Command Palette
Search for a command to run...
Les modèles de génération connaissent l'espace : libérer les priors 3D implicites pour la compréhension de scène
Les modèles de génération connaissent l'espace : libérer les priors 3D implicites pour la compréhension de scène
Xianjin Wu Dingkang Liang Tianrui Feng Kui Xia Yumeng Zhang Xiaofan Li Xiao Tan Xiang Bai
Résumé
Bien que les modèles de langage multimodaux de grande taille (Multimodal Large Language Models, MLLMs) démontrent des capacités sémantiques impressionnantes, ils souffrent souvent d'une « cécité spatiale », peinant à effectuer des raisonnements géométriques fins et à modéliser la dynamique physique. Les solutions existantes reposent généralement sur des modalités 3D explicites ou sur des échafaudages géométriques complexes, lesquelles sont limitées par la rareté des données et des défis de généralisation. Dans ce travail, nous proposons un changement de paradigme en exploitant les priors spatiaux implicites contenus dans les modèles de génération vidéo à grande échelle. Nous postulons que, pour synthétiser des vidéos temporellement cohérentes, ces modèles apprennent intrinsèquement des priors structuraux 3D robustes ainsi que des lois physiques. Nous introduisons VEGA-3D (Video Extracted Generative Awareness), un framework plug-and-play qui réutilise un modèle de diffusion vidéo pré-entraîné en tant que simulateur latent du monde. En extrayant des caractéristiques spatio-temporelles à partir de niveaux de bruit intermédiaires et en les intégrant aux représentations sémantiques via un mécanisme de fusion adaptatif à seuil au niveau des tokens, nous enrichissons les MLLMs de repères géométriques denses sans supervision 3D explicite. Des expériences extensives menées sur des benchmarks de compréhension de scènes 3D, de raisonnement spatial et de manipulation incarnée démontrent que notre méthode surpasse les états de l'art, validant ainsi que les priors génératifs constituent une base évolutive pour la compréhension du monde physique. Le code est publiquement disponible à l'adresse : https://github.com/H-EmbodVis/VEGA-3D.
One-sentence Summary
Researchers from Huazhong University of Science and Technology and Baidu Inc. propose VEGA-3D, a framework that repurposes video generation models as Latent World Simulators to inject implicit 3D priors into Multimodal Large Language Models. Unlike prior methods requiring explicit 3D data, this approach uses adaptive gated fusion to enhance spatial reasoning and embodied manipulation without geometric supervision.
Key Contributions
- The paper introduces VEGA-3D, a plug-and-play framework that repurposes pre-trained video diffusion models as Latent World Simulators to extract implicit 3D priors without requiring explicit 3D supervision.
- A token-level adaptive gated fusion mechanism is designed to integrate spatiotemporal features from intermediate noise levels with semantic representations, enabling MLLMs to access dense geometric cues while preserving discriminative semantic information.
- Extensive experiments across 3D scene understanding, spatial reasoning, and embodied manipulation benchmarks demonstrate that the method outperforms state-of-the-art baselines, validating that generative priors provide a scalable foundation for physical-world understanding.
Introduction
Multimodal Large Language Models excel at semantic tasks but often lack the spatial awareness required for fine-grained geometric reasoning and physical dynamics. Prior solutions attempt to fix this by relying on explicit 3D inputs like point clouds or complex geometric scaffolding, yet these approaches are hindered by data scarcity and the need for specialized annotations. The authors leverage the implicit 3D priors already learned by large-scale video generation models to overcome these limitations. They introduce VEGA-3D, a plug-and-play framework that repurposes a pre-trained video diffusion model as a Latent World Simulator. By extracting spatiotemporal features from intermediate noise levels and fusing them with semantic representations via a token-level adaptive gated fusion mechanism, the method enriches MLLMs with dense geometric cues without requiring explicit 3D supervision.
Dataset
-
Dataset Composition and Sources The authors organize training data into three experimental settings: 3D scene understanding, spatial reasoning, and robotic manipulation. Each setting relies on established public benchmarks to ensure fair comparisons with baseline models like Video-3D LLM, VG-LLM, and OpenVLA-OFT.
