Command Palette
Search for a command to run...
Kinema4D : Modélisation cinématique du monde en 4D pour la simulation incarnée spatio-temporelle
Kinema4D : Modélisation cinématique du monde en 4D pour la simulation incarnée spatio-temporelle
Mutian Xu Tianbao Zhang Tianqi Liu Zhaoxi Chen Xiaoguang Han Ziwei Liu
Résumé
La simulation des interactions entre robots et leur environnement constitue un pilier fondamental de l'IA incarnée (Embodied AI). Récemment, quelques travaux ont démontré un potentiel prometteur en exploitant la génération vidéo pour dépasser les contraintes visuelles et physiques rigides des simulateurs traditionnels. Toutefois, ces approches opèrent principalement dans un espace 2D ou sont guidées par des indices environnementaux statiques, négligeant la réalité fondamentale selon laquelle les interactions robot-monde sont intrinsèquement des événements spatio-temporels 4D exigeant une modélisation interactive précise. Afin de restaurer cette essence 4D tout en garantissant un contrôle robotique précis, nous présentons Kinema4D, un nouveau simulateur robotique génératif 4D conditionné par l'action. Ce simulateur décompose l'interaction robot-monde en deux composantes :i) Représentation 4D précise des commandes robotiques : nous pilotons un robot basé sur URDF via la cinématique, générant ainsi une trajectoire de commande robotique 4D précise.ii) Modélisation générative 4D des réactions environnementales : nous projetons la trajectoire robotique 4D sous forme de pointmap, agissant comme signal visuel spatio-temporel, afin de contrôler un modèle génératif capable de synthétiser la dynamique réactive d'environnements complexes en séquences synchronisées RGB/pointmap. Pour faciliter l'entraînement, nous avons constitué un jeu de données à grande échelle nommé Robo4D-200k, regroupant 201 426 épisodes d'interactions robotiques dotés d'annotations 4D de haute qualité. Des expériences approfondies démontrent que notre méthode simule efficacement des interactions physiquement plausibles, géométriquement cohérentes et agnostiques à l'incarnation, reflétant fidèlement diverses dynamiques du monde réel. Pour la première fois, cette approche révèle un potentiel de transfert zero-shot, offrant une base haute fidélité pour faire progresser la prochaine génération de simulation incarnée.
One-sentence Summary
Researchers from Nanyang Technological University and CUHKSZ propose Kinema4D, an action-conditioned 4D generative simulator that uniquely combines kinematic robot control with diffusion-based environmental synthesis to overcome the precision limitations of prior 2D or text-guided models for high-fidelity embodied AI training.
Key Contributions
- The paper introduces Kinema4D, an action-conditioned 4D generative simulator that drives a URDF-based robot via explicit kinematics to create precise control trajectories while using pointmap projections to guide a generative model in synthesizing synchronized RGB and pointmap sequences for environmental reactions.
- A large-scale dataset named Robo4D-200k is curated to support training, comprising 201,426 robot interaction episodes with high-quality 4D annotations derived from both real-world and synthetic demonstrations.
- Extensive experiments demonstrate that the method effectively simulates physically plausible and geometrically consistent interactions, achieving zero-shot transfer capabilities that mirror diverse real-world dynamics.
Introduction
Embodied AI relies on simulating robot-world interactions to scale training and policy evaluation, yet traditional physics engines lack visual realism while recent video-based approaches fail to capture the inherent 4D spatiotemporal nature of these events. Prior methods are limited by their operation in 2D pixel space or their reliance on high-level linguistic instructions and latent embeddings, which lack the precise kinematic guidance needed to model complex physical dynamics like material deformation or occluded object motion. To address these gaps, the authors introduce Kinema4D, an action-conditioned 4D generative simulator that disentangles the process into precise kinematic robot control and generative environmental reaction modeling. By driving a URDF-based robot to create a deterministic 4D trajectory and projecting it as a pointmap signal to guide a generative model, the framework achieves physically plausible and geometrically consistent simulations. The authors also contribute Robo4D-200k, a large-scale dataset of over 200,000 annotated robot interaction episodes, enabling high-fidelity embodied simulation with potential zero-shot transfer capabilities.
Dataset
Robo4D-200k Dataset Overview
-
Dataset Composition and Sources The authors aggregate 201,426 high-fidelity episodes into the Robo4D-200k dataset by combining real-world robotic demonstrations from DROID, Bridge, and RT-1 with synthetic data generated via the LIBERO platform. This mixture ensures diverse interaction scenarios ranging from articulated object manipulation to pick-and-place tasks.
-
Key Details for Each Subset
- Real-World Data: Sourced from DROID, Bridge, and RT-1, these videos are processed using the ST-V2 reconstruction framework to generate robust, temporally consistent 4D pointmap sequences suitable for rapid robot motions.
- Synthetic Data: Built on the MuJoCo engine within LIBERO, this subset leverages native noise-free depth parameters for absolute ground-truth precision. It includes procedurally randomized backgrounds and systematically synthesized failure cases created by injecting Gaussian noise into 6-DoF pose dimensions while keeping gripper states unperturbed.
-
Data Usage and Training Strategy The dataset serves as the foundation for training the Kinema4D model, with each episode sliced into uniform 49-frame sequences to maintain consistent motion frequencies. The authors utilize a unified validation set comprising 3,200 episodes sampled proportionally from all source domains (2,000 from DROID, 1,000 from Bridge, 100 from RT-1, and 100 from LIBERO) to ensure fair evaluation without data leakage.
