Command Palette
Search for a command to run...
HSImul3R : Reconstruction en boucle fermée intégrant la physique pour des interactions humain-scène prêtes à la simulation
HSImul3R : Reconstruction en boucle fermée intégrant la physique pour des interactions humain-scène prêtes à la simulation
Yukang Cao Haozhe Xie Fangzhou Hong Long Zhuo Zhaoxi Chen Liang Pan Ziwei Liu
Résumé
Nous présentons HSImul3R, un cadre unifié pour la reconstruction 3D prête à la simulation des interactions humain-scène (HSI) à partir de captures informelles, incluant des images à vues éparses et des vidéos monoculaires. Les méthodes existantes souffrent d'un écart perception-simulation : les reconstructions visuellement plausibles violent souvent les contraintes physiques, entraînant une instabilité dans les moteurs de physique et un échec dans les applications d'IA incarnée. Pour combler cet écart, nous introduisons un pipeline d'optimisation bidirectionnelle ancré dans la physique, qui traite le simulateur physique comme un superviseur actif afin d'affiner conjointement la dynamique humaine et la géométrie de la scène. Dans le sens direct, nous employons un apprentissage par renforcement ciblé sur la scène (Scene-targeted Reinforcement Learning) pour optimiser le mouvement humain sous une double supervision de la fidélité du mouvement et de la stabilité du contact. Dans le sens inverse, nous proposons l'optimisation directe de la récompense de simulation (Direct Simulation Reward Optimization), qui exploite les retours de simulation sur la stabilité gravitationnelle et le succès des interactions pour affiner la géométrie de la scène. Nous présentons également HSIBench, un nouveau benchmark comprenant des objets divers et des scénarios d'interaction variés. Des expériences approfondies démontrent que HSImul3R produit les premières reconstructions HSI stables et prêtes à la simulation, et peut être déployé directement sur des robots humanoïdes réels.
One-sentence Summary
Researchers from Nanyang Technological University, ACE Robotics, and Shanghai AI Laboratory propose HSImul3R, a unified framework that bridges the perception-simulation gap by using a bi-directional optimization pipeline to refine human motion and scene geometry for stable, simulation-ready human-scene interaction reconstruction from casual captures.
Key Contributions
- The paper introduces HSImul3R, a unified framework that bridges the perception-simulation gap by employing a physically-grounded bi-directional optimization pipeline where a physics simulator acts as an active supervisor to jointly refine human dynamics and scene geometry.
- The method implements Scene-targeted Reinforcement Learning for forward motion optimization and Direct Simulation Reward Optimization for reverse geometry refinement, leveraging simulation feedback on gravitational stability and contact constraints to ensure physical validity.
- This work presents HSIBench, a new benchmark dataset containing diverse objects and interaction scenarios, and demonstrates through extensive experiments that the approach produces the first stable, simulation-ready reconstructions capable of direct deployment on real-world humanoid robots.
Introduction
Embodied AI requires physically valid human-scene interaction data to bridge the gap between visual observation and real-world robotic deployment. Prior methods often produce visually plausible reconstructions that fail in physics engines because they treat human motion and scene geometry as separate problems or optimize solely for 2D image alignment. The authors introduce HSImul3R, a unified framework that uses a physics simulator as an active supervisor to jointly refine human dynamics and scene geometry through a bi-directional optimization pipeline. This approach leverages scene-targeted reinforcement learning to stabilize human motion and direct simulation reward optimization to correct scene geometry, resulting in the first stable, simulation-ready reconstructions that can be directly deployed on humanoid robots.
Method
The proposed method, HSImul3R, reconstructs simulation-ready human-scene interactions from casual captures through a bi-directional optimization pipeline. As shown in the figure below, the framework integrates a forward-pass for motion refinement and a reverse-pass for object geometry correction.
