Command Palette
Search for a command to run...
Attention de type mélange de profondeurs
Attention de type mélange de profondeurs
Résumé
L'augmentation de la profondeur constitue un moteur essentiel pour les grands modèles de langage (LLM). Pourtant, à mesure que les LLMs s'approfondissent, ils souffrent souvent d'une dégradation du signal : les caractéristiques informatives formées dans les couches peu profondes sont progressivement diluées par des mises à jour résiduelles répétées, ce qui les rend plus difficiles à récupérer dans les couches plus profondes. Nous introduisons l'attention par mélange de profondeurs (MoDA), un mécanisme permettant à chaque tête d'attention de porter son attention sur les paires KV de la séquence au niveau de la couche courante ainsi que sur les paires KV issues des couches précédentes. Nous décrivons également un algorithme économe en ressources matérielles pour MoDA, qui résout les motifs d'accès mémoire non contigus, atteignant 97,3 % de l'efficacité de FlashAttention-2 pour une longueur de séquence de 64K. Des expériences menées sur des modèles de 1,5 milliard de paramètres démontrent que MoDA surpasse systématiquement des baselines solides. Notamment, il améliore la perplexité moyenne de 0,2 sur 10 benchmarks de validation et accroît la performance moyenne de 2,11 % sur 10 tâches en aval, avec une surcharge de calcul négligeable de 3,7 % en termes de FLOPs. Nous constatons également que la combinaison de MoDA avec une normalisation postérieure (post-norm) produit de meilleures performances que son utilisation avec une normalisation préalable (pre-norm). Ces résultats suggèrent que MoDA est une primitive prometteuse pour le scaling de la profondeur. Le code est disponible à l'adresse suivante : https://github.com/hustvl/MoDA.
One-sentence Summary
Researchers from Huazhong University of Science & Technology and ByteDance propose Mixture-of-Depths Attention (MoDA), a hardware-efficient mechanism that mitigates information dilution in deep large language models by enabling dynamic cross-layer retrieval, thereby improving downstream performance with minimal computational overhead.
Key Contributions
- The paper introduces mixture-of-depths attention (MoDA), a unified mechanism that enables each attention head to dynamically attend to both current sequence key-value pairs and depth key-value pairs from preceding layers to mitigate information dilution.
- A hardware-efficient fused algorithm is presented that resolves non-contiguous memory access patterns through chunk-aware layouts and group-aware indexing, achieving 97.3% of FlashAttention-2 efficiency at a 64K sequence length.
- Extensive experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms the OLMo2 baseline, improving average perplexity by 0.2 across 10 validation benchmarks and increasing downstream task performance by 2.11% with only 3.7% additional FLOPs.
Introduction
Scaling the depth of large language models is critical for enhancing representational capacity, yet deeper networks often suffer from information dilution where valuable features from shallow layers degrade as they pass through repeated residual updates. Prior attempts to fix this using dense cross-layer connections preserve history but introduce prohibitive parameter growth, while standard residual pathways fail to prevent signal loss without adding significant overhead. The authors introduce Mixture-of-Depths Attention (MoDA), a mechanism that allows each attention head to dynamically retrieve key-value pairs from both the current sequence and preceding layers to recover lost information. They further develop a hardware-efficient fused algorithm that resolves non-contiguous memory access patterns, achieving 97.3% of FlashAttention-2 efficiency at 64K sequence length while delivering consistent performance gains with negligible computational cost.
Method
The authors propose a novel framework for stacking Transformer blocks along the depth stream, conceptualizing each block as a three-step procedure: read, operate, and write. This perspective allows for a systematic exploration of mechanisms that propagate information through depth, moving beyond standard residual connections.
Depth-Stream Mechanisms
The authors first establish a design space by comparing existing and intermediate mechanisms. Standard Depth Residual connections use an identity read and an additive write, which can lead to signal degradation due to repeated superposition. Depth Dense methods mitigate this by concatenating historical representations, though this incurs high computational costs. To balance efficiency and adaptivity, the authors introduce Depth Attention, which reads historical depth information using attention in a data-dependent manner.
The progression of these mechanisms is illustrated in the conceptual comparison of depth-stream designs.
