Command Palette
Search for a command to run...
MiroThinker-1.7 & H1 : Vers des agents de recherche de haute performance par la vérification
MiroThinker-1.7 & H1 : Vers des agents de recherche de haute performance par la vérification
Résumé
Nous présentons MiroThinker-1.7, un nouvel agent de recherche conçu pour des tâches de raisonnement complexes à horizon étendu. Sur cette base, nous introduisons MiroThinker-H1, qui étend les capacités de l'agent avec des fonctionnalités de raisonnement intensif pour une résolution de problèmes multi-étapes plus fiable. En particulier, MiroThinker-1.7 améliore la fiabilité de chaque étape d'interaction grâce à une phase de mid-training centrée sur l'agent, mettant l'accent sur la planification structurée, le raisonnement contextuel et l'interaction avec les outils. Cela permet des interactions multi-étapes plus efficaces et un raisonnement soutenu sur des tâches complexes. MiroThinker-H1 intègre en outre une vérification directement dans le processus de raisonnement, tant au niveau local que global. Les décisions de raisonnement intermédiaires peuvent être évaluées et affinées durant l'inférence, tandis que la trajectoire globale de raisonnement est auditée afin de garantir que les réponses finales s'appuient sur des chaînes de preuves cohérentes. Sur des benchmarks couvrant la recherche sur le web ouvert, le raisonnement scientifique et l'analyse financière, MiroThinker-H1 atteint des performances de pointe sur les tâches de recherche approfondie tout en maintenant des résultats solides dans des domaines spécialisés. Nous publions également MiroThinker-1.7 et MiroThinker-1.7-mini en tant que modèles open-source, offrant des capacités compétitives pour les agents de recherche avec une efficacité nettement améliorée.
One-sentence Summary
The MiroMind Team introduces MiroThinker-1.7 and MiroThinker-H1, research agents that prioritize effective interaction scaling over trajectory length through agentic mid-training and a novel verification-centric reasoning mode. These models achieve state-of-the-art performance in complex deep research, scientific, and financial analysis by auditing intermediate steps and global evidence chains to ensure reliable long-horizon problem solving.
Key Contributions
- The paper introduces MiroThinker-1.7, a research agent that improves step-level reliability through an agentic mid-training stage emphasizing structured planning, contextual reasoning, and tool interaction. This approach enables more effective multi-step problem solving and reduces the number of reasoning turns required for complex tasks.
- A heavy-duty reasoning mode called MiroThinker-H1 is presented, which integrates verification mechanisms at both local and global levels to evaluate intermediate decisions and audit the overall reasoning trajectory. This design allows the system to refine actions during inference and ensure final answers are supported by coherent chains of evidence.
- The work releases MiroThinker-1.7 and MiroThinker-1.7-mini as open-source models that achieve state-of-the-art performance on deep research benchmarks while maintaining high efficiency. Experimental results across open-web research, scientific reasoning, and financial analysis demonstrate that these models outperform existing open-source and commercial research agents.
Introduction
Real-world tasks like scientific analysis and financial research demand AI systems that can execute long chains of reasoning while gathering and verifying external information. Current agentic frameworks often fail because simply extending the number of interaction steps tends to accumulate errors and degrade solution quality rather than improve reliability. The authors address this by introducing MiroThinker-1.7 and MiroThinker-H1, which prioritize effective interaction scaling through a specialized mid-training stage that strengthens atomic planning and tool-use skills. They further enhance reliability with a heavy-duty verification mode that audits reasoning steps locally and globally to ensure final answers are supported by coherent evidence chains.
Dataset
- The authors construct the dataset using a corpus-based pipeline that draws from highly interlinked sources such as Wikipedia and OpenAlex while preserving hyperlink topology.
- For each seed document, the process samples a connected subgraph via internal hyperlinks, extracts cross-document factual statements, and prompts a strong large language model to synthesize multi-hop question-answer pairs.
- This approach generates data with high throughput and broad coverage, utilizing prompt-driven diversification and obfuscation to induce varied question forms and reasoning patterns.
- The dataset lacks explicit difficulty control or structural enforcement of reasoning depth, and information leakage is not systematically managed during the generation process.
Method
The authors design MiroThinker-1.7 around an iterative agent-environment interaction loop. The framework extends the ReAct paradigm with a dual-loop structure consisting of an outer episode loop and an inner step loop. Within an episode e, the agent accumulates a trajectory log Ht(e) containing thoughts, actions, and observations. To manage context within a fixed token budget, a context operator Φt applies sliding-window filtering and result truncation. Specifically, the agent retains the K most recent steps while masking older observations, ensuring the effective context Ct(e) remains manageable. If an episode exhausts its turn budget without a valid answer, the system triggers an episode restart, discarding prior state to avoid bias.
