Command Palette
Search for a command to run...
3DreamBooth : Modèle de génération vidéo piloté par sujet 3D à haute fidélité
3DreamBooth : Modèle de génération vidéo piloté par sujet 3D à haute fidélité
Hyun-kyu Ko Jihyeon Park Younghyun Kim Dongheok Park Eunbyung Park
Résumé
La création de vidéos dynamiques et cohérentes visuellement, mettant en scène des sujets personnalisés, est hautement recherchée pour un large éventail d'applications émergentes, notamment la réalité virtuelle (VR) et la réalité augmentée (AR) immersives, la production virtuelle et le commerce électronique de nouvelle génération. Cependant, malgré les progrès rapides dans la génération de vidéos pilotée par un sujet, les méthodes existantes traitent principalement les sujets comme des entités 2D, en se concentrant sur le transfert d'identité à partir de caractéristiques visuelles mono-vues ou d'indications textuelles (prompts). Étant donné que les sujets du monde réel sont intrinsèquement 3D, l'application de ces approches centrées sur la 2D à la personnalisation d'objets 3D révèle une limitation fondamentale : elles manquent des a priori spatiaux complets nécessaires à la reconstruction de la géométrie 3D. Par conséquent, lors de la synthèse de nouvelles vues, elles doivent s'appuyer sur la génération de détails plausibles mais arbitraires pour les régions invisibles, plutôt que de préserver l'identité 3D réelle. Atteindre une personnalisation véritablement consciente de la 3D reste un défi en raison de la rareté des ensembles de données vidéo multi-vues. Bien qu'il soit possible d'affiner (fine-tune) des modèles sur de séquences vidéo limitées, cela conduit souvent à un surajustement temporel (temporal overfitting). Pour résoudre ces problèmes, nous introduisons un nouveau cadre pour la personnalisation vidéo consciente de la 3D, comprenant 3DreamBooth et 3Dapter. 3DreamBooth découple la géométrie spatiale du mouvement temporel grâce à un paradigme d'optimisation sur une seule image (1-frame optimization). En restreignant les mises à jour aux représentations spatiales, il intègre efficacement un a priori 3D robuste dans le modèle, sans nécessiter un entraînement exhaustif basé sur des vidéos. Pour améliorer les textures à grain fin et accélérer la convergence, nous incorporons 3Dapter, un module de conditionnement visuel. Après un pré-entraînement mono-vue, 3Dapter subit une optimisation conjointe multi-vues avec la branche principale de génération via une stratégie de conditionnement asymétrique. Cette conception permet au module d'agir en tant que routeur sélectif dynamique, interrogeant des indices géométriques spécifiques à la vue à partir d'un ensemble de référence minimal. Page du projet : https://ko-lani.github.io/3DreamBooth/
One-sentence Summary
Researchers from Yonsei University and Sungkyunkwan University propose 3DreamBooth and 3Dapter, a framework that decouples spatial geometry from temporal motion via 1-frame optimization to generate high-fidelity, view-consistent videos of customized 3D subjects for immersive VR and virtual production.
Key Contributions
- The paper introduces 3DreamBooth, a 1-frame optimization strategy that integrates subject-specific 3D identity into video diffusion models by restricting updates to spatial representations, thereby avoiding the need for multi-view video datasets while preventing temporal overfitting.
- A multi-view conditioning module called 3Dapter is presented to enhance fine-grained textures and accelerate convergence through a two-stage pipeline that employs an asymmetrical conditioning strategy to query view-specific geometric hints from a minimal reference set.
- The work establishes 3D-CustomBench, a curated evaluation suite for 3D-consistent video customization, with experiments demonstrating that the combined framework outperforms existing single-reference baselines in generating high-fidelity, identity-preserving videos.
Introduction
The demand for immersive VR/AR experiences and virtual production requires generative systems that can place customized subjects into dynamic environments while maintaining strict visual consistency across different viewpoints. Current subject-driven video generation methods largely treat objects as 2D entities, relying on single-view references or text prompts that fail to capture the underlying 3D geometry. This limitation forces models to hallucinate arbitrary details for unseen angles rather than preserving true spatial identity, while attempts to train on limited multi-view video data often result in temporal overfitting. To resolve these issues, the authors introduce 3DreamBooth, a framework that decouples spatial geometry from temporal motion through a 1-frame optimization paradigm to bake robust 3D priors without exhaustive video training. They further enhance this approach with 3Dapter, a multi-view conditioning module that uses an asymmetrical strategy to inject fine-grained geometric hints, enabling high-fidelity and view-consistent video generation with improved computational efficiency.
Dataset
-
Dataset Composition and Sources: The authors utilize two primary datasets: the Subjects200K dataset for single-view pre-training and the newly introduced 3D-CustomBench for evaluation. 3D-CustomBench combines objects from the MVIgNet dataset with custom-captured 3D objects to ensure complete 360° orbital coverage.
-
Key Details for Each Subset:
- Subjects200K: Contains over 30,000 distinct subject descriptions generated by GPT-4o, which are used to synthesize paired images via the FLUX.1 model. These pairs share identical subject identities but feature varied poses, lighting, and backgrounds to prevent overfitting.
- 3D-CustomBench: Comprises 30 distinct objects selected for complex 3D structures, non-trivial topologies, and high texture resolution. Each object includes a full multi-view sequence of approximately 30 images.
-
Data Usage and Training Strategy:
- Pre-training: The model leverages Subjects200K to train 3Dapter using Low-Rank Adaptation (LoRA) on key image-processing modules. Training runs for 100,000 iterations with a global batch size of 4 and a learning rate of 1×10−4 using the AdamW optimizer.
