Command Palette
Search for a command to run...
Rapport technique MOSS-TTS
Rapport technique MOSS-TTS
SII-OpenMOSS Team
Résumé
Ce rapport technique présente MOSS-TTS, un modèle fondamental de génération de voix construit selon une recette scalable : tokens audio discrets + modélisation autoregressive + préentraînement à grande échelle. Basé sur MOSS-Audio-Tokenizer, un tokenizeur Transformer causal qui compresse l'audio 24kHz à 12.5fps avec RVQ (Residual Vector Quantization) à débit variable et des représentations sémantique-acoustiques unifiées, nous mettons à disposition deux générateurs complémentaires : MOSS-TTS, qui met l'accent sur la simplicité structurelle, la scalabilité et le déploiement orienté long-contexte et contrôle, et MOSS-TTS-Local-Transformer, qui introduit un module autoregressif local par frame pour une efficacité de modélisation supérieure, une meilleure préservation de la voix du locuteur et un temps plus court jusqu'à la première génération audio. Dans des contextes multilingues et ouverts, MOSS-TTS prend en charge le clonage de voix zero-shot, le contrôle de durée au niveau des tokens, le contrôle de prononciation au niveau des phonèmes/pinyin, la transition fluide entre codes (code-switching) et la génération stable de contenu long. Ce rapport résume la conception, la recette d'entraînement et les caractéristiques empiriques des modèles publiés.
One-sentence Summary
The SII-OpenMOSS Team presents MOSS-TTS, a speech generation foundation model built on discrete audio tokens, autoregressive modeling, and large-scale pretraining using the MOSS-Audio-Tokenizer to compress 24kHz audio to 12.5fps with variable-bitrate RVQ, releasing two complementary generators where MOSS-TTS emphasizes structural simplicity and scalability while MOSS-TTS-Local-Transformer prioritizes efficiency and speaker preservation to enable zero-shot voice cloning, token-level duration control, phoneme-/pinyin-level pronunciation control, and smooth code-switching in multilingual open-domain settings.
Key Contributions
- This work presents MOSS-TTS, a speech generation foundation model built on a scalable recipe combining discrete audio tokens, autoregressive modeling, and large-scale pretraining. The approach utilizes MOSS-Audio-Tokenizer, a causal Transformer tokenizer that compresses 24kHz audio to 12.5fps with variable-bitrate RVQ and unified semantic-acoustic representations.
- The report releases two complementary generators, with MOSS-TTS emphasizing structural simplicity and MOSS-TTS-Local-Transformer introducing a frame-local autoregressive module. The latter achieves higher modeling efficiency, stronger speaker preservation, and a shorter time to first audio under the same tokenizer and large-scale pretraining recipe.
- Across multilingual and open-domain settings, the model supports zero-shot voice cloning, token-level duration control, and phoneme-level pronunciation control. The design enables stable long-form generation and smooth code-switching capabilities without relying on external pretrained audio teachers.
Introduction
Modern speech generation increasingly relies on discrete audio tokenization and autoregressive modeling to achieve scalable foundation models. However, prior approaches often struggle to balance compression efficiency with semantic alignment while ensuring stability during long-context synthesis. The authors address these challenges by presenting MOSS-TTS, a foundation model built on a scalable recipe of discrete tokens, autoregressive modeling, and large-scale pretraining. They integrate a causal Transformer tokenizer that unifies semantic and acoustic representations and introduce two complementary generator architectures to trade off simplicity against efficiency. This framework enables zero-shot voice cloning and fine-grained control over duration and pronunciation across multilingual settings.
Dataset

Dataset Composition and Sources
- The authors source audio from naturally occurring open-domain recordings including podcasts, audiobooks, broadcast news, film, and online content.
- Raw web audio is processed through a three-phase pipeline to ensure acoustic cleanliness and faithful transcript alignment for TTS supervision.
Preprocessing and Filtering Pipeline
- Audio Preprocessing: The authors resample raw files to 48 kHz and denoise them using MossFormer2-SE-48K. Volume normalization applies RMS-based gain clamping and peak normalization to standardize amplitude across sources.
- Speaker Segmentation: DiariZen performs diarization to create speaker-labeled intervals. Segments shorter than 0.1 seconds are removed, and consecutive same-speaker segments are merged. Recordings are capped at one hour.
- Transcript Generation: MOSS-Transcribe-Diarize produces multilingual transcripts. Rule-based checks discard empty text or excessive repetition. An LLM refines content by fixing truncation and removing non-speech tags.