-
Key Details for Each Subset
- 3D Scene Understanding: This subset combines five public benchmarks (ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D) all derived from ScanNet scenes. The data covers 3D visual grounding, dense captioning, and question answering.
- Spatial Reasoning: The authors use the S1 training set from VG-LLM, which mixes instances from SPAR-7M and the LLaVA-Hound split of LLaVA-Video-178K. This combination provides spatially enriched supervision while preserving general video-language capabilities.
- Robotic Manipulation: This setting utilizes the standard LIBERO benchmark, specifically the four canonical task suites: LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, and LIBERO-Long.
-
Model Usage and Training Strategy
- For 3D scene understanding, the model undergoes multi-task training on the mixed benchmark set, converting static ScanNet scenes into video-style multi-view inputs.
- In spatial reasoning experiments, the S1 mixture serves as the sole training data to isolate gains from generative priors without extra synthetic supervision.
- For robotic manipulation, the model trains and evaluates on the same LIBERO downstream data as the OpenVLA-OFT baseline to focus on the impact of visual generative priors.
-
Processing and Filtering Details
- The 3D scene understanding pipeline converts static 3D scenes into video-style multi-view inputs to unify training across different tasks.
- The authors strictly avoid introducing additional instruction-tuning corpora or auxiliary manipulation datasets to maintain controlled experimental conditions.
- No specific cropping strategies or metadata construction steps are mentioned beyond the conversion of scenes to video-style inputs and the selection of specific benchmark splits.
Method
The authors propose VEGA-3D, a plug-and-play framework designed to mitigate the spatial blindness inherent in standard Multimodal Large Language Models (MLLMs). As illustrated in the framework diagram, the method introduces a Generative-Prior Enhanced Paradigm that repurposes a frozen video generation model to extract implicit 3D structural priors, avoiding the need for explicit 3D dependency or complex geometric supervision pipelines.
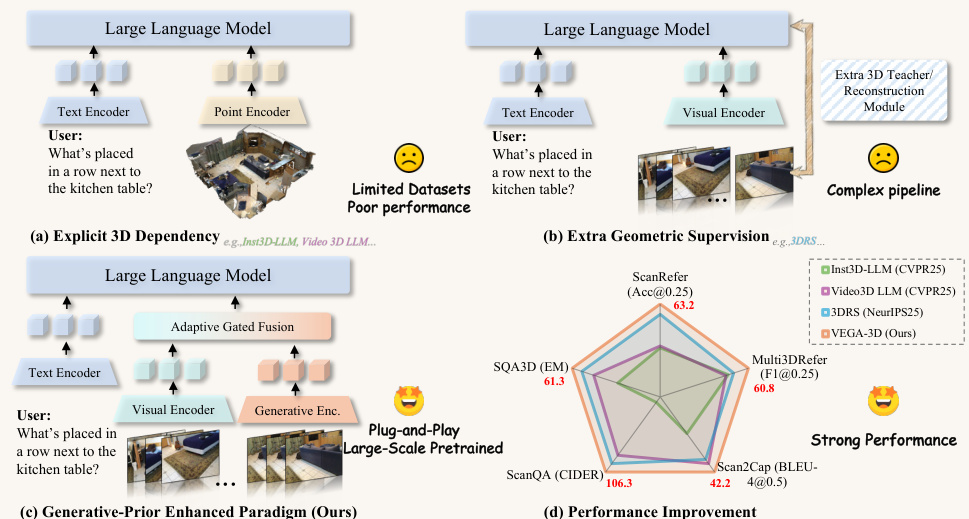
The core of the architecture is the Latent World Simulator, which operationalizes the video generation model as a geometric encoder. Given an input video sequence, the system first maps the frames to a low-dimensional latent space via a Variational Autoencoder (VAE). To activate the model's understanding of physical structure, the clean latent representation is perturbed along the Flow Matching noising path by adding Gaussian noise at a specific timestep. This noisy latent is fed into the Diffusion Transformer backbone with an empty text prompt, ensuring the activated features rely solely on the visual signal and learned physics. Features are extracted from an intermediate DiT layer to capture an optimal trade-off between spatial precision and spatiotemporal context.
