Command Palette
Search for a command to run...
MosaicMem : mémoire spatiale hybride pour des modèles mondiaux vidéo contrôlables
MosaicMem : mémoire spatiale hybride pour des modèles mondiaux vidéo contrôlables
Résumé
Les modèles de diffusion vidéo dépassent progressivement la génération de courts extraits plausibles pour évoluer vers des simulateurs de monde devant maintenir une cohérence face aux mouvements de caméra, aux revisites et aux interventions. Pourtant, la mémoire spatiale demeure un goulot d'étranglement majeur : les structures 3D explicites peuvent améliorer la cohérence basée sur la reprojection, mais peinent à représenter des objets en mouvement, tandis que les mémoires implicites produisent souvent des mouvements de caméra inexacts, même lorsque les poses sont correctes. Nous proposons Mosaic Memory (MosaicMem), une mémoire spatiale hybride qui élève des patches en 3D pour une localisation fiable et une récupération ciblée, tout en exploitant les capacités de conditionnement natives du modèle pour préserver une génération conforme au prompt. MosaicMem assemble des patches spatialement alignés dans la vue interrogée via une interface de type « patch-and-compose », conservant ce qui doit persister tout en permettant au modèle d'inpaint ce qui doit évoluer. Grâce au conditionnement caméra PRoPE et à deux nouvelles méthodes d'alignement de mémoire, les expériences démontrent une meilleure adhérence aux poses par rapport aux mémoires implicites, ainsi qu'une modélisation dynamique supérieure aux baselines explicites. MosaicMem permet en outre une navigation à l'échelle de la minute, une édition de scène basée sur la mémoire et un déroulement autoregressif.
One-sentence Summary
Researchers from the University of Toronto, Georgia Tech, and Osaka University propose MosaicMem, a hybrid spatial memory that lifts patches into 3D for precise localization while using implicit conditioning for dynamic evolution, enabling minute-level navigation and scene editing in controllable video world models.
Key Contributions
- The paper introduces MosaicMem, a hybrid spatial memory that lifts image patches into 3D for precise localization and targeted retrieval while using the model's native conditioning to handle dynamic scene changes.
- This work incorporates PROPE as a camera conditioning interface to enable camera-controlled video generation with substantially improved viewpoint controllability and pose adherence.
- Experiments demonstrate that the method achieves more robust dynamic modeling than explicit baselines and more accurate motion consistency than implicit memory, supported by a new benchmark designed to test retrieval under complex revisits.
Introduction
Video diffusion models are evolving into world simulators capable of long-horizon planning and interactive exploration, yet their effectiveness is currently limited by inadequate spatial memory systems. Prior explicit approaches rely on rigid 3D structures that struggle to represent moving objects, while implicit methods store state in latent representations but often suffer from camera drift and inefficient context usage. To address these trade-offs, the authors introduce MosaicMem, a hybrid spatial memory that lifts image patches into 3D for precise localization while retaining the model's native conditioning to handle dynamic changes. This patch-and-compose interface enables reliable retrieval and targeted inpainting, resulting in superior pose adherence and robust dynamic modeling for minute-level navigation and scene editing.
Dataset
-
Dataset Composition and Sources: The authors introduce MosaicMem-World, a benchmark aggregating data from four complementary sources to address the lack of explicit revisitation in standard first-person video datasets. These sources include curated Unreal Engine 5 scenes for decoupled control and long-range retrieval, commercial game environments like Cyberpunk 2077 for complex dynamics, real-world first-person captures for realistic appearance variations, and selected sequences from the existing Sekai dataset based on high revisit frequency.
-
Key Details for Each Subset: Each source contributes on the order of tens of hours of footage. The Unreal Engine 5 subset features trajectories with single and mixed actions alongside explicit revisited segments. The commercial game subset captures dense interactions, while the real-world subset introduces noise and illumination changes. The Sekai subset is filtered specifically for sequences with the highest revisit frequency according to camera trajectories.
-
Model Usage and Training Strategy: The dataset supports training and evaluation focused on spatial memory under viewpoint changes. The authors use the data to evaluate a model's ability to retain stable scene structure, re-localize after substantial camera motion, and reuse stored geometry. To enable compositional training, the authors concatenate dynamic descriptions across consecutive segments to construct training clips of arbitrary length.
-
Processing and Annotation Pipeline: The authors apply a unified preprocessing pipeline that reconstructs depth and camera motion using Depth Anything V3 or VIPE to create a consistent geometric scaffold. Videos are partitioned into fixed-length segments of 32 frames, where Gemini 3 generates two complementary textual descriptions per segment: one for static scene content and another for temporal dynamics. Finally, the dataset is filtered to remove videos with inaccurate 3D estimates or excessive motion blur.
Method
The authors formulate the task as generating a long-horizon video rollout X conditioned on an input image I, text prompts L, and camera poses C. They build upon text+image-to-video (TI2V) models, learning the joint distribution of the entire video via Flow Matching. The generative process follows a probability-flow ODE where a neural vector field uθ transports Gaussian noise X0 to the target video state X1:
dλdXλ=uθ(Xλ,λ∣I,L,C,M),X1=X0+∫Λ1uθ(Xλ,λ∣I,L,C,M) dλwhere M denotes spatial memory. To address limitations in existing spatial memory paradigms, the authors introduce Mosaic Memory, a hybrid design that transcends the trade-offs between explicit and implicit approaches.
