Command Palette
Search for a command to run...
HopChain : Synthèse de données multi-sauts pour un raisonnement vision-langage généralisable
HopChain : Synthèse de données multi-sauts pour un raisonnement vision-langage généralisable
Résumé
Les modèles vision-langage (VLM) démontrent de solides capacités multimodales, mais peinent encore à effectuer un raisonnement vision-langage fin et détaillé. Nous constatons que le raisonnement par chaîne de pensée longue (CoT) met en évidence des modes d'échec diversifiés, notamment des erreurs de perception, de raisonnement, de connaissances et d'hallucinations, susceptibles de s'aggraver à travers les étapes intermédiaires. Cependant, la majorité des données vision-langage existantes utilisées pour l'apprentissage par renforcement avec récompenses vérifiables (RLVR) ne comportent pas de chaînes de raisonnement complexes reposant tout au long du processus sur des preuves visuelles, laissant ainsi ces faiblesses largement masquées.Nous proposons donc HopChain, un cadre évolutif conçu pour synthétiser des données de raisonnement vision-langage multi-sauts destinées à l'entraînement par RLVR des VLM. Chaque requête multi-sauts synthétisée constitue une chaîne logiquement dépendante de sauts ancrés dans des instances concrètes, où les sauts antérieurs établissent les instances, ensembles ou conditions nécessaires aux sauts ultérieurs, tandis que la réponse finale demeure un nombre spécifique et non ambigu, adapté à l'utilisation de récompenses vérifiables.Nous avons entraîné les modèles Qwen3.5-35B-A3B et Qwen3.5-397B-A17B dans deux configurations RLVR : l'utilisation exclusive des données originales, et l'utilisation combinée des données originales et des données multi-sauts générées par HopChain. Une comparaison a été effectuée sur 24 benchmarks couvrant les domaines STEM et énigmes, la VQA générale, la reconnaissance de texte et la compréhension de documents, ainsi que la compréhension vidéo. Bien que ces données multi-sauts n'aient pas été synthétisées pour un benchmark spécifique, elles améliorent 20 des 24 benchmarks sur les deux modèles, témoignant de gains étendus et généralisables. De manière cohérente, le remplacement des requêtes chaînées complètes par des variantes à demi-sauts ou à saut unique réduit le score moyen sur cinq benchmarks représentatifs, passant de 70,4 à 66,7 et 64,3 respectivement.Il est à noter que les gains liés aux multi-sauts atteignent leur pic dans le contexte du raisonnement vision-langage par CoT longue, dépassant 50 points dans le régime ultra-long-CoT. Ces expériences établissent HopChain comme un cadre efficace et évolutif pour la synthèse de données multi-sauts, améliorant ainsi le raisonnement vision-langage généralisable.
One-sentence Summary
The Qwen Team and Tsinghua University introduce HopChain, a scalable framework synthesizing multi-hop vision-language reasoning data to address fine-grained errors in VLMs. By generating logically dependent, instance-grounded chains with verifiable numeric answers, HopChain significantly boosts generalizable performance across diverse benchmarks, particularly excelling in long CoT reasoning scenarios.
Key Contributions
- The paper introduces HopChain, a scalable framework that synthesizes multi-hop vision-language reasoning data by constructing logically dependent chains where earlier hops establish instances or conditions required for subsequent steps, ensuring continuous visual re-grounding.
- This work demonstrates that training VLMs with HopChain's synthesized data improves performance on 20 of 24 diverse benchmarks, including STEM, General VQA, and Video Understanding, indicating broad and generalizable gains without benchmark-specific tailoring.
- Experiments show that multi-hop reasoning gains peak in long-CoT regimes with improvements exceeding 50 points, while ablation studies confirm that reducing chain complexity significantly lowers average scores, validating the necessity of full multi-hop structures for robust reasoning.