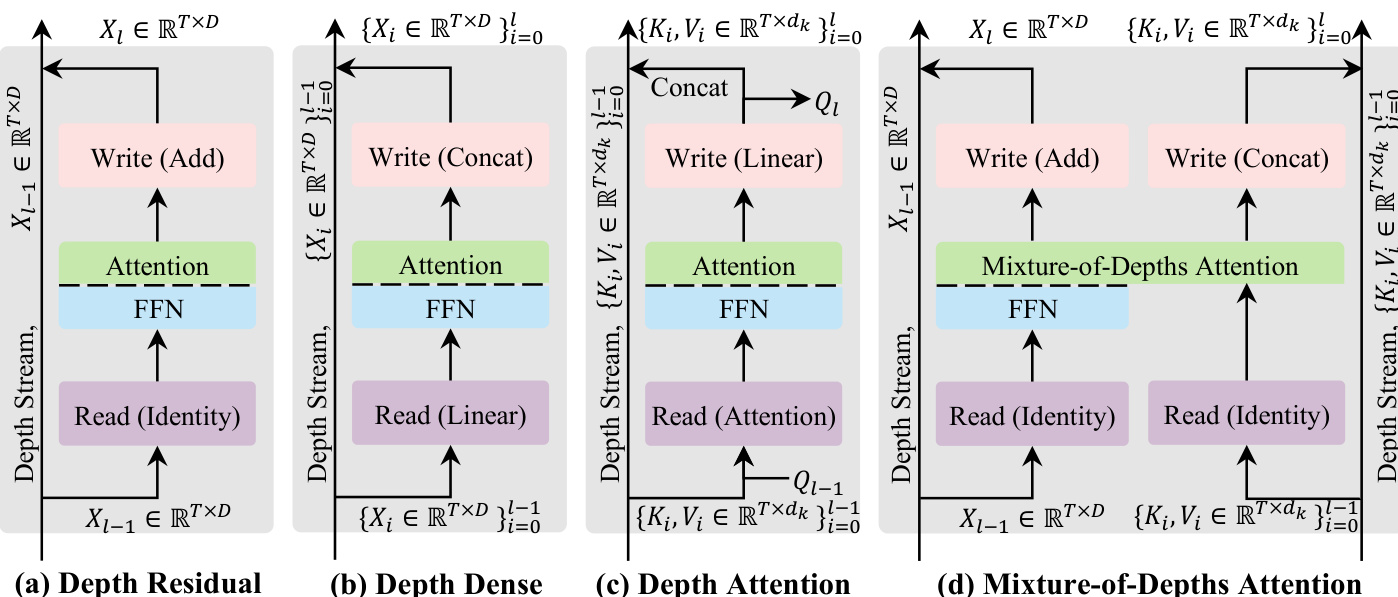
In the Depth Attention formulation, the input to layer l is computed by attending to historical key-value pairs {Ki,Vi}i=0l−1 from the same token position across layers. The output is then projected to new query, key, and value pairs for the next layer.
Mixture-of-Depths Attention (MoDA)
Building upon Depth Attention, the authors propose Mixture-of-Depths Attention (MoDA), which unifies sequence-level and depth-level retrieval into a single softmax operator. MoDA reads the current hidden state Xl−1 and the historical depth key-value stream {(Ki,Vi)}i=0l−1. During the operate step, each token attends to both the sequence-level keys and values and its own historical depth-wise keys and values, with all attention scores normalized jointly.
The architecture of the Transformer Decoder incorporating MoDA and the resulting visible relationships of the attention mechanism are shown below.