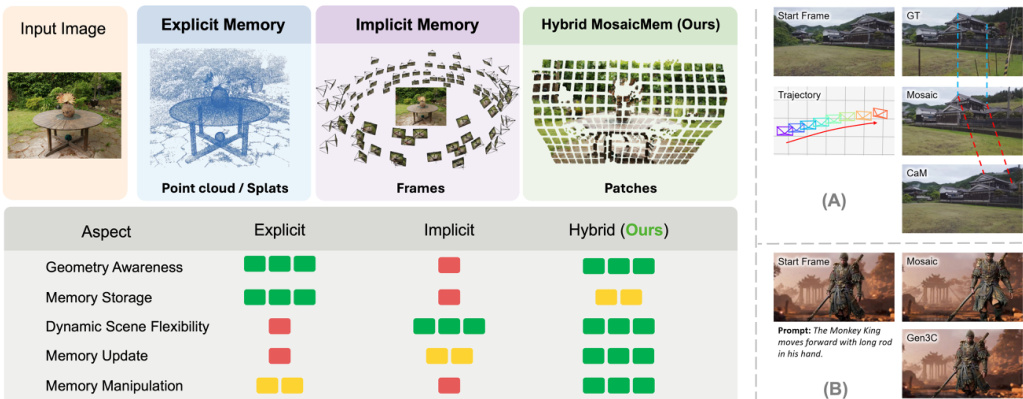
As illustrated in the comparison diagram, explicit methods store scene evidence as 3D primitives like points or splats, while implicit methods retain memory at the granularity of entire video frames. Mosaic Memory utilizes patches as the basic unit of memory to integrate the complementary strengths of both. For a given patch P, the authors first perform a geometric lifting step analogous to explicit memory pipelines, using an off-the-shelf 3D estimator to infer depth and lift the patch into 3D. When the observer moves to a new viewpoint, the retrieved patch is provided to the DiT as context, similar to implicit memory conditioning. A modified RoPE mechanism conveys the correspondence between this memory patch and the noised latent tokens under the queried camera. This organic combination allows the generator to flexibly decide whether to rely on spatial memory for consistent reconstruction or to synthesize unseen content and new dynamics according to the text prompt.
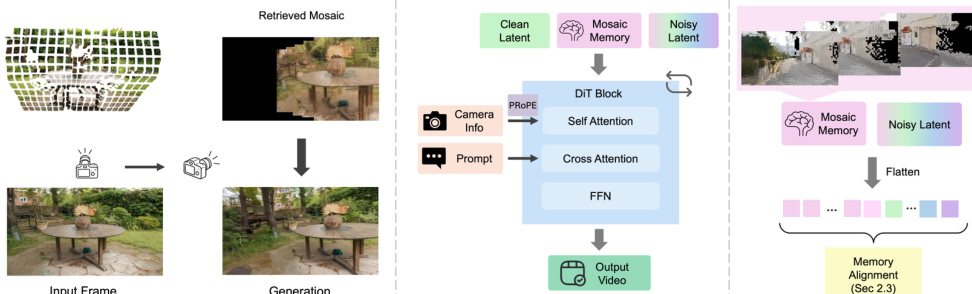
The pipeline overview demonstrates how retrieved mosaic patches are flattened and concatenated to the token sequence as conditioning. To establish geometry-consistent correspondence between retrieved memory patches and the current view, the authors improve alignment using two warping mechanisms. Warped RoPE is a new positional encoding mechanism that aligns patches across time and camera motion in latent space. Each retrieved memory patch P is associated with depth D and camera intrinsics/extrinsics. Given its original RoPE coordinates (u,v), the patch is back-projected into 3D world space and re-projected into the target camera to determine new coordinates (u′,v′):
(u′,v′)=Π(KjTjTi−1Ki−1(u,v,D)),where Π(⋅) denotes the perspective projection. Alternatively, Warped Latent offers a complementary alignment mechanism by directly transforming the retrieved memory patches in the feature space through spatial resampling using the reprojected coordinates.
Although Mosaic Memory implicitly provides some camera-motion cues, a dedicated camera control module is introduced for reliable trajectory control. The authors adopt Projective Positional Encoding (PROPE) as a principled camera-conditioning interface for DiT-based video generation. PROPE encodes the complete relative relationship between two views via the projective transform and applies it through transformed attention. Given per-frame camera projection matrices P~i, the module injects relative camera frustum geometry directly into self-attention. Due to the temporal compression of the 3D VAE, the authors unfold an extra sub-index to ensure each temporally-compressed latent frame attends with the correct per-frame projective conditioning while keeping the PROPE interface unchanged at the attention operator level.
Experiment
- Spatial memory comparisons demonstrate that MosaicMem outperforms explicit and implicit baselines by enabling dynamic scene evolution, accurate camera control, and faithful reconstruction of previously observed objects over long horizons.
- Ablation studies confirm that combining PROPE with dual warping mechanisms significantly improves camera motion accuracy and memory retrieval robustness compared to using individual components or simpler control methods.
- Long-horizon generation experiments validate the ability to produce minute-level navigation videos with consistent spatial alignment, whereas baseline models suffer from accumulating artifacts and generation collapse.
- Memory manipulation tests show that editing stored spatiotemporal patches allows for seamless scene concatenation and surreal spatial arrangements, enabling users to transition between distinct environments.
- Autoregressive generation evaluations prove that the Mosaic Forcing variant achieves real-time performance with superior visual quality and temporal consistency, effectively resolving boundary regeneration issues found in single-strategy models.