- Quality Validation: Final pairs must pass acoustic quality checks (DNSMOS greater than 2.8, Meta AudioBox PQ greater than 6.5), match audio and text language labels, and maintain language-specific character rate consistency.
Synthesis and Augmentation
- Timbre Transfer: The authors construct prompt-target pairs from the same speaker using random 30-second crops selected by WavLM-Large embedding similarity.
- Robustness and Coverage: Text noise transformations are applied to existing pairs. Phonetic scripts and single-character utterances are added to handle pronunciation control and short-form inputs.
- Duration Formatting: Assets are serialized into duration-conditioned and free-duration variants to support both explicit and implicit duration supervision during training.
Training Application
- The corpus supports a four-phase pretraining schedule covering millions of hours of speech data.
- Statistics on domain share, language distribution, and utterance duration are detailed in Figure 4 of the paper.
Method
The authors propose a speech generation framework built upon three core components: a high-quality audio tokenizer, a large-scale data pipeline, and autoregressive generative models.
Audio Tokenizer Architecture The foundation of the system is the MOSS-Audio-Tokenizer, which transforms continuous audio into discrete tokens suitable for autoregressive modeling. As shown in the framework diagram, the model employs an RVQ-GAN framework consisting of a causal encoder, a residual vector quantizer (RVQ), a causal decoder, a semantic head, and adversarial discriminators. The encoder and decoder are built upon causal Transformers with 68 blocks each, utilizing a 10-second sliding-window attention mechanism to facilitate streaming inference. The encoder progressively downsamples 24 kHz waveforms to a frame rate of 12.5 fps using patchify operations and linear projections across four stages.
Discrete tokenization is performed using a 32-layer residual vector quantizer. Each layer employs a codebook of size 1024 with factorized vector quantization and L2-normalized codes. To encourage semantically structured representations, a 0.5B decoder-only causal language model is attached as a semantic head. This head provides audio-to-text supervision by autoregressively predicting text conditioned on the quantizer outputs, covering tasks such as Automatic Speech Recognition and audio captioning.
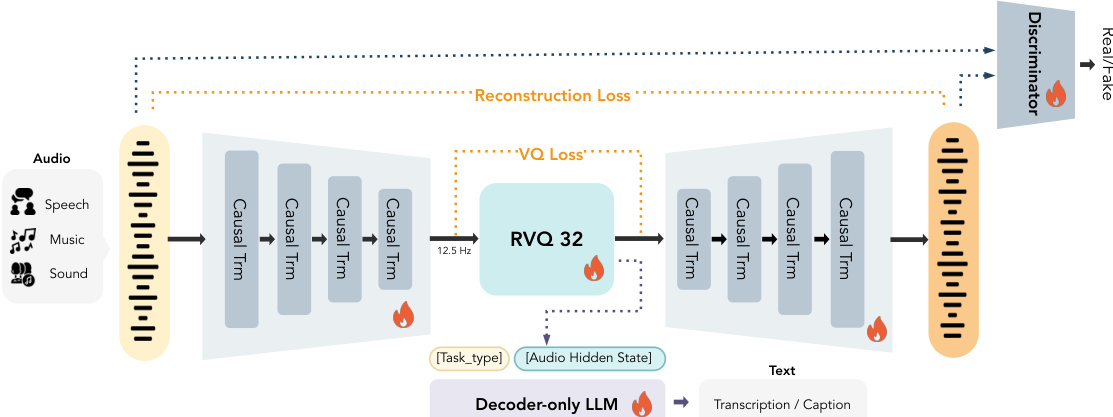
Training the tokenizer involves a multi-task learning framework. The semantic objective is optimized using a standard cross-entropy loss:
Lsem=−t=1∑∣s∣logpθLLM(st∣T,q,s<t),where s denotes the target text token sequence and q represents the quantized audio representations. Quantizer optimization utilizes factorized vector quantization with commitment and codebook losses. To ensure high-fidelity reconstruction, a multi-scale mel-spectrogram loss is employed:
Lrec=i=5∑11∥S2i(x)−S2i(x^)∥1,Additionally, adversarial training with multiple discriminators is used to improve perceptual quality, employing a least squares GAN formulation for the discriminator loss and incorporating feature matching losses for the generator.