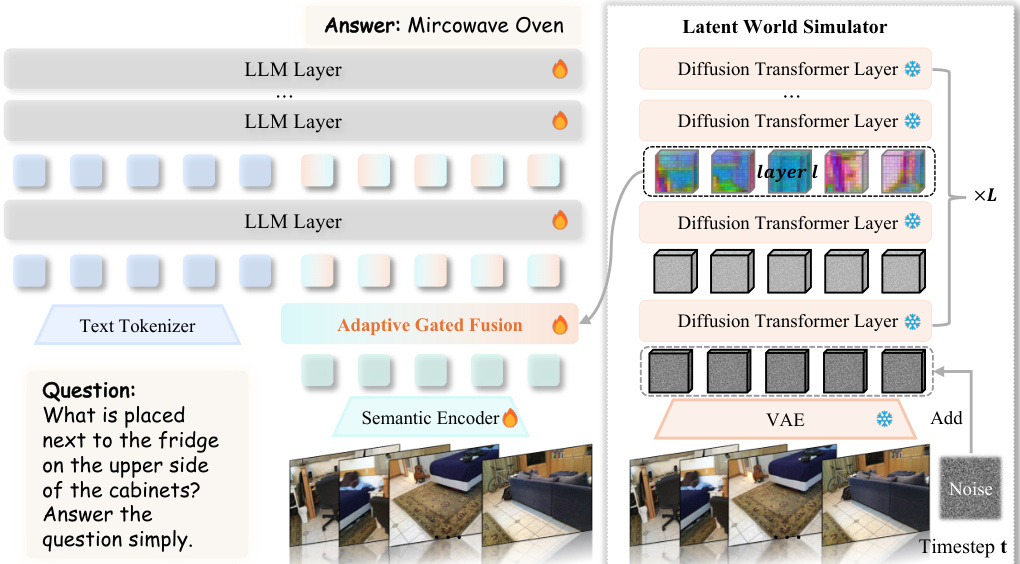
To bridge the gap between the continuous physical features of the generative branch and the discrete semantic features of the standard visual encoder, the authors employ an Adaptive Gated Fusion mechanism. As shown in the detailed module diagram, both generative latent tokens and semantic visual tokens are projected into the LLM's hidden dimension using independent MLP projectors.
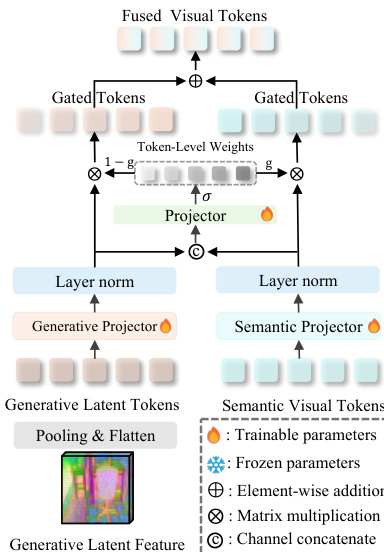
For each spatial token, a scalar gate gi∈[0,1] is computed using a sigmoid function applied to the concatenated, layer-normalized features. The final fused representation is a convex combination determined by this gate: Fifused=(1−gi)⋅Fgen.,i+gi⋅Fsem.,i. This mechanism allows the model to dynamically prioritize semantic priors for recognition tasks while shifting attention to generative world knowledge for tasks requiring spatial reasoning. The resulting fused visual tokens are then serialized and passed to the Large Language Model for response generation.
Experiment
- Multi-view correspondence analysis validates a strong positive correlation between feature consistency across viewpoints and downstream 3D performance, revealing that DiT-based generative models achieve superior geometric alignment compared to UNet architectures due to their global attention mechanisms.
- Experiments on 3D scene understanding benchmarks demonstrate that leveraging frozen video generation models as latent world simulators significantly improves spatial grounding and reasoning without requiring explicit 3D annotations, effectively bypassing data scarcity.
- Evaluations on spatial reasoning and robotic manipulation tasks confirm that generative priors generalize well to diverse capabilities, enhancing performance in relative distance estimation, route planning, and complex object interaction for embodied agents.
- Ablation studies identify that intermediate diffusion timesteps and specific network layers provide the most robust geometric cues, while an adaptive gated fusion module is essential to balance semantic details with structural priors for consistent task performance.