Introduction
Vision-language models (VLMs) excel at multimodal tasks but often fail during long chain-of-thought reasoning due to compounding errors like hallucination and weak visual grounding. Existing training data for reinforcement learning with verifiable rewards (RLVR) rarely requires complex, multi-step visual evidence, leaving these critical weaknesses unaddressed during model optimization. The authors introduce HopChain, a scalable framework that synthesizes multi-hop reasoning data where each step logically depends on previous visual findings to force continuous re-grounding. This approach generates queries with verifiable numerical answers that expose diverse failure modes, resulting in broad performance gains across 20 of 24 benchmarks without targeting specific downstream tasks.
Dataset
-
Dataset Composition and Sources: The authors synthesize a multi-hop vision-language reasoning dataset designed to force models to seek visual evidence at every step of long-CoT reasoning. The data originates from raw image collections that contain sufficient detectable instances, processed through a four-stage pipeline to create queries that chain multiple reasoning steps into a single task.
-
Key Details for Each Subset:
- Reasoning Levels: Queries are structured as Level 3 tasks that combine Level 1 (single-object perception like text reading or attribute identification) and Level 2 (multi-object perception like spatial or counting relations).
- Hop Types: Each query must include both Perception-level hops (switching between single and multi-object tasks) and Instance-chain hops (moving to a new object based on the previous one).
- Answer Format: All queries terminate in a specific, unambiguous numerical answer to ensure compatibility with RLVR verification.
- Dependency Rules: Substeps must form a logically dependent chain where earlier hops establish the instances or conditions required for later hops, preventing shallow shortcuts.
-
Data Usage and Processing:
- Stage 1 (Category Identification): A VLM identifies semantic categories present in an input image without localization.
- Stage 2 (Instance Segmentation): SAM3 generates segmentation masks and bounding boxes to resolve categories into concrete, spatially localized instances.
- Stage 3 (Query Generation): The system forms combinations of 3–6 instances and uses a VLM to generate multi-hop queries. The model receives the original image plus cropped patches of each instance to aid design, though these patches are not available during the actual reasoning task.
- Stage 4 (Annotation and Calibration): Four human annotators independently solve each query; only queries where all four agree on the numerical answer are retained. Difficulty calibration then removes queries where a weaker model achieves 100% accuracy, ensuring the final dataset contains verified, challenging examples.
-
Cropping and Metadata Strategy:
- Cropping: During the design phase, the pipeline extracts cropped patches for each detected instance using bounding boxes. These patches serve as reference material for the VLM to understand appearance and location but are excluded from the final training prompt to simulate real-world conditions.
- Metadata Construction: The prompt explicitly provides the coordinates of each instance in a 0–1000 range and lists the specific object instances that must be considered for the task.
- Quality Control: The pipeline filters out queries with ambiguous references during human annotation and discards those that are too easy during model-based calibration, ensuring high-quality training signals.
Method
The authors propose a comprehensive framework that integrates scalable data synthesis with advanced reinforcement learning techniques to enhance the multi-hop reasoning capabilities of Vision-Language Models (VLMs). The methodology is divided into three core components: the generation of structured multi-hop training data, the formulation of the reinforcement learning objective, and the optimization algorithm used for policy updates.
Scalable Multi-Hop Data Synthesis
To address the lack of complex reasoning chains in typical training data, the authors leverage a scalable data synthesis pipeline designed to enforce dependency-linked hops with repeated visual grounding. Refer to the framework diagram for an overview of the HopChain Framework for Multi-Hop Data Synthesis.