The framework integrates a modular tool interface to connect the agent to the external world. As shown in the figure below:
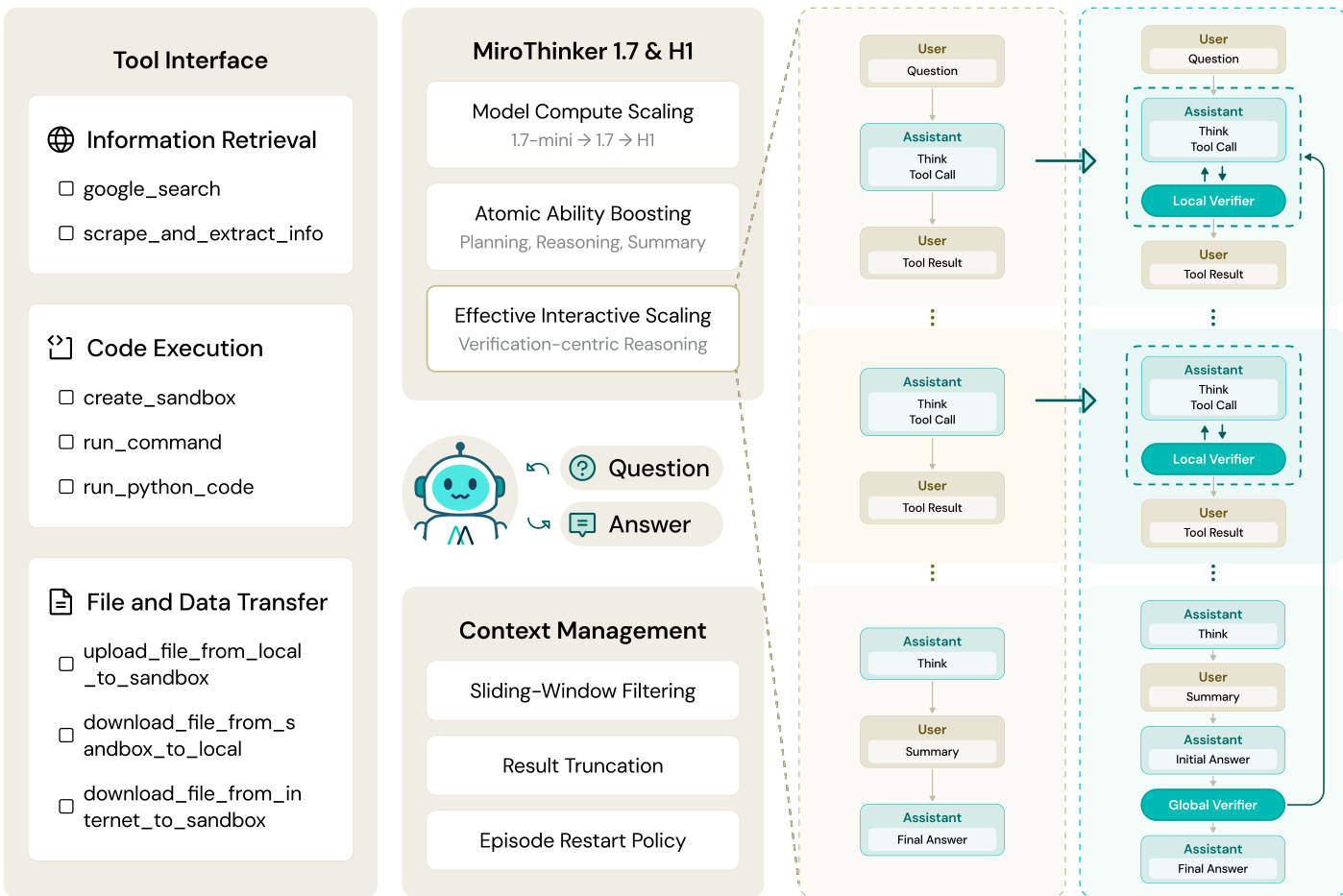 This interface encompasses Information Retrieval (search and scraping), Code Execution (sandboxed Python and shell commands), and File Transfer utilities. For the MiroThinker-H1 variant, the architecture incorporates a verification-centric reasoning scheme featuring Local and Global Verifiers to audit step-level and complete reasoning processes respectively.
