Command Palette
Search for a command to run...
daVinci-Env : Synthèse d'environnements SWE ouverts à grande échelle
daVinci-Env : Synthèse d'environnements SWE ouverts à grande échelle
Résumé
La formation d'agents d'ingénierie logicielle (SWE) performants exige des environnements à grande échelle, exécutables et vérifiables, capables de fournir des boucles de rétroaction dynamiques pour l'édition itérative du code, l'exécution de tests et le raffinement des solutions. Toutefois, les jeux de données open source existants restent limités tant en termes d'échelle que de diversité des dépôts, tandis que les solutions industrielles demeurent opaques en raison de leurs infrastructures non divulguées, créant ainsi une barrière prohibitive pour la majorité des groupes de recherche académiques.Nous présentons OpenSWE, le cadre entièrement transparent le plus vaste dédié à la formation d'agents SWE en Python. Il intègre 45 320 environnements Docker exécutables répartis sur plus de 12 800 dépôts, avec l'ensemble des Dockerfiles, des scripts d'évaluation et de l'infrastructure rendus publics pour assurer la reproductibilité. OpenSWE a été construit grâce à une pipeline de synthèse multi-agents déployée sur un cluster distribué de 64 nœuds, automatisant l'exploration des dépôts, la construction des Dockerfiles, la génération de scripts d'évaluation et l'analyse itérative des tests.Au-delà de l'échelle, nous proposons une pipeline de filtrage centrée sur la qualité qui caractérise la difficulté inhérente à chaque environnement, éliminant les instances soit insolubles, soit insuffisamment stimulantes, et ne conservant que celles maximisant l'efficacité de l'apprentissage. Avec un investissement de 891 000 pourlaconstructiondesenvironnementsetde576000 supplémentaires pour l'échantillonnage des trajectoires et la curation sensible à la difficulté, l'ensemble du projet représente un investissement total d'environ 1,47 million de dollars, générant environ 13 000 trajectoires curatées issues d'environ 9 000 environnements garantissant une qualité supérieure.Des expérimentations extensives valident l'efficacité d'OpenSWE : les modèles OpenSWE-32B et OpenSWE-72B atteignent respectivement 62,4 % et 66,0 % sur la tâche SWE-bench Verified, établissant ainsi l'état de l'art (SOTA) au sein de la série Qwen2.5. De plus, un entraînement spécifiquement axé sur l'ingénierie logicielle entraîne des améliorations substantielles hors domaine, notamment jusqu'à 12 points sur les benchmarks de raisonnement mathématique et 5 points sur les benchmarks scientifiques, sans dégradation de la mémorisation factuelle.
One-sentence Summary
Researchers from SII, SJTU, and GAIR introduce OpenSWE, a transparent framework featuring 45,320 executable Docker environments for training software engineering agents. By employing a multi-agent synthesis pipeline and quality-centric filtering, this approach establishes new state-of-the-art performance while enabling significant out-of-domain reasoning improvements.
Key Contributions
- OpenSWE addresses the scarcity of large-scale, transparent training environments by releasing 45,320 executable Docker instances across 12.8k repositories, complete with open-sourced Dockerfiles, evaluation scripts, and a multi-agent synthesis pipeline.
- The framework introduces a quality-centric filtering pipeline that characterizes environment difficulty to remove unsolvable or trivial instances, resulting in 13,000 curated trajectories from 9,000 high-quality environments.
- Extensive experiments demonstrate that models trained on OpenSWE achieve state-of-the-art results of 66.0% on SWE-bench Verified and exhibit log-linear scaling without saturation, while also improving out-of-domain reasoning capabilities.
Introduction
Autonomous software engineering agents require executable environments like Docker to generate dynamic feedback through code compilation and testing, yet creating these environments at scale has historically been hindered by prohibitive computational costs and a lack of transparency. Prior open-source efforts often suffer from limited repository diversity or suffer from data quality issues such as unsolvable tasks or trivial problems that fail to provide meaningful learning signals. To address these gaps, the authors introduce OpenSWE, a fully transparent framework that synthesizes over 45,000 executable environments using a multi-agent system and implements a difficulty-aware filtering pipeline to curate high-quality training trajectories. This approach not only releases the complete infrastructure and synthesis pipeline but also demonstrates that combining massive scale with strategic curation significantly boosts agent performance on benchmarks like SWE-Bench Verified.
