Command Palette
Search for a command to run...
Les grands modèles de langage peuvent-ils suivre le rythme ? Évaluation de l'adaptation en ligne aux flux de connaissances continus
Les grands modèles de langage peuvent-ils suivre le rythme ? Évaluation de l'adaptation en ligne aux flux de connaissances continus
Jiyeon Kim Hyunji Lee Dylan Zhou Sue Hyun Park Seunghyun Yoon Trung Bui Franck Dernoncourt Sungmin Cha Minjoon Seo
Résumé
Les grands modèles de langage (LLM) opérant dans des contextes réels dynamiques sont fréquemment confrontés à des connaissances qui évoluent de manière continue ou qui émergent de façon incrémentale. Pour maintenir leur précision et leur efficacité, ces modèles doivent s'adapter en temps réel aux nouvelles informations qui arrivent. Nous introduisons OAKS (Online Adaptation to Continual Knowledge Streams), un cadre d'évaluation de cette capacité, établissant une référence pour l'adaptation en ligne face à des flux de connaissances en mise à jour continue. Plus précisément, ce benchmark est structuré comme une séquence de fragments contextuels granulaires, au sein desquels les faits évoluent dynamiquement à travers différents intervalles temporels. OAKS comprend deux jeux de données : OAKS-BABI et OAKS-Novel, où des faits individuels subissent plusieurs évolutions à travers les fragments contextuels. Ces jeux de données intègrent des annotations denses permettant de mesurer la capacité des modèles à suivre avec précision les changements. L'évaluation de 14 modèles utilisant diverses approches d'inférence révèle des limitations significatives des méthodologies actuelles. Tant les modèles de pointe que les systèmes de mémoire agentiques échouent à s'adapter de manière robuste sur OAKS, manifestant des retards dans le suivi des états et une vulnérabilité aux distractions au sein des environnements en flux continu.
One-sentence Summary
Researchers from KAIST, UNC Chapel Hill, Google, KRAFTON, Adobe, and NYU introduce OAKS, a benchmark for evaluating online adaptation to continual knowledge streams. This work reveals that current state-of-the-art models and agentic memory systems struggle with real-time state tracking and distraction in dynamic environments.
Key Contributions
- Existing benchmarks fail to isolate a model's ability to track continual updates to identical facts over time, prompting the need for a fine-grained evaluation of dynamic knowledge transitions in online settings.
- The authors introduce OAKS, the first text-domain benchmark that evaluates streaming knowledge updates at the granularity of individual facts using two new datasets, OAKS-BABI and OAKS-Novel, which feature dense annotations for tracking fact evolution.
- Evaluations of 14 models reveal that both state-of-the-art systems and agentic memory approaches struggle with robust adaptation, exhibiting significant delays in state-tracking and high susceptibility to distraction within streaming environments.
Introduction
Real-world knowledge is dynamic, requiring language models to continuously update their understanding as facts evolve over time. Existing benchmarks often fail to capture this reality because they rely on limited updates or divergent facts rather than tracking repeated changes to the same underlying information. Additionally, prior work in state tracking typically focuses on short-term, structured dialogue slots instead of long-horizon, open-ended knowledge streams. The authors address these gaps by introducing OAKS, the first benchmark designed to evaluate online adaptation to continual knowledge streams at the granularity of individual facts. This framework segments long contexts into temporal chunks to assess a model's ability to maintain temporal consistency and track state changes without updating model parameters.
Dataset
-
Dataset Composition and Sources The authors introduce OAKS, a benchmark comprising two distinct datasets designed to evaluate online adaptation to streaming knowledge: OAKS-BABI (OAKS-B) and OAKS-Novel (OAKS-N). OAKS-B is a synthetic dataset derived from the BABILong benchmark, while OAKS-N is a human-curated dataset sourced from 39 full-length literary novels in the adventure, mystery, and science-fiction genres.
-
Key Details for Each Subset
- OAKS-BABI: This subset contains 1,200 questions across four types: tracking, counting, bridge, and comparison. It utilizes a context length of 128k tokens split into 65 chunks, with an average of 4.7 answer changes per question. The data focuses on dynamic state tracking of entities and locations.
- OAKS-Novel: This subset features 870 multiple-choice questions with an average of 5.5 options per question. The context spans an average of 150.6k tokens per book (77.6 chunks), with an average of 4.7 answer changes per question. Questions require synthesizing information across multiple narrative chunks to track evolving character states or plot points.