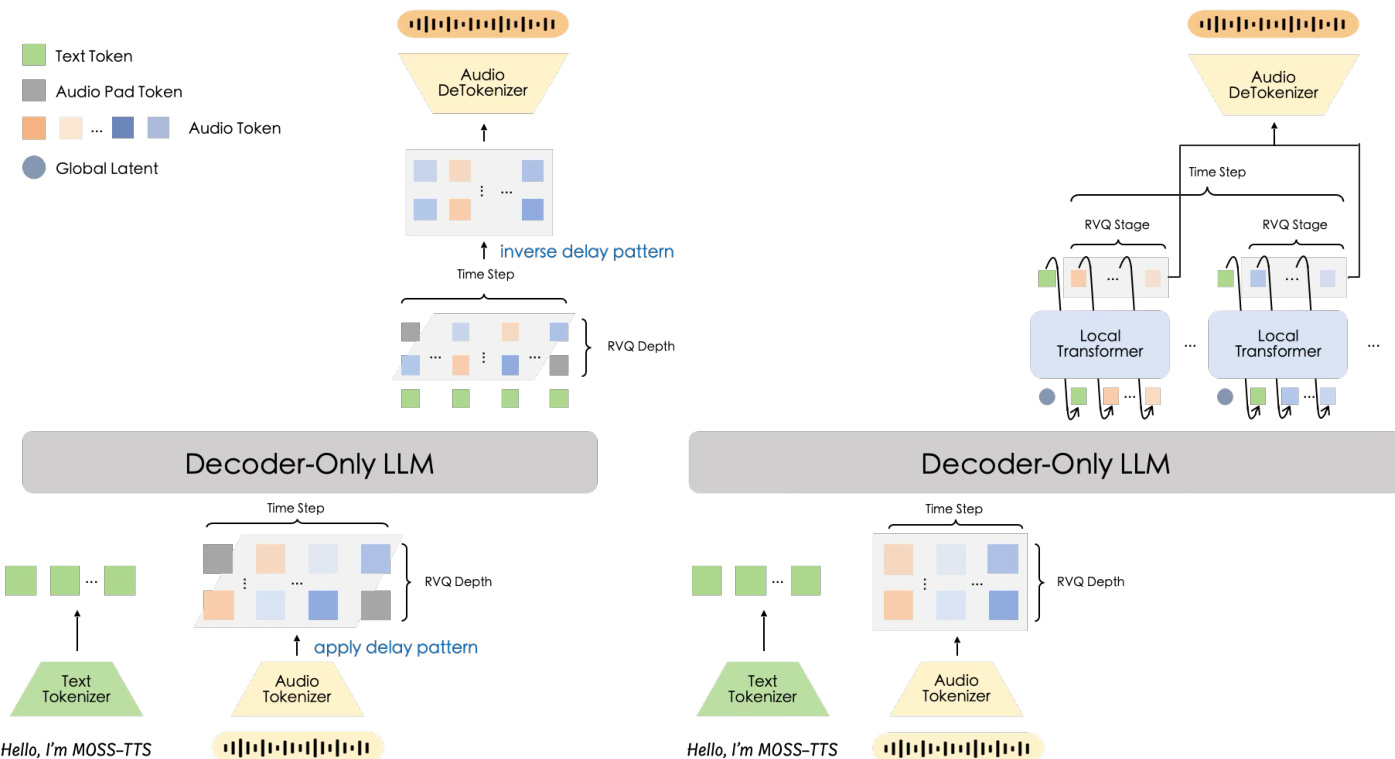
Generative Model Architectures MOSS-TTS explores two distinct architectures for modeling the discrete audio tokens. As illustrated in the architecture comparison, the authors evaluate a Delay-Pattern model and a Global-Latent + Local Transformer model.
The Delay-Pattern model utilizes a single Transformer backbone with multiple prediction heads. It applies a time-delay shift to the RVQ layers such that the j-th layer is shifted forward by j−1 frames. This allows the model to predict all channels from a single backbone hidden state without increasing the sequence length excessively. The input audio representation vector is the sum of embeddings across all layers, and the output heads predict the text-or-pad channel and the 32 audio channels.
The Global-Latent + Local Transformer model introduces a hierarchical design. The backbone produces one global latent per aligned step, and a lightweight autoregressive module expands that latent into the within-step token block. This approach models the token block without introducing temporal shifts, inserting an additional autoregressive loop of length Nq+1 inside each frame. While computationally heavier in steady-state decoding, this design offers a stronger inductive bias for frame-level token modeling and exhibits higher modeling efficiency.
