Command Palette
Search for a command to run...
Regarder avant d'agir : amélioration des représentations de fondation visuelles pour les modèles vision-langage-action
Regarder avant d'agir : amélioration des représentations de fondation visuelles pour les modèles vision-langage-action
Résumé
Les modèles Vision-Language-Action (VLA) sont récemment apparus comme un paradigme prometteur pour la manipulation robotique, où la fiabilité de la prédiction d'action dépend crucialement d'une interprétation et d'une intégration précises des observations visuelles conditionnées par des instructions linguistiques. Bien que des travaux récents aient cherché à renforcer les capacités visuelles des modèles VLA, la plupart des approches traitent le socle LLM comme une boîte noire, offrant ainsi une compréhension limitée de la manière dont les informations visuelles sont ancrées dans la génération d'actions. Par conséquent, nous menons une analyse systématique de plusieurs modèles VLA couvrant différents paradigmes de génération d'actions et observons que la sensibilité aux tokens visuels diminue progressivement dans les couches profondes lors de la génération d'actions. Forts de cette observation, nous proposons DeepVision-VLA, construit sur un cadre Vision-Language Mixture-of-Transformers (VL-MoT). Ce cadre permet une attention partagée entre le modèle fondation visuel et le socle VLA, en injectant des caractéristiques visuelles multi-niveaux issues de l'expert visuel dans les couches profondes du socle VLA afin d'améliorer les représentations visuelles pour des manipulations précises et complexes. De plus, nous introduisons l'élagage visuel guidé par l'action (Action-Guided Visual Pruning, AGVP), qui exploite l'attention des couches superficielles pour éliminer les tokens visuels non pertinents tout en préservant ceux liés à la tâche, renforçant ainsi les indices visuels critiques pour la manipulation avec une surcharge computationnelle minimale. DeepVision-VLA surpasse les méthodes de l'état de l'antérieures de 9,0 % et 7,5 % respectivement sur des tâches simulées et réelles, offrant de nouvelles perspectives pour la conception de modèles VLA améliorés visuellement.
One-sentence Summary
Researchers from Peking University, Simplexity Robotics, and The Chinese University of Hong Kong propose DeepVision-VLA, a Vision-Language Mixture-of-Transformers framework that injects multi-level visual features into deeper layers and employs Action-Guided Visual Pruning to significantly outperform prior methods in complex robotic manipulation tasks.
Key Contributions
- The paper introduces DeepVision-VLA, a framework built on a Vision-Language Mixture-of-Transformers architecture that injects multi-level visual features from a dedicated vision expert into deeper layers of the VLA backbone to counteract the progressive loss of visual sensitivity during action generation.
- An Action-Guided Visual Pruning strategy is presented to refine information flow by leveraging shallow-layer attention to identify and preserve task-relevant visual tokens while removing irrelevant background data with minimal computational overhead.
- Experimental results demonstrate that the proposed method outperforms prior state-of-the-art approaches by 9.0% on simulated tasks and 7.5% on real-world manipulation benchmarks, validating the effectiveness of enhanced visual grounding in complex robotic control.
Introduction
Vision-Language-Action (VLA) models are critical for robotic manipulation as they translate visual observations and language instructions into precise physical actions. However, prior approaches often treat the underlying Large Language Model backbone as a black box, failing to address a key limitation where the model's sensitivity to task-relevant visual tokens progressively degrades in deeper layers. To solve this, the authors introduce DeepVision-VLA, which leverages a Vision-Language Mixture-of-Transformers framework to inject multi-level visual features from a dedicated vision expert directly into the deeper layers of the VLA backbone. They further enhance this architecture with Action-Guided Visual Pruning, a technique that filters irrelevant visual tokens using shallow-layer attention to ensure only critical cues influence action generation.
Method
The authors build upon the QwenVLA-OFT baseline, which utilizes a visual encoder (SigLIP2-Large) and an LLM backbone (Qwen3-VL) to map observations and instructions to actions. However, standard VLA models often suffer from sensitivity attenuation in deep layers, where visual grounding becomes diffuse and less effective for precise manipulation. To address this, the authors propose the DeepVision-VLA framework, which enhances visual grounding by injecting multi-level knowledge from a Vision Expert into the deep layers of the VLA.
Refer to the framework diagram for a high-level comparison of the vanilla architecture against the proposed DeepVision-VLA. While the vanilla model relies solely on the LLM backbone, the proposed method introduces a Vision Expert branch that processes high-resolution inputs to capture fine-grained spatial details. This design aims to counteract the loss of visual sensitivity in deeper network layers.