-
Processing and Annotation Details
- 4D Reconstruction: The pipeline prioritizes scalability by using ST-V2 for real-world data to capture relative spatial geometry, while synthetic data uses direct depth rendering for pixel-aligned trajectories.
- Robot Segmentation: To isolate the robot as a control signal, the authors apply SAM2 with semantic prompts to segment robot areas from RGB frames and mask the corresponding pointmaps.
- Language Generation: Since original text labels were often incomplete, the team used Qwen3-VL-plus to generate two types of descriptions for each episode: complete text covering whole video dynamics and environment-centric descriptions focusing on the initial static scene.
- Curation: Manual verification prunes low-quality captures and reconstruction artifacts, while uniform temporal downsampling standardizes long demonstrations into the 49-frame format.
Method
The proposed framework, Kinema4D, operates through a two-stage pipeline designed to decouple deterministic robot motion from stochastic environmental reactions. Refer to the framework diagram for a high-level overview of the system, which takes a canonical initial world image and a robot action sequence to generate future robot-world interactions in 4D space.

The architecture is composed of two primary components: Kinematics Control and 4D Generative Modeling. As illustrated in the detailed architecture diagram, the Kinematics Control module transforms abstract robot actions into a precise 4D representation. This process begins with 3D robot asset acquisition, where factory-provided CAD meshes or a reconstruction pipeline involving orbital video capture and mesh recovery are used to establish the geometric entity. The joint anchor points from the robot's URDF model are mapped to the reconstructed mesh to enable articulation. Given an input action sequence, the system employs Inverse Kinematics (IK) for end-effector control or direct mapping for joint-space control to resolve joint configurations qt. Forward Kinematics (FK) then computes the 6-DoF poses for all links within the reconstruction space. Finally, a spatial-visual projection maps the articulated robot trajectory onto the image plane using camera intrinsics and extrinsics, generating a 4D robot pointmap M1:T. For any point x on the surface of link k, its projected pixel coordinates (u,v) and depth z are determined by: u⋅zv⋅zz=K⋅Treconcam⋅Tk,trecon⋅x, where K is the camera intrinsic matrix. This pointmap serves as a spatiotemporal visual signal that is pixel-aligned with the RGB grid.
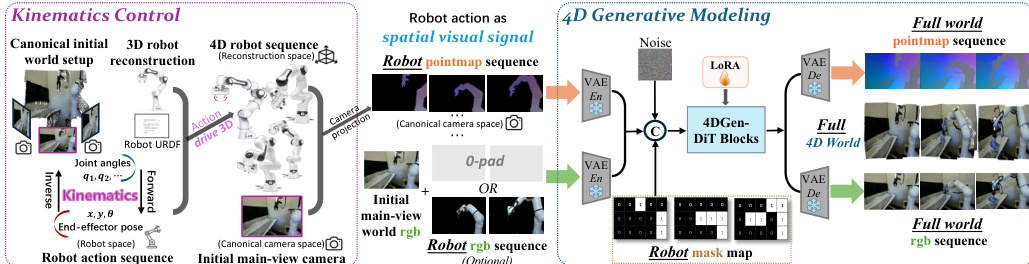
The second stage, 4D Generative Modeling, utilizes a diffusion model to synthesize the environment's reactive dynamics. The initial main-view world image and the robot pointmap sequence are aligned temporally and concatenated. This unified signal is processed by a shared VAE encoder to obtain input latents. To enforce pixel-level control, a guided mask is introduced, indicating spatial occupancy of the robot versus areas to be generated. The core backbone is a Diffusion Transformer (DiT) that predicts synchronized RGB and pointmap sequences. To preserve pixel-wise alignment, the model adopts shared Rotary Positional Encoding (RoPE) across both modalities, while learnable domain embeddings distinguish between them. The diffusion process learns to generate this latent sequence by optimizing a conditional denoising objective: Lvid=Ez0,ϵ,τ,c[∥ϵ−ϵθ(zτ,τ,c)∥2], where zτ is the noisy latent at diffusion step τ. The denoising process is guided by the robot pointmap as geometric anchors. Finally, the denoised latents are reconstructed by the shared VAE Decoder to produce the full-world pointmap and RGB sequences, resulting in a 4D world where every pixel's depth and motion are grounded in 3D space.
Experiment
- Main generation experiments validate that the proposed framework achieves superior 4D geometric fidelity and temporal consistency compared to state-of-the-art 2D and 4D baselines, particularly in accurately simulating complex physical interactions like near-miss failures where 2D methods fail.
- Policy evaluation experiments demonstrate the framework's utility as a high-fidelity simulator by successfully predicting robotic task outcomes in both noise-free simulation and rigorous zero-shot real-world scenarios without fine-tuning.
- Ablation studies confirm that using robot pointmaps as the primary control signal is essential for precise spatial reasoning, while the model remains robust to input noise and benefits from embodiment-agnostic training across diverse datasets.
- Comparative analysis reveals that relying on text instructions or depth maps alone leads to significant performance degradation, whereas the proposed 4D-aware approach ensures physically plausible transitions and strong cross-domain generalization despite higher computational costs.