Data Pipeline and Pretraining To support large-scale pretraining, the authors construct a high-quality data pipeline that converts raw open-domain recordings into trainable assets. The process is divided into three main phases as depicted in the overview diagram.
Phase 1 involves preprocessing, which includes noise reduction, format alignment, volume normalization, and diarization to consolidate raw audio into single-speaker segments. Phase 2 focuses on filtering, utilizing ASR and transcript quality control, rule-based pre-filtering, and joint audio-text filtering to ensure acoustic quality and language consistency. Phase 3 covers data synthesis, generating timbre-cloning data by pairing segments of the same speaker and creating supplementary data for input robustness, phonetic input, and short-form tasks.
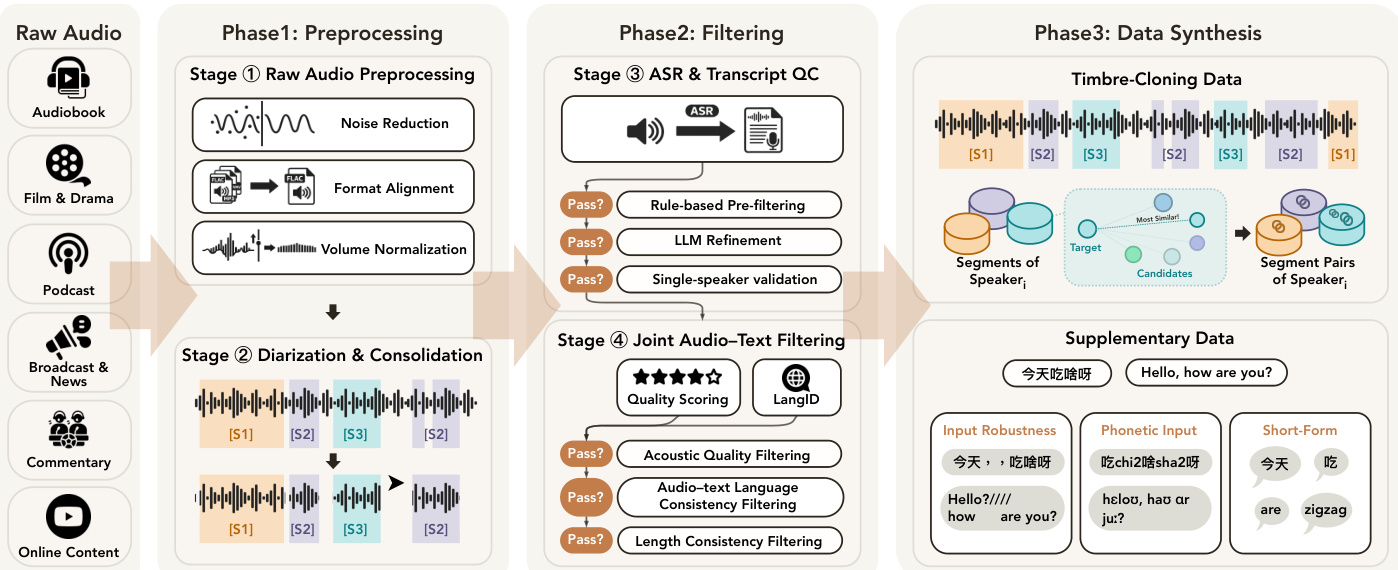
The pretraining follows a curriculum learning strategy with four phases. Phase 1 focuses on basic alignment acquisition using the main filtered corpus. Phase 2 expands capabilities under a stable high learning rate, introducing timbre-cloning and control-oriented data. Phase 3 performs linear-decay mixture rebalancing and quality consolidation. Finally, Phase 4 extends the context window for long-form generation. This staged approach ensures the model learns core text-speech mappings before tackling more complex control tasks and long-context dependencies.
Experiment
The evaluation assesses the MOSS-Audio-Tokenizer and speech generation models through benchmarks on fidelity, voice cloning, multilingual robustness, and controllability. Findings indicate that the tokenizer outperforms open-source baselines across bitrate regimes, while the generation architectures reveal a trade-off where the Local-Transformer variant excels in speaker similarity and the standard model better supports duration control and ultra-long generation. Despite cumulative speaker drift in extended outputs, the system demonstrates practical usability for phoneme-level editing and zero-shot cloning without requiring dedicated fine-tuning.
