Command Palette
Search for a command to run...
InCoder-32B : modèle fondationnel de code pour des scénarios industriels
InCoder-32B : modèle fondationnel de code pour des scénarios industriels
Résumé
Les récents grands modèles de langage (LLM) spécialisés dans le code ont enregistré des progrès remarquables sur des tâches de programmation générales. Néanmoins, leurs performances se dégradent considérablement dans des scénarios industriels exigeant un raisonnement sémantique lié au matériel, la maîtrise de constructions langagières spécialisées et le respect de contraintes strictes en ressources. Pour relever ces défis, nous présentons InCoder-32B (Industrial-Coder-32B), le premier modèle fondationnel de code à 32 milliards de paramètres unifiant l'intelligence du code dans les domaines de la conception de puces, de l'optimisation de noyaux GPU, des systèmes embarqués, de l'optimisation des compilateurs et de la modélisation 3D. En adoptant une architecture efficiente, nous avons entraîné InCoder-32B à partir de zéro selon un pipeline comprenant : un pré-entraînement sur du code général, un affinage (annealing) sur des corpus industriels soigneusement sélectionnés, un entraînement intermédiaire (mid-training) étendant progressivement le contexte de 8K à 128K tokens grâce à des données synthétiques de raisonnement industriel, et un post-entraînement fondé sur une vérification ancrée dans l'exécution. Nous avons mené une évaluation extensive sur 14 benchmarks généraux de code et 9 benchmarks industriels couvrant 4 domaines spécialisés. Les résultats démontrent que InCoder-32B atteint des performances hautement compétitives sur les tâches générales tout en établissant des références open-source solides dans les domaines industriels.
One-sentence Summary
Researchers from Beihang University and IQest Research introduce InCoder-32B, a unified 32B-parameter foundation model that overcomes hardware constraints in industrial coding through progressive context extension and execution-grounded verification, establishing new open-source baselines for chip design and GPU optimization.
Key Contributions
- The paper introduces InCoder-32B, a 32B-parameter foundation model that unifies code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling through a specialized three-stage training pipeline.
- A comprehensive evaluation suite is assembled comprising 14 general code benchmarks and 9 industrial benchmarks spanning four specialized domains to rigorously assess performance in hardware-aware programming scenarios.
- Extensive ablation studies demonstrate that repository transition data improves planning capabilities, mid-training reasoning trajectories enhance robustness under distribution shifts, and thinking paths unlock emergent capabilities absent in standard instruction tuning.
Introduction
Code large language models excel at general software tasks but struggle in industrial scenarios that demand reasoning about hardware semantics, specialized language constructs, and strict resource constraints. Prior work often addresses these needs in isolated domains like chip design or GPU optimization, resulting in fragmented solutions that fail to unify capabilities across the broader spectrum of industrial engineering. The authors introduce InCoder-32B, the first 32B-parameter foundation model designed to bridge this gap by unifying code intelligence for chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. They achieve this through a three-stage training pipeline that incorporates curated industrial data, progressive context scaling up to 128K tokens, and execution-grounded verification to ensure hardware-aware correctness.
Dataset
Dataset Composition and Sources
The authors construct a specialized industrial code dataset to address the scarcity of hardware and low-level systems data in general-purpose corpora. The data originates from three primary sources:
- Public Repositories: A three-step recall strategy retrieves code using rule-based filtering, FastText classification, and domain-adapted semantic encoders to capture Verilog, CUDA, and embedded C code.
- Technical Literature: Optical Character Recognition (OCR) extracts code snippets and structured content from hardware reference manuals and technical books.
- Domain-Specific Web Data: The collection includes engineering reports, vendor documentation, and technical forums to capture practical usage patterns.
Key Details for Each Subset
The dataset is organized into curated and synthetic components across four industrial domains: digital circuit design, GPU computing, embedded systems, and CAD automation.
- Curated Industrial Code: Includes authentic code commits, file-level Fill-in-the-Middle (FIM) samples, and auxiliary artifacts like testbenches, timing constraints, and profiling logs.
- Synthetic Industrial QA: Generated through a three-stage pipeline involving scenario specification by engineers, seed code generation, and automated verification to ensure factual correctness.
- Agent Trajectories: Multi-step debugging and repair sequences following a Thought-Action-Observation cycle, capturing feedback from simulators and compilers.
- Post-Training SFT Samples: A collection of 2.5 million samples categorized into direct solutions, defect repairs, and performance optimizations, all grounded in real execution environments.