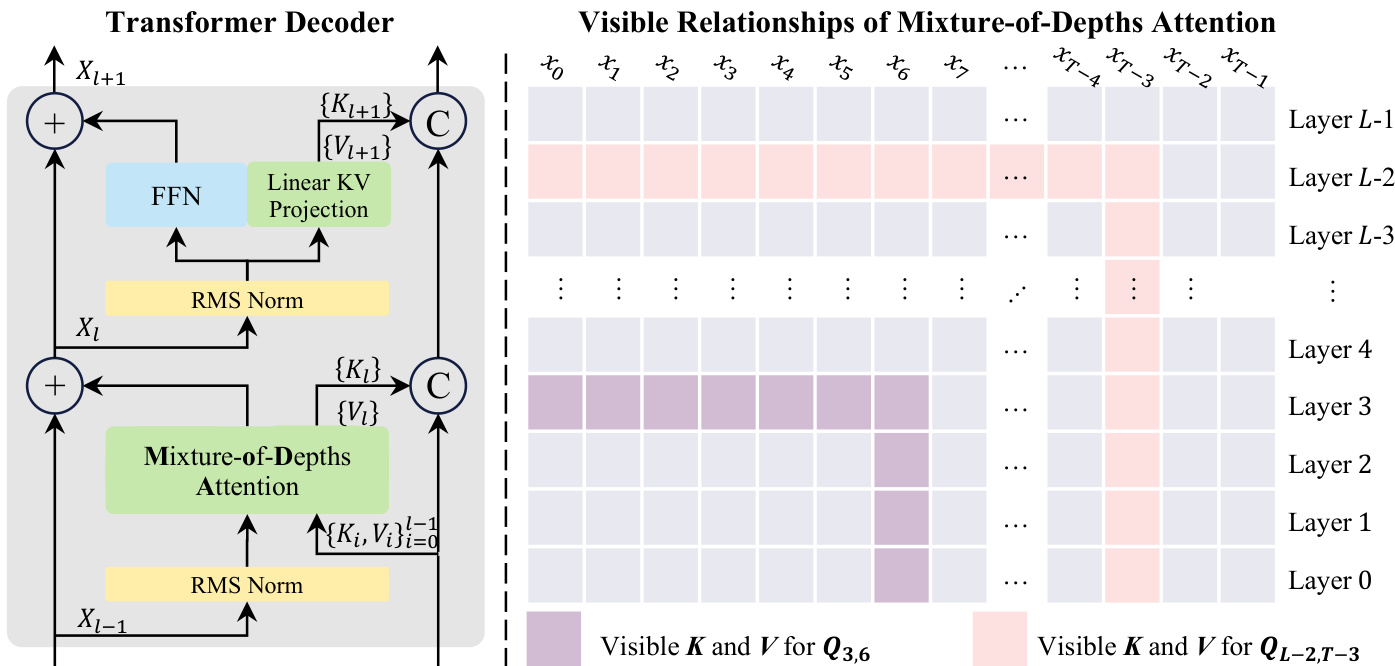
At the write step, the current layer's key-value pair is appended to the depth stream for subsequent layers. For the Feed-Forward Network (FFN) layer, a lightweight KV projection is used to generate the corresponding key-value pair. This design allows MoDA to exploit depth history efficiently with substantially lower overhead than dense cross-layer connectivity.
Hardware-Efficient Implementation
To address the memory and bandwidth bottlenecks associated with caching all depth key-value states, the authors develop a hardware-aware implementation. A naive implementation would require non-contiguous reads, degrading GPU utilization. The proposed solution reorganizes depth-stream tensors to enable contiguous memory access and fused computation.
The hardware view of MoDA depth-cache access demonstrates two key layout strategies: Flash-Compatible and Chunk/Group-Aware.

The Flash-Compatible layout flattens the depth cache along a single axis of length T×L, allowing each query to map to a contiguous depth range. However, to further improve depth utilization, the Chunk/Group-Aware layout groups queries by chunk size C. This reduces the effective depth span from T×L to (C×L)/G per chunk, where G is the Group Query Attention (GQA) group number. This reorganization minimizes unnecessary HBM traffic from masked, out-of-range depth entries and aligns query-block boundaries with G to simplify vectorized execution. The implementation follows an online softmax update process, accumulating logits from sequence and depth blocks into a single on-chip state before normalizing.
Experiment
- Efficiency comparisons demonstrate that the proposed MoDA implementation scales predictably, with overhead becoming negligible as sequence length increases or depth utilization rises, while maintaining linear scaling behavior in long-sequence regimes.
- Variant analysis on large language models reveals that injecting depth key-value information significantly improves performance with minimal computational cost, and adding depth projections specifically for FFN layers yields the best accuracy-efficiency trade-off compared to reusing attention projections.
- Scaling experiments confirm that MoDA delivers stable performance gains across different model sizes (700M to 1.5B) and diverse downstream tasks, including commonsense reasoning and broad knowledge benchmarks, while consistently lowering validation perplexity across multiple data domains.
- Layer-number studies indicate that MoDA remains effective in both shallower and deeper model configurations, with depth key-value injection consistently reducing validation loss and providing greater benefits in post-norm settings for deeper stacks.
- Attention visualizations show that the model actively retrieves cross-layer depth information rather than relying solely on sequence context, redistributing attention mass away from typical attention sinks toward more task-relevant sequence and depth locations.
- Kernel implementation ablations validate that combining flash-compatible layouts, chunk-aware designs, and group-aware indexing achieves massive speedups over naive baselines, reducing runtime by over three orders of magnitude.