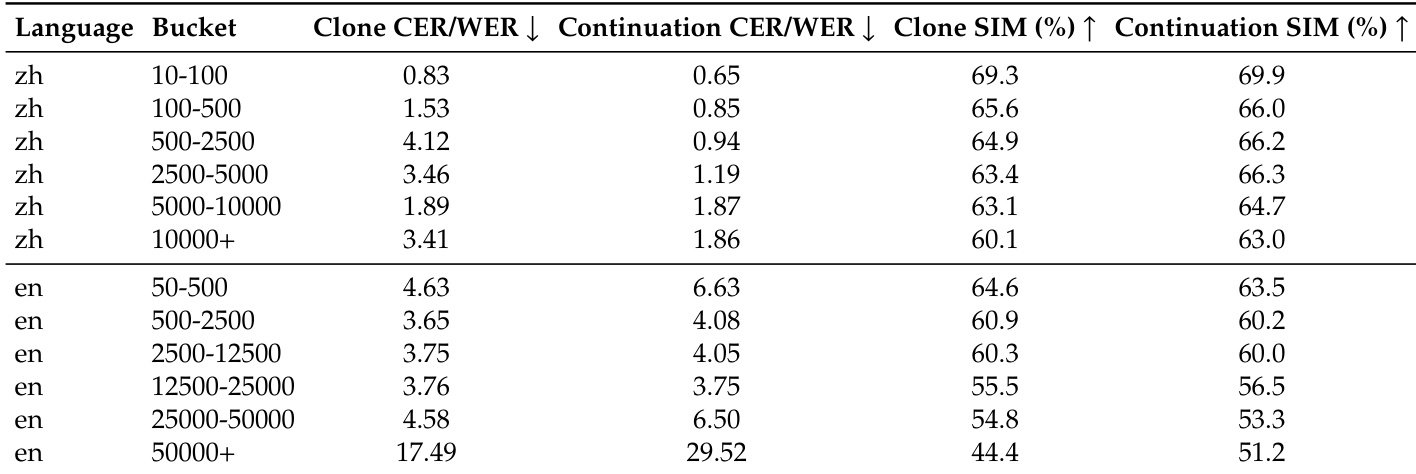
The the the table evaluates ultra-long speech generation performance, tracking content fidelity and speaker similarity across increasing duration buckets for Chinese and English. Results show that content accuracy remains stable for Chinese but degrades significantly for English at the longest horizons. Speaker similarity generally declines as duration increases, with the Continuation mode demonstrating better preservation of speaker identity at extended lengths compared to the Clone mode. Chinese generation maintains low error rates and high speaker similarity across all duration buckets. English content fidelity degrades sharply at the longest duration, showing a substantial increase in word error rates. Continuation mode preserves speaker similarity better than Clone mode at the longest generation lengths.
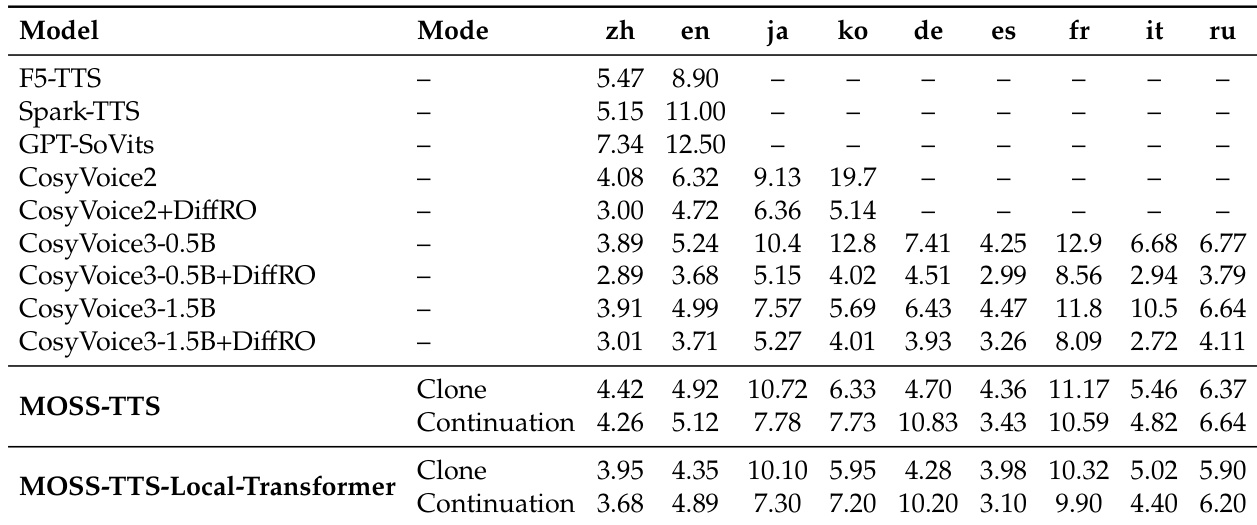
This evaluation assesses multilingual voice cloning capabilities across nine languages, comparing MOSS-TTS architectures against various open-source baselines. The results demonstrate that the model achieves competitive performance in European languages without task-specific fine-tuning, though performance is notably lower for Japanese and Korean. Comparisons between inference modes reveal that Continuation often yields different error profiles compared to Clone mode, particularly affecting non-English languages. MOSS-TTS outperforms smaller baseline models in several European languages including German, French, and Russian. Zero-shot cloning performance is consistently weaker for Japanese and Korean compared to Chinese and English. Continuation mode reduces error rates for Japanese relative to Clone mode across both MOSS-TTS architectures.