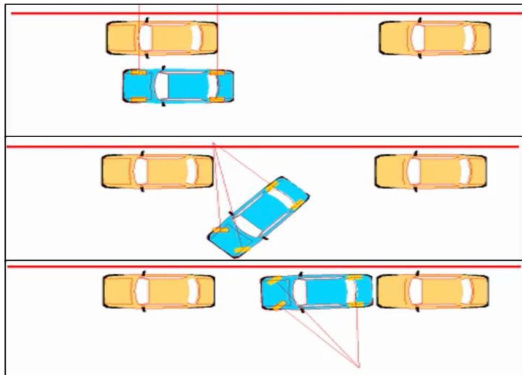
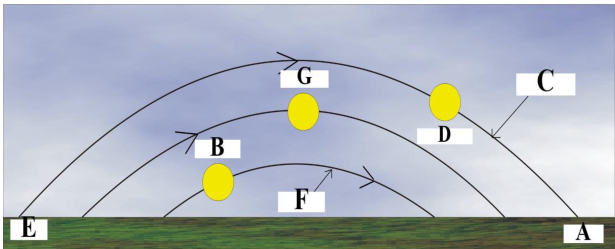
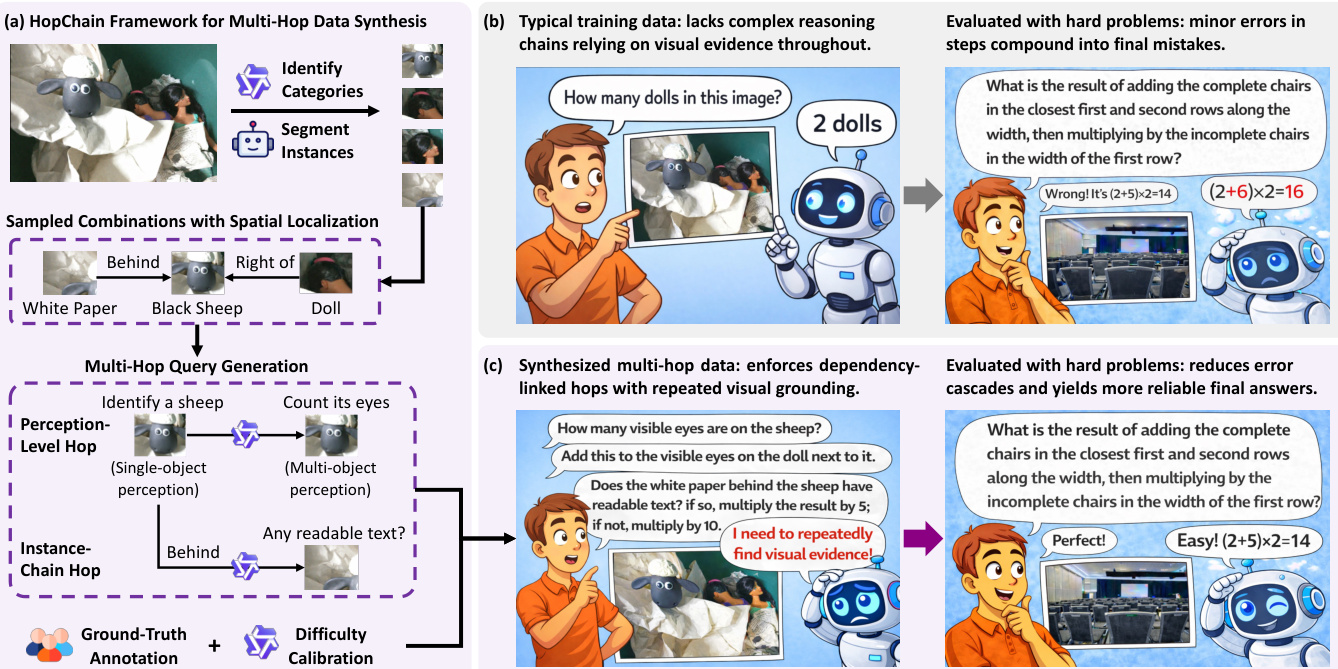 This pipeline utilizes strong foundation models, including VLMs for object detection and SAM for instance segmentation, to construct structured queries from raw images. The synthesis process imposes strict constraints to ensure high quality and generalizability. Each generated query must involve a genuine multi-hop reasoning structure where the instance required at the current hop can only be identified from instances established in earlier hops. Furthermore, the queries are designed to maximize instance coverage, ensuring that every object in a selected combination plays a meaningful role in the reasoning chain. The authors also enforce unambiguous phrasing and deterministic solutions, prohibiting the use of low-level visual features like bounding box colors to locate information. This approach forces the model to recover and retain intermediate visual evidence rather than relying on language-only heuristics. Examples of the visual complexity handled by this synthesis process include spatial reasoning tasks involving vehicle positions and logical reasoning tasks involving trajectory analysis.
