Command Palette
Search for a command to run...
ReMix : Routage par renforcement pour les mélanges de LoRAs dans le fine-tuning de LLMs
ReMix : Routage par renforcement pour les mélanges de LoRAs dans le fine-tuning de LLMs
Résumé
Les adaptateurs de faible rang (LoRA) constituent une technique de micro-ajustement économe en paramètres, consistant à injecter dans des modèles préentraînés des matrices de faible rang entraînables afin de les adapter à de nouvelles tâches. Les architectures de type « Mixture-of-LoRAs » étendent efficacement les réseaux de neurones en acheminant l'entrée de chaque couche vers un petit sous-ensemble de LoRA spécialisés dédiés à cette couche. Les routeurs existants pour les Mixture-of-LoRAs attribuent à chaque LoRA un poids d'acheminement appris, permettant ainsi un entraînement de bout en bout du routeur. Malgré leurs performances empiriques prometteuses, nous observons que, dans la pratique, ces poids d'acheminement présentent une distribution extrêmement déséquilibrée entre les LoRA : un ou deux LoRA dominent systématiquement les poids, limitant ainsi le nombre de LoRA effectivement actifs et, par conséquent, entravant sévèrement la capacité d'expression des modèles Mixture-of-LoRAs existants. Dans ce travail, nous attribuons cette faiblesse à la nature même des poids d'acheminement appris et repensons la conception fondamentale du routeur. Pour remédier à ce problème critique, nous proposons un nouveau routeur que nous nommons « Reinforcement Routing for Mixture-of-LoRAs » (ReMix). L'idée centrale de notre approche consiste à utiliser des poids d'acheminement non appris afin de garantir que tous les LoRA actifs contribuent de manière équivalente, sans qu'aucun LoRA ne domine les poids d'acheminement. Toutefois, en raison de l'absence de paramètres appris pour le routeur, celui-ci ne peut être entraîné directement par descente de gradient. Nous proposons donc un estimateur de gradient sans biais pour le routeur, en exploitant la technique « Reinforce Leave-One-Out » (RLOO), où la perte de supervision est considérée comme la récompense et le routeur comme la politique dans un cadre d'apprentissage par renforcement. Cet estimateur de gradient permet également de mettre à l'échelle les ressources de calcul dédiées à l'entraînement, améliorant ainsi les performances prédictives de notre méthode ReMix. Des expériences approfondies démontrent que le ReMix proposé surpasse significativement les méthodes de micro-ajustement économe en paramètres les plus avancées, et ce, pour un nombre comparable de paramètres activés.
One-sentence Summary
Researchers from the University of Illinois Urbana-Champaign and Meta AI propose ReMix, a novel Mixture-of-LoRAs framework that replaces learnable routing weights with non-learnable ones to prevent router collapse. By employing an unbiased gradient estimator and RLOO technique, ReMix ensures all active adapters contribute equally, significantly outperforming existing parameter-efficient finetuning methods.
Key Contributions
- Existing Mixture-of-LoRAs models suffer from routing weight collapse where learned weights often concentrate on a single adapter, effectively wasting the computation of other activated LoRAs and limiting the model's expressive power.
- The authors propose ReMix, a novel router design that enforces constant non-learnable weights across all active LoRAs to ensure equal contribution and prevent any single adapter from dominating the routing process.
- To enable training with these non-differentiable weights, the paper introduces an unbiased gradient estimator using the reinforce leave-one-out technique, which allows ReMix to significantly outperform state-of-the-art methods across diverse benchmarks under strict parameter budgets.
Introduction
Low-rank adapters (LoRAs) enable efficient fine-tuning of large language models by injecting trainable matrices into frozen weights, while Mixture-of-LoRAs architectures aim to further boost capacity by routing inputs to specialized subsets of these adapters. However, existing approaches that rely on learned routing weights suffer from a critical flaw where weights collapse to a single dominant LoRA, effectively wasting the computational resources of the other active adapters and limiting the model's expressive power. To resolve this, the authors introduce ReMix, a reinforcement routing framework that enforces equal contribution from all active LoRAs by using non-learnable constant weights and training the router via an unbiased gradient estimator based on the REINFORCE leave-one-out technique.
Method
The authors propose ReMix, a reinforcement routing method for Mixture-of-LoRAs designed to mitigate routing weight collapse. The method fundamentally alters the adapter architecture and training procedure to ensure diverse LoRA utilization.
