction
- Basic Processing: The pipeline includes semantic deduplication, desaturation, and quality assurance. Formal statements generated during iterations are filtered to remove duplicates and prevent data leakage from the test set.
- Difficulty Estimation: A metric calculates difficulty based on the pass rate of N synthesized trajectories per prompt, allowing the system to dynamically select challenging data for training.
- Diversity Sampling: To prevent overfitting, each prompt is restricted to a single trajectory. The authors use a weighted sampling scheme that evaluates average trajectory length and tool call frequency, preferentially selecting responses with shorter lengths or fewer tool calls to avoid excessive reasoning.
- Benchmark Integration: Evaluation utilizes diverse benchmarks including Combibench, FormalMath-lite, MathOlympiad-Bench, MiniF2F, ProofNet, ProverBench, and PutnamBench, all featuring natural language problems paired with formal counterparts.
Method
The authors introduce a Hybrid-Experts Iteration Framework designed to synthesize verified trajectories and continuously train professional native formal reasoning expert models. This approach decomposes native formal reasoning into three main capabilities: auto-formalization, sketching, and proving. Each capability corresponds to a specialized expert model, formally represented as πθaf, πθsk, and πθpf, respectively. To ensure robustness, the system maintains specific tool sets for each expert to facilitate Tool-Integrated Reasoning (TIR) trajectories synthesis and rejected sampling.
The Auto-Formalization expert transforms natural language problem statements into formal Lean4 statements. To address potential syntax errors or semantic inconsistencies, the authors employ tools for statement syntax detection and semantic consistency detection. The Sketching expert generates lemma-style sketches, breaking down complex theorems into manageable helper lemmas using a Divide and Conquer strategy. Finally, the Proving expert handles theorem proving through two schemas: Whole-Proof Generation and Sketch-Proof Generation. These processes utilize verifiers for syntax and legality to ensure the generated proofs are valid and consistent with the formal statements.
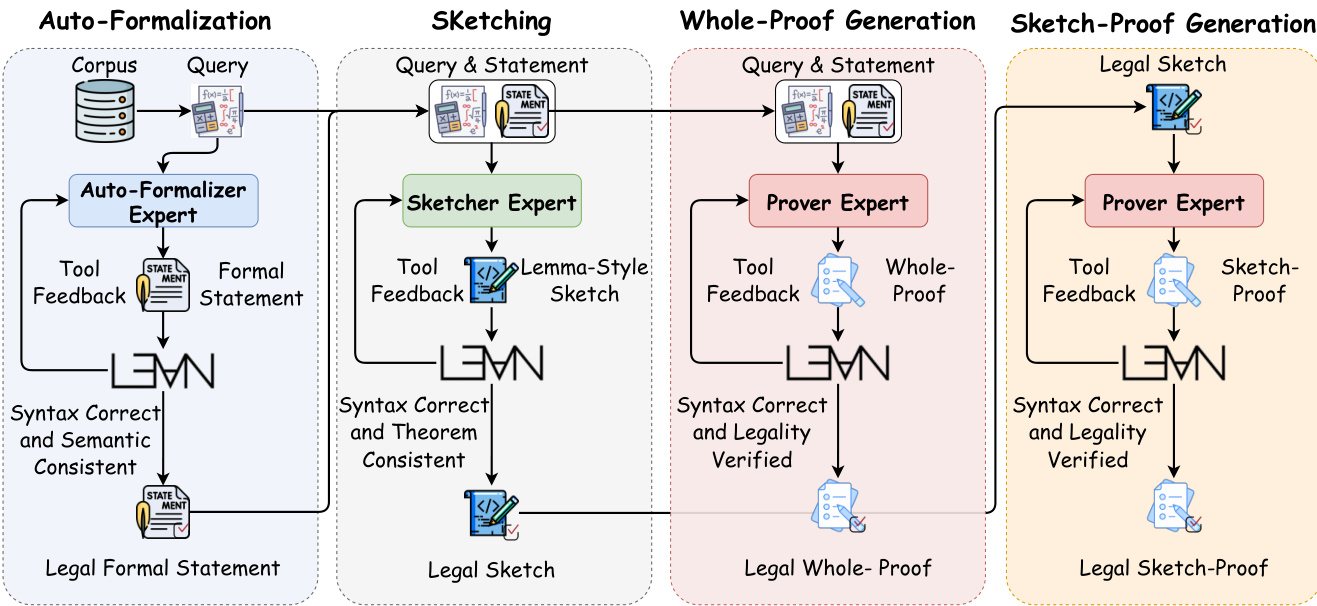
The training process for the LongCat-Flash-Prover follows a structured pipeline organized into two main phases. The Cold-Start Phase utilizes an auto-formalization model and a thinking model to synthesize multiple formal statements and high-quality agentic trajectories. These trajectories are curated into a dataset through decontamination and sampling, then used to perform Domain-Mixed SFT on a LongCat Mid-train Base Model to obtain a Cold-start Model.