This interface encompasses Information Retrieval (search and scraping), Code Execution (sandboxed Python and shell commands), and File Transfer utilities. For the MiroThinker-H1 variant, the architecture incorporates a verification-centric reasoning scheme featuring Local and Global Verifiers to audit step-level and complete reasoning processes respectively.
To support training, the authors employ a dual-pipeline QA synthesis framework. The Corpus-based Pipeline focuses on topical breadth by sampling subgraphs from curated corpora to generate high-volume QA pairs. In parallel, the WebHop Pipeline constructs calibrated reasoning trees using web-augmented expansion and hierarchical verification. This pipeline ensures reasoning rigour by expanding root entities via live web search and applying adaptive leaf obfuscation to prevent answer leakage.
The data synthesis process is illustrated in the figure below:
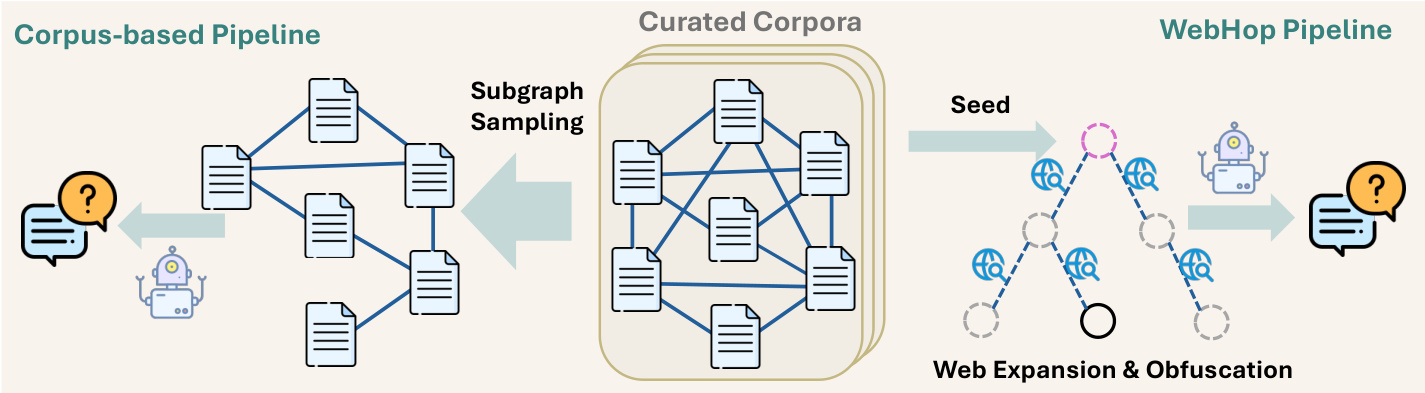 This approach allows the model to learn from both structured knowledge graphs and diverse, real-world web content.
This approach allows the model to learn from both structured knowledge graphs and diverse, real-world web content.
The training process follows a four-stage pipeline designed to progressively enhance agentic capabilities. First, Mid-Training strengthens atomic agentic capabilities such as planning, reasoning, and tool use through a large corpus of agentic supervision. Second, Supervised Fine-Tuning allows the model to learn structured agentic interaction behaviors by replicating expert trajectories. Third, Preference Optimization aligns the model's decisions with task objectives and behavior preferences. Finally, Reinforcement Learning promotes creative exploration and improves generalization in real-world environments using Group Relative Policy Optimization (GRPO).
The progression of these training stages is depicted in the figure below:
 During Reinforcement Learning, the authors implement a targeted entropy control mechanism to maintain policy stability and prevent premature entropy collapse during the optimization process.
During Reinforcement Learning, the authors implement a targeted entropy control mechanism to maintain policy stability and prevent premature entropy collapse during the optimization process.
Experiment
- Agentic benchmarks validate that MiroThinker achieves state-of-the-art performance in multi-step web browsing, information retrieval, and reasoning, surpassing leading commercial models on tasks like Humanity's Last Exam and GAIA.
- Professional-domain evaluations confirm robust capabilities in specialized fields, with the model outperforming frontier systems in scientific reasoning, financial analysis, and medical synthesis.
- Long-form report assessments demonstrate superior report quality and factual grounding, proving the model's effectiveness in synthesizing complex information for deep research queries.
- Interaction scaling experiments reveal that improving the quality of individual reasoning steps yields better results than simply increasing the number of interaction turns, leading to higher performance with fewer steps.
- Verification-centric ablation studies show that local and global verifiers significantly enhance performance on hard subsets and search-intensive tasks by correcting erroneous reasoning paths and reducing redundant interactions.