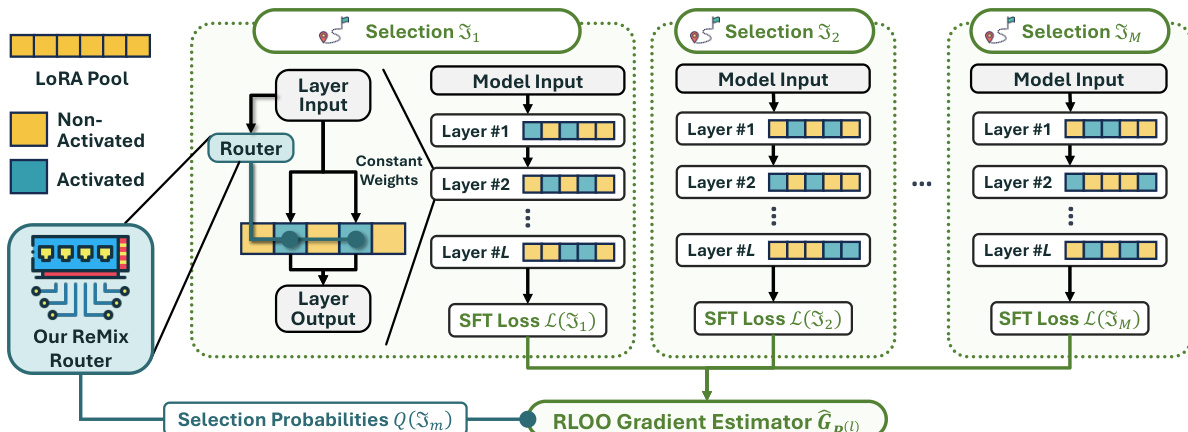
In the adapter architecture, the router computes a categorical distribution q(l) over the available LoRAs for a given layer input. Instead of using these probabilities as continuous weights, the model selects a subset of k LoRAs. Crucially, the routing weights for these activated LoRAs are set to a constant value ω, while non-activated LoRAs receive zero weight. This design guarantees that the effective support size remains fixed at k, preventing the router from concentrating probability mass on a single LoRA. The layer output is then computed as the sum of the frozen model output and the weighted contributions of the selected LoRAs.
To train the router parameters, the authors address the non-differentiability of the discrete selection process by framing it as a reinforcement learning problem. The SFT loss serves as the negative reward signal. During finetuning, the model samples M distinct selections of LoRA subsets. For each selection, the SFT loss is calculated. These losses are then used to estimate the gradient for the router parameters via the RLOO gradient estimator. This estimator leverages the variance reduction technique of using the average loss across samples as a baseline. The gradient estimator is defined as: GP(l):=M−11∑m=1M(L(Jm)−L)∇P(l)logQ(Jm) where L represents the average SFT loss across the M selections.
As shown in the figure below, the framework visualizes the ReMix architecture where the router generates selection probabilities that guide the activation of specific LoRA pools across multiple layers. The process involves generating multiple selections, computing the SFT loss for each, and aggregating these signals through the RLOO gradient estimator to update the router.
During inference, the authors employ a top-k selection strategy. Theoretical analysis shows that if the router is sufficiently trained, selecting the k LoRAs with the highest probabilities guarantees the optimal subset. This deterministic approach improves upon random sampling used during training.
Experiment
- Analysis of existing Mixture-of-LoRAs methods reveals a critical routing weight collapse where only one LoRA dominates per layer, severely limiting model expressivity and rendering other LoRAs ineffective.
- The proposed ReMix method consistently outperforms various baselines across mathematical reasoning, code generation, and knowledge recall tasks while maintaining superior parameter efficiency.
- Comparisons with single rank-kr LoRA demonstrate that ReMix successfully activates diverse LoRA subsets rather than relying on a fixed subset, validating its ability to leverage mixture capacity.
- Ablation studies confirm that both the RLOO training algorithm and top-k selection mechanism are essential components for achieving peak performance.
- Experiments show that ReMix benefits from scaling the number of activated LoRAs and increasing training compute via sampled selections, unlike deterministic baselines which cannot utilize additional compute resources.
- The method exhibits robustness to different routing weight initialization schemes, maintaining stable performance regardless of the specific weight configuration used.