The detailed architecture is depicted in the figure below. The model consists of a Vision Expert branch (using DINOv3) and the standard LLM Backbone. The Vision Expert is connected only to the deepest n layers of the VLA, where visual grounding is typically weakest. To integrate these features, the authors employ a Vision-Language Mixture-of-Transformers (VL-MoT) design. Instead of simple concatenation, the intermediate Query, Key, and Value (QKV) representations from the Vision Expert are exposed and integrated with the corresponding QKV of the deep VLA layers via a shared-attention mechanism.
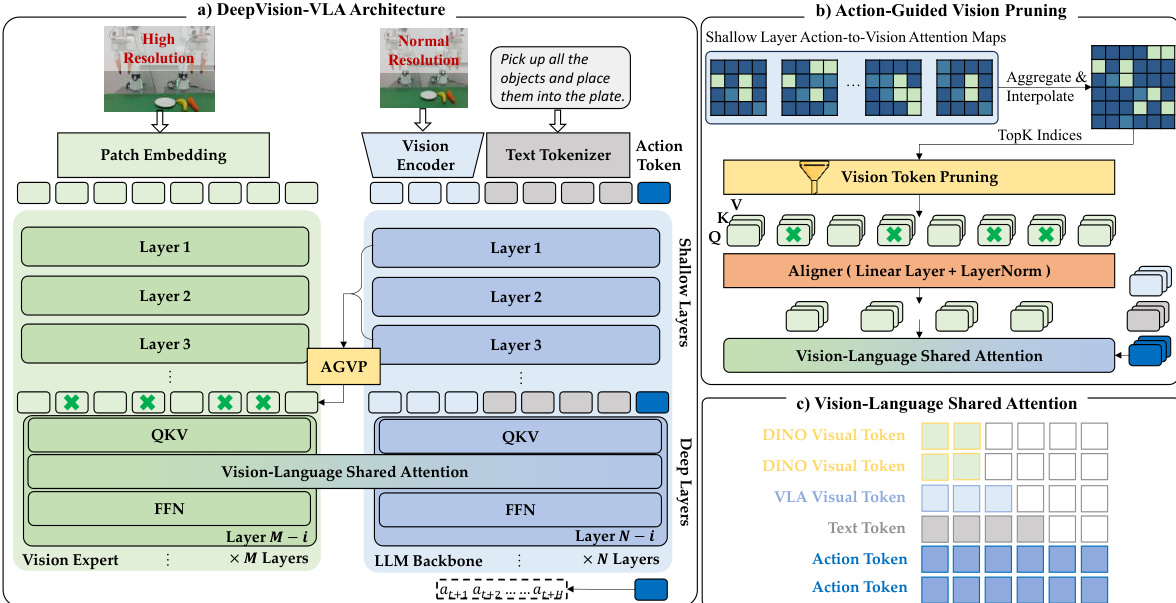
To ensure the model focuses on task-relevant regions, the authors introduce Action-Guided Vision Pruning (AGVP). This strategy leverages attention maps from the shallow layers of the VLA, where visual grounding is most reliable, to identify Regions of Interest (ROIs). These attention cues are aggregated over shallow layers and interpolated to match the Vision Expert's resolution. The model then retains only the top-K most relevant visual tokens, effectively filtering out redundant background features before they are integrated into the deep layers.
The integration of these pruned visual tokens is handled via the Vision-Language Shared Attention mechanism. In this module, the QKV projections from both the Vision Expert and the LLM backbone are concatenated. The attention is computed over this combined set, enabling cross-branch information exchange while preserving separate processing pathways. This allows the deep layers to access high-level, object-centric representations from the Vision Expert, significantly enhancing action prediction precision. The model is trained end-to-end on a large-scale cross-embodiment dataset, and during inference, the pipeline remains fully executable without additional external supervision.
Experiment
- Layer-wise analysis of existing VLA models reveals that while shallow layers effectively ground actions in task-relevant visual regions, deeper layers increasingly rely on diffuse and less relevant features, leading to reduced action reliability.
- Simulation experiments demonstrate that the proposed DeepVision-VLA significantly outperforms multiple baselines across diverse manipulation tasks by integrating a Vision-Language Mixture-of-Transformers framework and an Action-Guided Visual Pruning strategy.
- Ablation studies confirm that coupling a high-resolution Vision Expert with deeper LLM layers and utilizing action-to-vision attention for token pruning are critical for maintaining strong visual grounding and achieving superior performance.
- Real-world evaluations on complex single-arm tasks show that the model achieves high success rates in precise manipulation scenarios, such as writing and pouring, where it maintains stability and accuracy even in multi-stage sequences.
- Generalization tests under unseen backgrounds and varying lighting conditions indicate that the model effectively decouples task-relevant objects from environmental noise and maintains robust performance where baseline methods fail.