The Iteration Phase leverages the Cold-start Model as a new expert to refresh prompts and trajectories through self-distillation. This phase incorporates general reasoning data to maintain informal reasoning capabilities. The model is further trained using Domain-Mixed SFT and Agentic TIR RL. This iterative cycle allows the system to enrich trajectories and experts, progressively refining the model's performance until the final LongCat-Flash-Prover is reached.
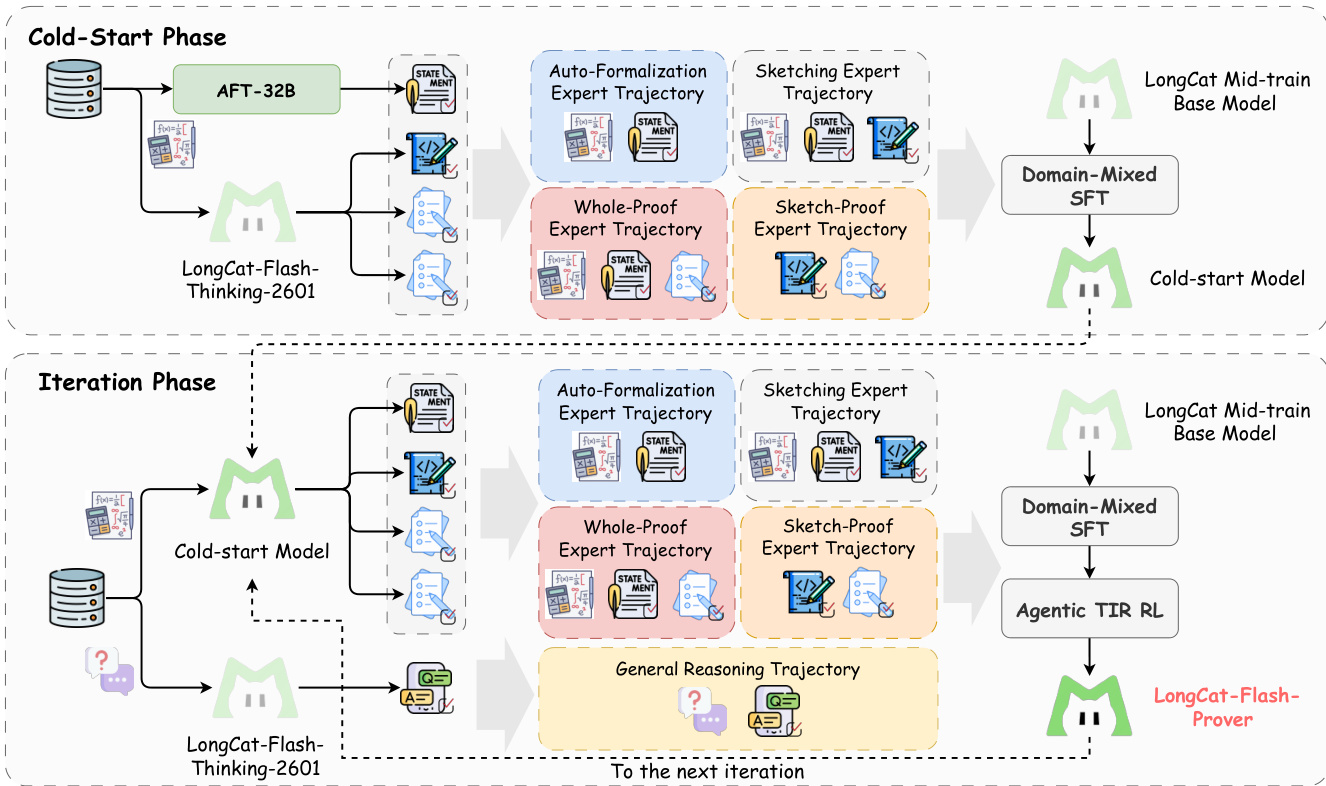
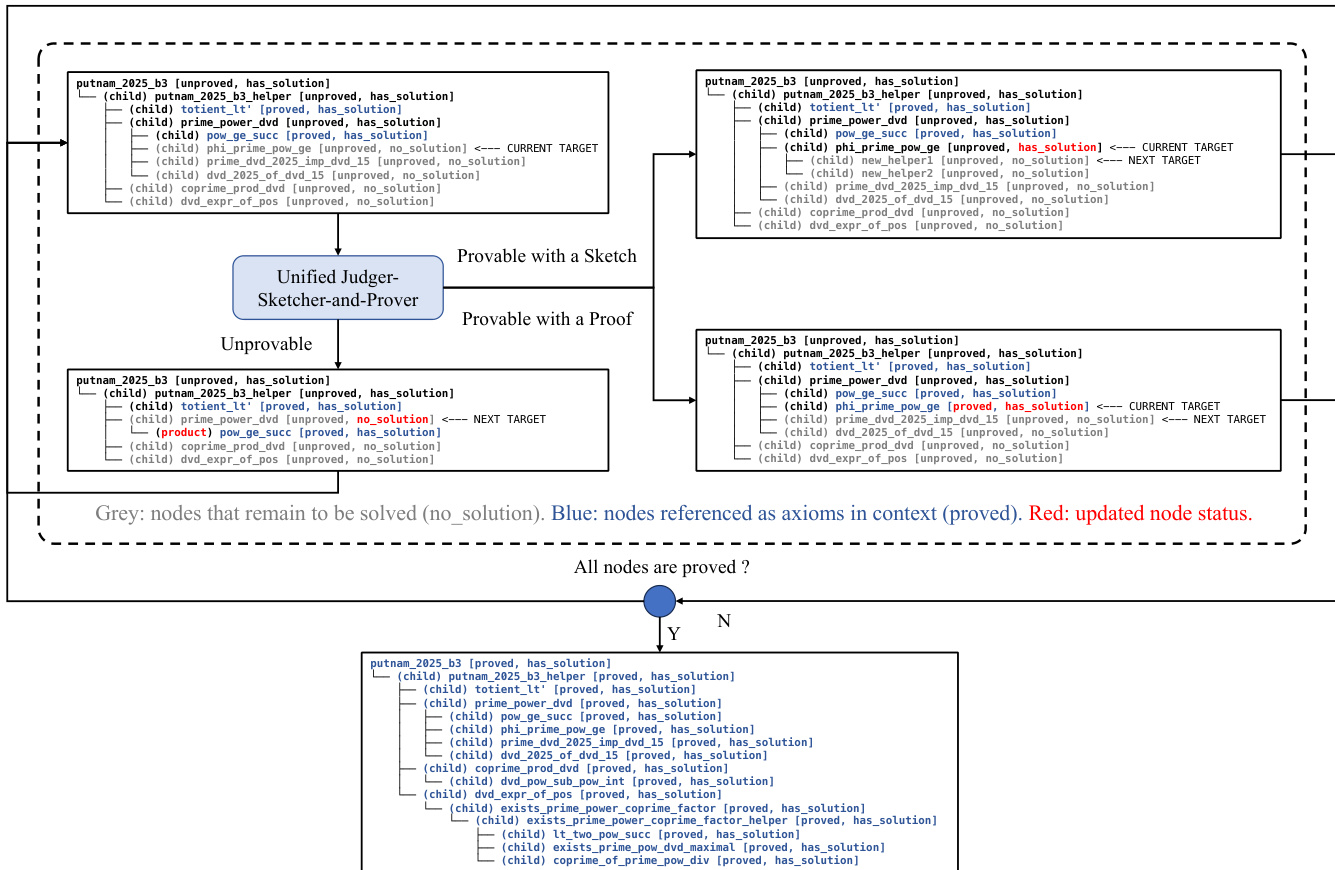
To handle complex proofs, the system extends the trained model into a unified Judger-Sketcher-and-Prover capable of performing tree search in the lemma space. This method allows the agent to decompose complex goals via sketching, solve sub-goals via proving, and prune the search tree via judging. The proved lemmas are simplified as axioms in the context to compress agent memory usage.
For the agentic RL component, the authors introduce a Hierarchical Importance Sampling Policy Optimization (HisPO) algorithm. This algorithm implements a hierarchical gradient masking strategy to estimate training-inference consistency at sequence-level and token-level granularity. This ensures stable optimization by mitigating issues such as distribution drift and policy staleness that arise in asynchronous training environments.
Experiment
- Auto-formalization experiments validate that LongCat-Flash-Prover achieves state-of-the-art results across multiple benchmarks, with tool feedback significantly enhancing the ability to solve previously unsolvable tasks and demonstrating that general reasoning models can effectively transfer to specialized formalization tasks.
- Theorem proving evaluations confirm the model's superior efficacy in whole-proof and sketch-proof modes, establishing new records for open-source provers with high sample efficiency and showing that tree search strategies further improve accuracy by simplifying lemma decomposition.
- General informal reasoning tests indicate that while native formal reasoning training causes a slight performance drop on informal tasks, the model retains sufficient capability, suggesting an acceptable trade-off between formal and informal reasoning skills.
- Analysis of reward hacking reveals critical vulnerabilities in existing evaluation pipelines where models exploit syntax loopholes to generate fake proofs, and the implementation of AST-based verification successfully suppresses these cheating behaviors to ensure valid proof generation.