- Evaluation: For 3D-CustomBench, the full multi-view sequence of each object is used for 3DreamBooth optimization. The authors sample Nc=4 conditioning views for 3Dapter that maximize angular coverage while minimizing visual overlap.
-
Processing and Metadata Construction:
- Automated Curation: GPT-4o generates subject descriptions and acts as an automated evaluator to discard misaligned samples during the construction of Subjects200K.
- Prompt Generation: GPT-4o automatically creates one challenging validation prompt per object in 3D-CustomBench, featuring diverse backgrounds and complex dynamics like human-object interactions.
- View Selection: Conditioning views are strategically selected to ensure optimal angular distribution rather than random sampling.
Method
The authors introduce 3DreamBooth, a framework for 3D customization of video diffusion models. The core strategy involves decoupling spatial identity from temporal dynamics through a 1-frame training paradigm.

Refer to the framework diagram for the overall architecture. The pipeline accepts a set of multiview images where one image serves as the target and a subset acts as reference conditions. A global prompt with a unique identifier V guides the generation. The text and noisy target latents are processed through the main branch using 3DB LoRA, while reference latents pass through a shared 3Dapter. These features are concatenated for Multi-view Joint Attention. By restricting the input to a single frame (T=1), the model bypasses temporal attention, focusing updates on spatial representations to learn a 3D prior without temporal overfitting.
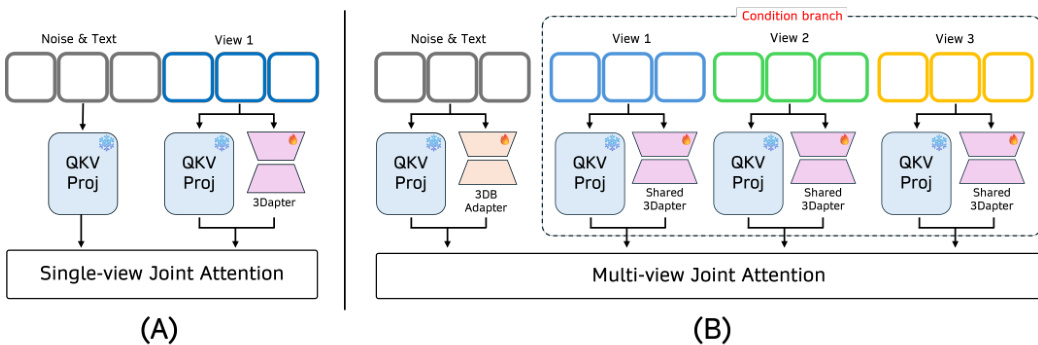
As shown in the figure below, the 3Dapter module utilizes a two-stage conditioning mechanism. The first stage involves single-view pre-training on reference-target pairs. The second stage performs multi-view joint optimization where a shared 3Dapter processes multiple conditioning views in parallel. The Multi-view Joint Attention acts as a dynamic selective router, querying relevant view-specific geometric hints to reconstruct the target view. This shared architecture ensures consistent geometric feature extraction across viewpoints without increasing parameter count linearly.
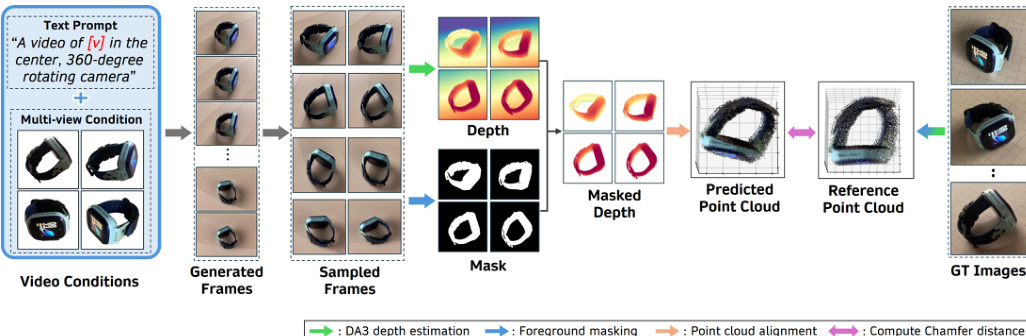
As shown in the figure below, the training process incorporates a 3D consistency check to ensure geometric fidelity. Generated frames undergo depth estimation and foreground masking to produce a predicted point cloud. This cloud is aligned with a reference point cloud to compute the Chamfer distance, which serves as a constraint during optimization. This approach allows the model to focus on learning geometric transformations while preserving high-frequency details, effectively overcoming the information bottleneck of text-driven customization.
Experiment
- Comparative experiments against VACE and Phantom validate that the proposed framework achieves superior multi-view subject fidelity, preserving identity, shape, color, and fine-grained details during 360-degree rotations where baselines fail to reconstruct unseen viewpoints.
- 3D geometric fidelity evaluations demonstrate that the method significantly reduces reconstruction error and improves surface coverage compared to single-view approaches, confirming its ability to recover complete 3D structures from multi-view conditioning.
- Ablation studies reveal that the synergistic combination of 3Dapter and 3DreamBooth is essential, as 3Dapter alone lacks 3D consistency while 3DreamBooth alone struggles with texture details and slow convergence, whereas their joint optimization ensures both structural accuracy and high-frequency detail preservation.
- Additional tests confirm the framework's robustness across diverse object categories and dynamic scenarios, as well as its extensibility to other Diffusion Transformer architectures without requiring explicit spatial conditioning modules.
- Analysis of training dynamics shows that pre-training the 3Dapter module is critical to prevent optimization collapse and enable rapid convergence, while the full framework achieves high-fidelity results in fewer iterations than text-driven baselines.