This pipeline utilizes strong foundation models, including VLMs for object detection and SAM for instance segmentation, to construct structured queries from raw images. The synthesis process imposes strict constraints to ensure high quality and generalizability. Each generated query must involve a genuine multi-hop reasoning structure where the instance required at the current hop can only be identified from instances established in earlier hops. Furthermore, the queries are designed to maximize instance coverage, ensuring that every object in a selected combination plays a meaningful role in the reasoning chain. The authors also enforce unambiguous phrasing and deterministic solutions, prohibiting the use of low-level visual features like bounding box colors to locate information. This approach forces the model to recover and retain intermediate visual evidence rather than relying on language-only heuristics. Examples of the visual complexity handled by this synthesis process include spatial reasoning tasks involving vehicle positions and logical reasoning tasks involving trajectory analysis.
Reinforcement Learning with Verifiable Rewards The training process employs Reinforcement Learning with Verifiable Rewards (RLVR) for VLMs. This framework closely parallels RLVR for Large Language Models but processes both an image and a text query as input to generate a textual chain-of-thought culminating in a verifiable answer prediction. The primary objective is to maximize the expected reward, defined as:
J(π)=E(I,q,a)∼D,o∼π(⋅∣I,q)[R(o,a)],whereR(o,a)={1.00.0if is_equivalent(o,a),otherwise.Here, I, q, and a denote the image, text query, and ground-truth answer, respectively, sampled from dataset D, and o represents the response generated by policy π conditioned on I and q. The reward function provides a binary signal based on whether the generated output is equivalent to the ground truth.
Soft Adaptive Policy Optimization To mitigate potential instability and inefficiency caused by hard clipping in prior RLVR algorithms, the authors introduce Soft Adaptive Policy Optimization (SAPO). This method substitutes hard clipping with a temperature-controlled soft gate. The optimization objective for VLMs is formulated as:
J(θ)=E(I,q,a)∼D,{oi}i=1G∼πold(⋅∣I,q)G1i=1∑G∣oi∣1t=1∑∣oi∣fi,t(ri,t(θ))A^i,t,where the probability ratio ri,t(θ) is defined as the ratio of the current policy to the old rollout policy. The advantage term A^i,t is computed by normalizing the reward Ri across a group of samples. The function fi,t(x) acts as a soft gate controlled by temperatures τpos and τneg for positive and negative tokens, respectively. This adaptive mechanism allows for smoother policy updates and improved training stability compared to traditional clipping methods.
Experiment
- Analysis of diverse failure modes in long Chain-of-Thought reasoning reveals that errors are not isolated but compounding, with perception mistakes often triggering downstream reasoning, knowledge, and hallucination failures across various visual scenarios.
- Main benchmark evaluations demonstrate that augmenting standard RLVR training with HopChain-synthesized multi-hop data yields broad, generalizable improvements across 20 out of 24 benchmarks for both small and large model scales, covering STEM, general VQA, document understanding, and video tasks.
- Ablation studies confirm that preserving the full multi-hop structure during training is essential, as models trained on shortened or single-hop variants show significantly lower performance, validating the necessity of maintaining long cross-hop dependencies.
- Further analysis indicates that the proposed method effectively strengthens robustness in ultra-long reasoning chains, covers a wide spectrum of query difficulties, and corrects a diverse range of error types rather than addressing only a narrow subset of failure modes.