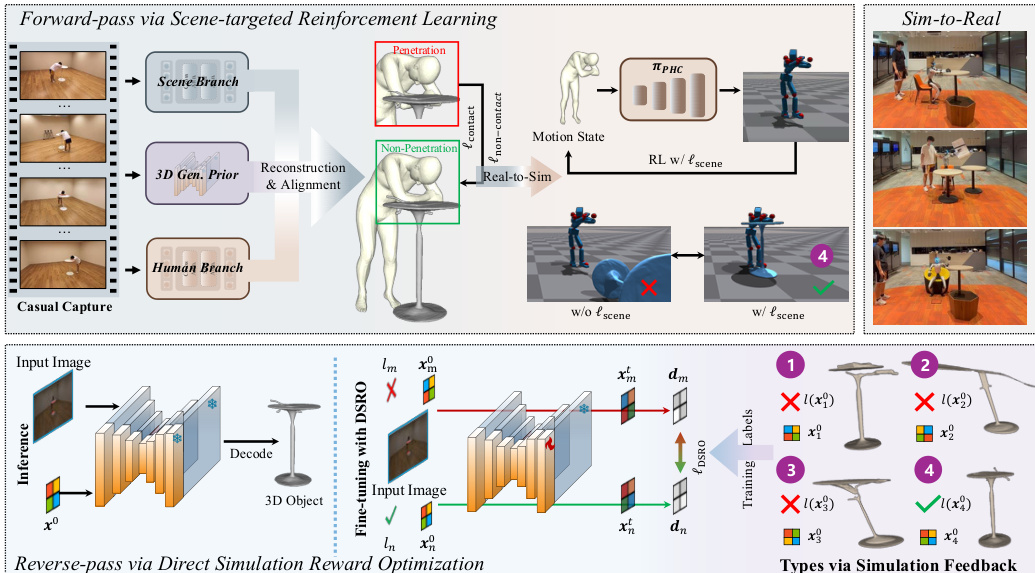
The process begins with the independent reconstruction of static scene geometry and dynamic human motion. The authors utilize DUSt3R for scene structure recovery and employ tools like SAM2, 4DHumans, and ViTPose for human motion estimation. To address the lack of 3D geometric awareness in standard alignment methods, they introduce an explicit 3D structural prior derived from image-to-3D generative models. This step refines the scene geometry and enforces robust interaction constraints. Specifically, the authors optimize the position of the recovered human and generated objects using distinct loss functions for contact and non-contact scenarios. For non-contact cases, the loss minimizes the distance between the closest human body part and object vertices. For contact cases, the loss penalizes penetration depth using a signed distance function.
Following the initial reconstruction, the method employs a forward-pass optimization to ensure stable dynamics. This stage uses a scene-targeted reinforcement learning scheme. The authors introduce a supervision signal that enforces spatial proximity between the humanoid and scene objects, encouraging physically plausible contact. This is achieved by minimizing a loss function ℓscene, defined as:
ℓscene=Ncontact⋅Nsurf1⋅i=1∑Ncontacti=1∑Nsurf∥μio−kjh∥22where Ncontact is the number of contacts between the human and scene objects, and Nsurf denotes the number of sampled object surface points within the local contact region.
To further rectify structural correctness, a reverse-pass optimization is introduced. This process leverages simulator feedback regarding physical stability to refine the 3D object generation. The authors propose Direct Simulation Reward Optimization (DSRO), which uses the outcome of the simulation as a supervision signal. The DSRO objective incorporates a stability label l(x0), which is determined by whether the object remains upright under gravity and achieves a stable final state during interaction. The stability is defined as:
l(x0)={1,0,if stableotherwiseThis allows the system to fine-tune the generated objects to eliminate artifacts like missing legs or surface distortions that would otherwise cause simulation failure.
Experiment
- Reconstruction and simulation experiments demonstrate that the proposed method significantly outperforms existing baselines and variants by achieving stable human-scene interactions, minimizing physical penetration, and preserving meaningful contact states.
- Qualitative comparisons reveal that the approach generates geometrically accurate object structures with fewer distortions, effectively preventing the unintended object displacement and interaction failures observed in baseline methods.
- Ablation studies confirm that the scene-targeted simulation loss and the DSRO fine-tuning strategy are critical for maintaining interaction stability and preventing exaggerated motions that lead to object displacement.
- Real-world deployment on Unitree G1 humanoid robots validates that the refined motions can be successfully transferred to physical hardware to execute complex interaction scenarios.
- Analysis of input views indicates that while additional views slightly improve motion quality, they have minimal impact on simulation stability or penetration handling.