Model Usage and Training Strategy
The authors utilize the data across three distinct training stages to build the InCoder-32B model.
- Stage 1 (Pre-Training): The model trains on the curated industrial code using autoregressive language modeling and Fill-in-the-Middle completion on 4,096 GPUs.
- Stage 2 (Pre-Training): The authors mix synthetic reasoning data with curated artifacts. In the first sub-stage, synthetic QA pairs comprise 40% of the mixture, followed by agent trajectories (20%), commits (15%), artifacts (15%), and FIM (10%). The second sub-stage shifts focus to long-context data by increasing agent trajectories to 30% and FIM to 25%.
- Stage 3 (Post-Training): The model undergoes Supervised Fine-Tuning (SFT) for approximately 4,900 steps using the 2.5 million execution-verified samples. This stage emphasizes learning the full engineering workflow, including debugging and optimization, rather than just code generation.
Processing and Verification Details
To ensure high fidelity, the authors implement rigorous processing and verification pipelines that mirror real-world engineering workflows.
- Cleaning and Refinement: The pipeline filters for licenses and PII, removes duplicates at multiple levels (hash, token, repository), and normalizes formatting. All samples undergo AST comparison and re-compilation to verify correctness.
- Simulation Environments: The authors reconstruct four industrial environments in software to validate data. This includes an STM32F407 microcontroller simulator (Renode) for embedded firmware, native x86-64 execution for assembly optimization, RTL simulation for Verilog, and CAD script execution for geometry generation.
- Execution-Grounded Verification: Every candidate solution in the SFT dataset is validated through actual compilation, simulation, or test execution. Failed solutions are paired with compiler errors and runtime logs to create closed-loop repair trajectories.
- Metadata Construction: The authors add structured annotations including cross-file dependencies, platform constraints, and natural language descriptions to align code with text.
Method
The authors develop InCoder-32B, a decoder-only Transformer architecture designed for industrial code intelligence. The training process is structured into three distinct phases: Pre-train, Mid-train, and Post-train, as illustrated in the framework diagram below.
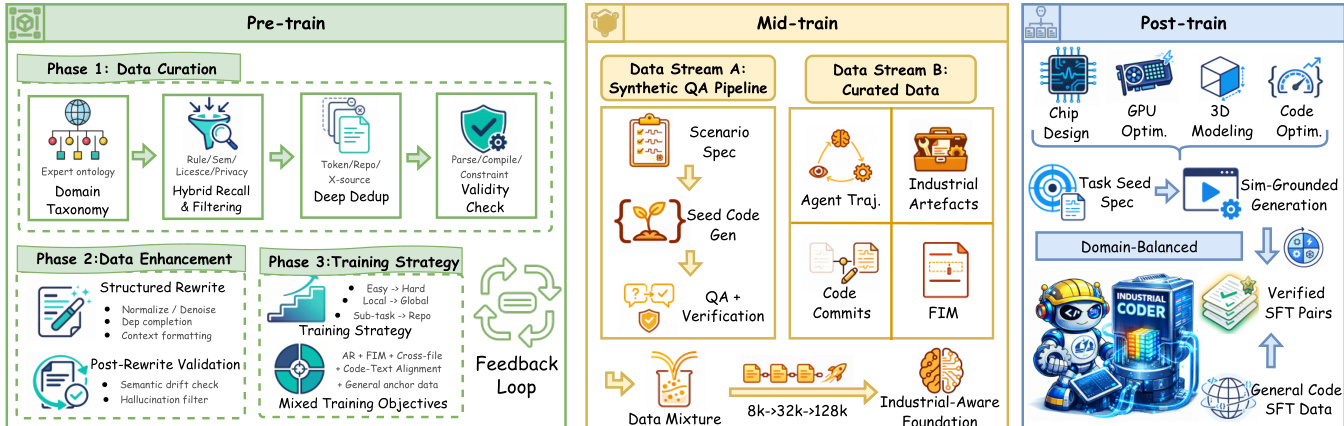
During the Pre-train phase, the authors focus on Data Curation, Data Enhancement, and Training Strategy. Data Curation involves establishing a domain taxonomy, applying hybrid recall and filtering rules, performing deep deduplication, and conducting validity checks. Data Enhancement includes structured rewriting to normalize and denoise code, followed by post-rewrite validation to check for semantic drift. The training strategy employs a curriculum that progresses from easy to hard tasks and from local to global contexts, utilizing mixed training objectives that include autoregressive modeling and fill-in-the-middle (FIM) completion.