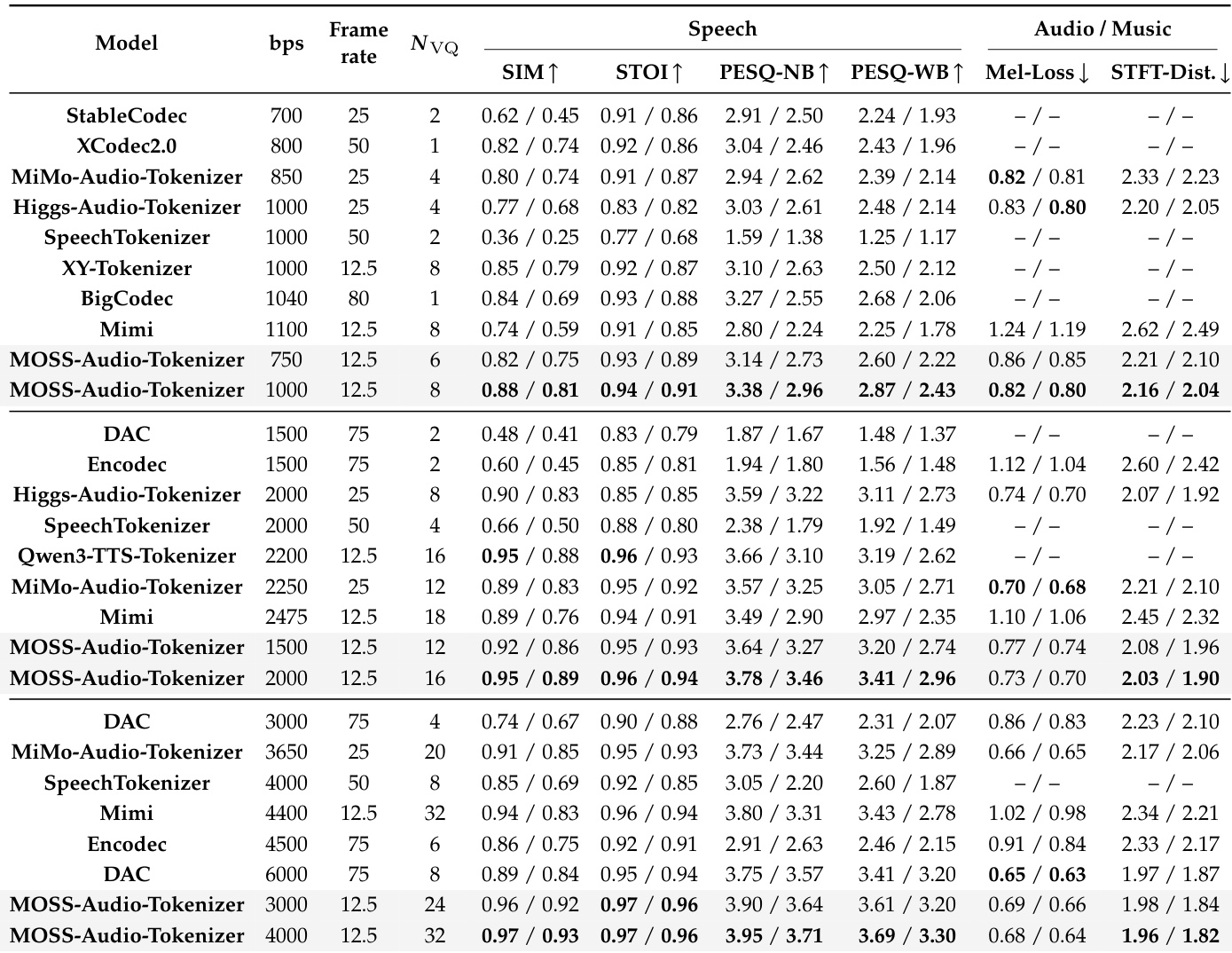
The authors evaluate the MOSS-Audio-Tokenizer against state-of-the-art open-source models across low, medium, and high bitrate regimes to assess reconstruction fidelity. Results demonstrate that the proposed tokenizer consistently outperforms baselines in speech reconstruction quality while maintaining competitive performance on general audio and music tasks. MOSS-Audio-Tokenizer achieves the highest scores in speech metrics such as speaker similarity and intelligibility across all bitrate categories. Reconstruction quality improves steadily as the bitrate increases, indicating effective utilization of model capacity. The model remains competitive on general audio and music benchmarks compared to specialized tokenizers like Encodec and Mimi.