Dataset
OpenSWE Dataset Overview
-
Dataset Composition and Sources The authors constructed OpenSWE, the largest fully transparent framework for software engineering agent training, by collecting data from GitHub via REST and GraphQL APIs. The final dataset comprises 45,320 executable Docker environments spanning over 12,800 unique Python repositories. This infrastructure was built using a multi-agent synthesis pipeline deployed across a 64-node distributed cluster to automate repository exploration, Dockerfile construction, and test generation.
-
Key Details for Each Subset
- Source Material: The raw data consists of approximately 572,114 GitHub Pull Requests (PRs) from Python repositories.
- Filtering Rules: A four-stage pipeline ensures quality by retaining only repositories with at least five stars, filtering for Python as the primary language, requiring linked issues with descriptions, and excluding PRs where changes are confined entirely to test directories.
- Quality Assurance: A test analysis agent validates each environment to ensure tests are not bypassed by hardcoded exit codes and diagnoses root causes for failures, such as dependency conflicts or unsolvable configurations.
- Final Scale: After rigorous filtering and curation, the project yielded roughly 10,000 high-quality environments and approximately 13,000 curated trajectories.
-
Model Training and Data Usage
- Trajectory Sampling: The authors used the GLM-4.7 model to sample agent trajectories from the OpenSWE and filtered SWE-rebench datasets four times per instance using OpenHands or SWE-Agent scaffolds.
- Selection Criteria: Training data includes only trajectories that successfully solved an instance in one or two of the four attempts.
- Data Cleaning: Steps containing formatting errors or "git pull" commands were masked or removed to prevent reward hacking and ensure observation quality.
- Training Configuration: Models were trained using a modified SLiME codebase with a 128k token context window, 5 epochs, and a batch size of 128, utilizing Qwen2.5-32B and Qwen2.5-72B as base models.
-
Processing and Construction Strategies
- Distributed Synthesis: To handle execution instability and resource contention, the team employed a decoupled, fault-tolerant parallelization framework using a shared filesystem message queue and systemd services for resilient process management.
- Automated Cleanup: An automated daemon aggressively prunes unused Docker resources to prevent storage and memory exhaustion from zombie containers.
- Metadata and Evaluation: The pipeline generates reproducible Docker containers with correct dependencies and validated evaluation scripts that confirm solution correctness through dynamic test execution.
- Difficulty Curation: The authors applied a quality-centric filtering process to characterize environment difficulty, removing instances that were either unsolvable or insufficiently challenging to maximize learning efficiency.
Method
The proposed system functions as an automated environment builder designed to synthesize reproducible Docker-based evaluation environments for software engineering tasks. The architecture is distributed, utilizing a master-worker paradigm to manage the construction and validation of task instances at scale.
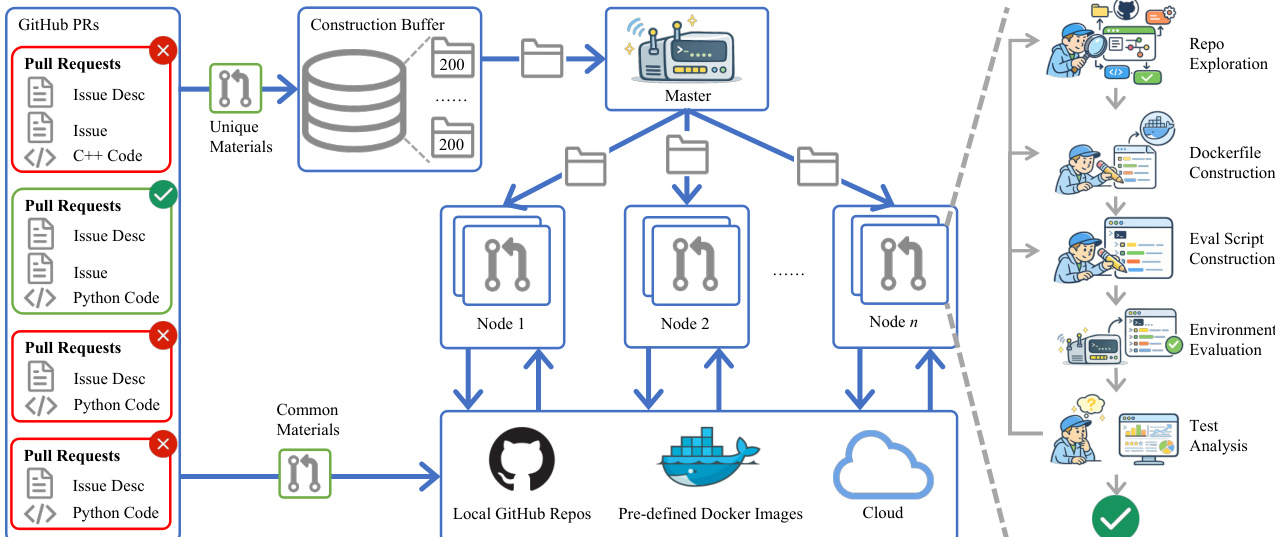
As illustrated in the framework diagram, the pipeline begins with ingesting GitHub Pull Requests and filtering them into unique and common materials. These materials are stored in a construction buffer and distributed by a Master node to multiple worker nodes. Each node executes a multi-stage agent loop comprising repository exploration, Dockerfile construction, evaluation script generation, and environment evaluation. This distributed setup allows for parallel processing of tasks while maintaining isolation through local GitHub repositories, pre-defined Docker images, and cloud resources.