The Mid-train phase is critical for extending the model's capabilities. It utilizes two data streams: a Synthetic QA Pipeline and Curated Data. The Synthetic QA Pipeline generates scenario specifications, seed code, and QA pairs with verification. The Curated Data stream includes agent trajectories, industrial artifacts, code commits, and FIM data. A key component of this phase is the progressive context extension strategy, which increases the context window from 8K to 32K tokens and finally to 128K tokens. This allows the model to handle file-level tasks initially and later unlock long-context capabilities for extended debugging and multi-file refactoring.
In the Post-train phase, the model undergoes Supervised Fine-Tuning (SFT) using domain-balanced data. This includes task seed specifications and sim-grounded generation to produce verified SFT pairs. The process ensures the model is ready for specific industrial domains such as Chip Design, GPU Optimization, 3D Modeling, and Code Optimization.
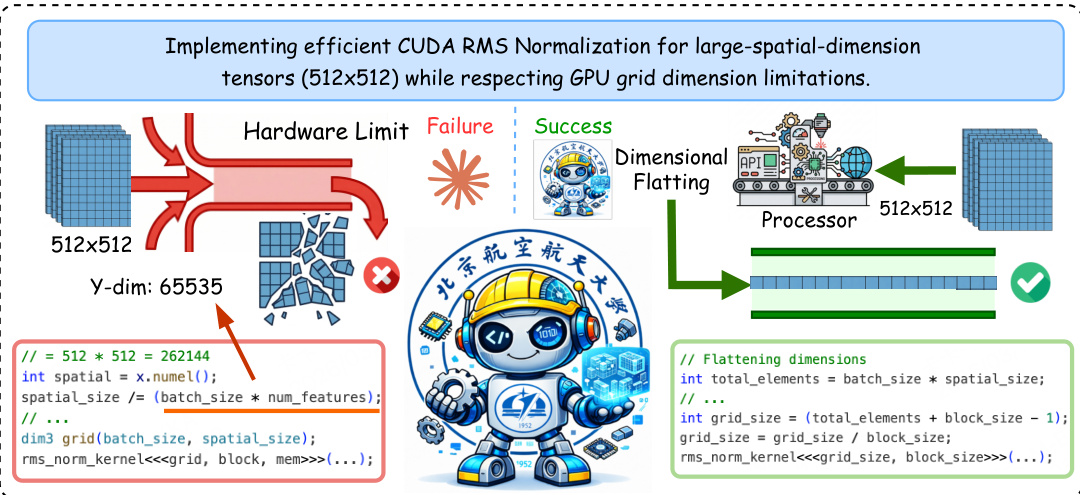
To ensure practicality in industrial settings, the authors replicate real-world engineering environments. For instance, in GPU optimization, the system handles hardware limitations by employing dimensional flattening techniques when standard grid dimensions are exceeded. This is demonstrated in the implementation of efficient CUDA RMS Normalization for large-spatial-dimension tensors, where the system successfully navigates hardware limits to produce valid code.
The overall capability coverage spans both general code intelligence and industrial code intelligence, ensuring the model is versatile across various domains.

A feedback-driven repair mechanism is integrated into the pipeline. When a generated candidate fails verification (e.g., compilation error or simulation mismatch), the system captures the full feedback context, including error messages and logs. This feedback is fed back into the generation stage to produce a repaired version, creating a closed-loop repair trajectory that teaches the model to diagnose failures and iterate toward a fix.
Experiment
- General code benchmarks validate that InCoder-32B achieves competitive performance against significantly larger open-weight and proprietary models in code generation, reasoning, and Text2SQL tasks, while ranking first among open-weight baselines on agentic coding and tool-use evaluations.
- Industrial code benchmarks demonstrate that the model outperforms all open-weight competitors and surpasses leading proprietary systems in chip design, GPU kernel optimization, and 3D modeling, establishing strong capabilities in hardware-constrained domains.
- Error analysis reveals that while the model handles broad domain vocabulary well, it still struggles with precise industrial syntax, specific API constraints, and deep functional logic, particularly in scenarios requiring complex hardware semantics or performance optimization.
- Scaling studies confirm that increasing the volume of industrial supervised fine-tuning data consistently improves performance across most benchmarks, indicating that larger datasets effectively enhance architectural reasoning and coding capabilities.
- Ablation findings highlight that repository transition data, mid-training reasoning trajectories, and explicit thinking paths are critical for developing robust planning signals and emergent reasoning abilities in industrial contexts.