The authors evaluate phoneme-level pronunciation control by testing partial replacement of short spans and full replacement of entire sentences in both Chinese and English. Results indicate that the model achieves low error rates across all conditions, demonstrating practical usability for fine-grained pronunciation editing. Partial replacement settings consistently yield lower error rates compared to full sentence replacement for both languages. Chinese pronunciation control demonstrates lower error rates than English across both experimental settings. The model maintains low span-only error rates, indicating effective control over phoneme-level generation.

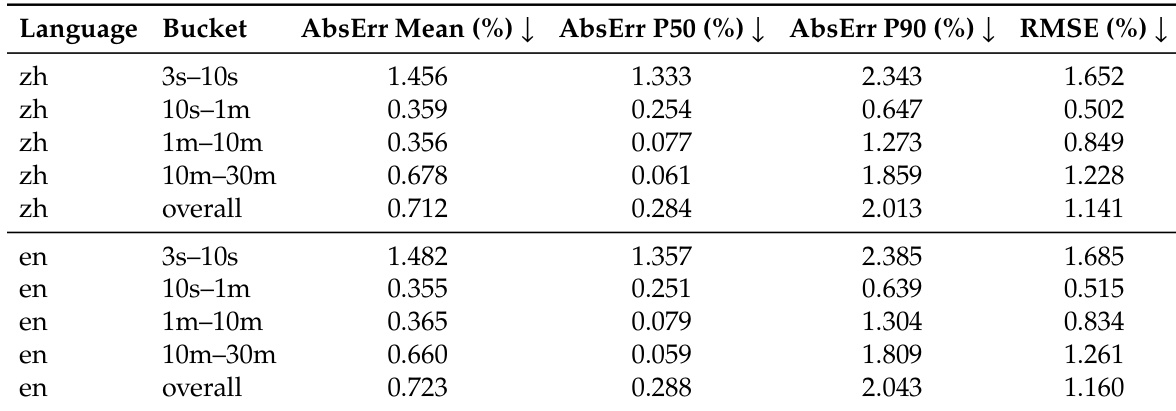
The provided the the table evaluates the token-level duration control of the speech generation model across Chinese and English languages. It reports relative duration errors across various time buckets, demonstrating that the model effectively matches target durations for utterances ranging from a few seconds to half an hour. The results indicate strong controllability that remains robust even as the duration of the generated speech increases. The model exhibits consistent duration control performance across both Chinese and English languages. Accuracy is highest for utterances ranging from 10 seconds to 10 minutes, where error metrics are minimized. Even for longer segments extending to 30 minutes, the model maintains stable duration prediction with only a marginal increase in error.
This evaluation suite assesses ultra-long speech generation, multilingual cloning, tokenizer fidelity, and fine-grained control over pronunciation and duration across multiple languages. Results indicate that while Chinese performance remains stable over long durations, English and languages such as Japanese and Korean show content fidelity degradation, with Continuation mode demonstrating better speaker identity preservation than Clone mode. Furthermore, the proposed audio tokenizer achieves superior speech reconstruction quality, while the generation model demonstrates robust controllability for phoneme-level editing and duration matching up to thirty minutes.