The core of the system relies on a series of specialized agents that operate within an iterative feedback loop. The process initiates with a lightweight repository exploration agent. This agent bridges the gap between raw repository states and downstream environment generation. It operates through a constrained interface that allows for structural inspection, configuration file search, and extraction of setup instructions. The agent follows a cost-aware iterative policy, performing shallow, document-first inspections by default and only diving deeper when specific context is requested by downstream agents. This design minimizes redundant traversal while ensuring that critical artifacts like dependency manifests and CI workflows are identified.
Following context retrieval, the Dockerfile agent constructs the containerized environment. To address common failure modes such as network instability and redundant rebuilds, the system employs a pre-built suite of base images covering various Python versions. This strategy eliminates runtime dependency installation timeouts. Furthermore, the agent utilizes a local bare repository cache to inject codebases via COPY commands rather than cloning at build time, which removes external network dependencies and improves reproducibility. The agent is also guided by layer-aware prompting to place stable base layers early in the Dockerfile, allowing for efficient caching when dependency specifications are revised in subsequent iterations.
Concurrently, the evaluation script agent generates bash scripts to verify repair correctness. The central challenge here is precise test targeting, ensuring only relevant test cases are executed. The agent synthesizes structured bash scripts from scratch, incorporating specific test files and embedding a dedicated exit code marker to signal repair success or failure. This script is template-based to support stable iteration, separating patch injection from test command logic.
Finally, the environment evaluation module performs rule-based validation. For each iteration, the Docker image is built and the evaluation script is executed under two conditions: first with a test-only patch to verify failures on the unpatched codebase, and then with the full fix patch to verify resolution. To support this at scale, containers are bound to dedicated CPU cores and memory limits to prevent resource contention. Images are retained until the Dockerfile changes, significantly speeding up the common case where only the evaluation script is revised. If validation fails, the test analysis agent inspects the logs and provides targeted feedback to the Dockerfile or evaluation script agents to refine their outputs in the next iteration.
Experiment
- Main performance evaluation on SWE-Bench Verified validates that OpenSWE achieves state-of-the-art results at both 32B and 72B scales, demonstrating that high-quality environment data can compensate for the lack of domain-specific pretraining.
- Scaling analysis confirms a robust log-linear improvement trend where larger models benefit more from increased training data, with no performance saturation observed within the current budget.
- Environment source comparison shows that OpenSWE's synthesized environments provide a substantially stronger training signal than existing benchmarks, while mixing data sources offers complementary benefits specifically for larger models.
- General capability assessment reveals that SWE-focused training significantly enhances code generation and mathematical reasoning through improved multi-step planning, while leaving factual recall largely unaffected.