- Stratification: Both datasets are partitioned into three subsets based on the frequency of answer changes per question: Sparse (2–3 changes), Moderate (4–5 changes), and Frequent (6–20 changes for OAKS-B; 5–19 for OAKS-N).
-
Data Usage and Evaluation Strategy The authors use the data to simulate a streaming environment where a new context chunk (2k tokens) is revealed at each time interval. Models are evaluated on the same set of questions at every interval using the cumulative context up to that point. Performance is measured by interval-level accuracy, comparing model predictions against ground-truth answers that reflect the knowledge state at that specific moment. The evaluation covers 14 models using various inference strategies, including RAG and agentic memory systems.
-
Processing and Metadata Construction
- Chunking: Texts are segmented into 2k token chunks using the GPT-NeoX tokenizer. For OAKS-N, sentence boundaries are preserved within chunks to maintain narrative coherence.
- Annotation: OAKS-B questions are generated algorithmically by parsing facts and normalizing verbs to create state transitions. OAKS-N questions are initially drafted by Gemini 2.5 Pro and then rigorously curated by human experts.
- Quality Control: For OAKS-N, human annotators filtered the initial question pool down to 55%, removing questions that did not require multi-hop reasoning or had ambiguous answers. Annotators labeled the correct answer and provided exact sentence-level evidence for every state transition at each chunk.
- Safety and Privacy: In OAKS-B, all character and location names were randomized to prevent real-world associations. OAKS-N relies on publicly available novels, and all data is in English.
- Answer Options: OAKS-N includes a "We cannot answer this question at this point" option for intervals before relevant information appears, ensuring exactly one valid answer exists for every chunk once information is revealed.
Method
The authors leverage a retrieval-augmented framework designed for dynamic entity tracking within long-form narratives. The system processes text sequentially, retrieving relevant memory chunks from previous time intervals while strictly prohibiting access to future information. This retrieval mechanism incorporates agentic memory systems, such as HippoRAG-v2 or A-Mem, which organize memory as an interconnected knowledge network. In some configurations, agents like MemAgent are trained using GRPO to handle long-context processing with linear computational complexity.
The operational workflow is depicted in the timeline diagram. The process unfolds over intervals Ti, where the system tracks the Ground Truth at and corresponding accuracy against incoming chunks ct. As shown in the figure below:
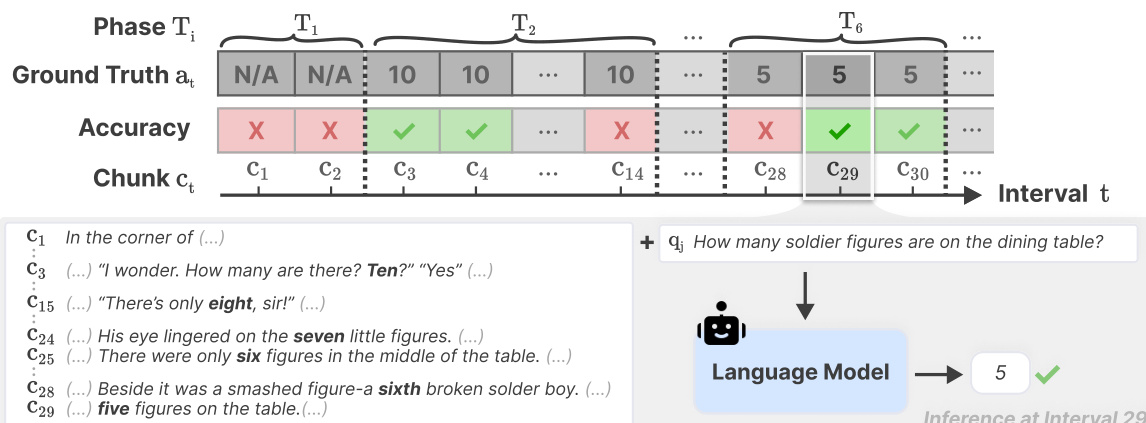 At a specific inference point such as Interval 29, the Language Model receives a query qi (e.g., "How many soldier figures are on the dining table?") alongside the relevant text context. The model generates a concise answer supported by evidence from the current or previous chunks, which is then compared to the Ground Truth to determine correctness.
At a specific inference point such as Interval 29, the Language Model receives a query qi (e.g., "How many soldier figures are on the dining table?") alongside the relevant text context. The model generates a concise answer supported by evidence from the current or previous chunks, which is then compared to the Ground Truth to determine correctness.
To evaluate the temporal dynamics of the model's reasoning, the authors categorize performance into distinct behavioral patterns. As illustrated in the behavioral analysis grid:
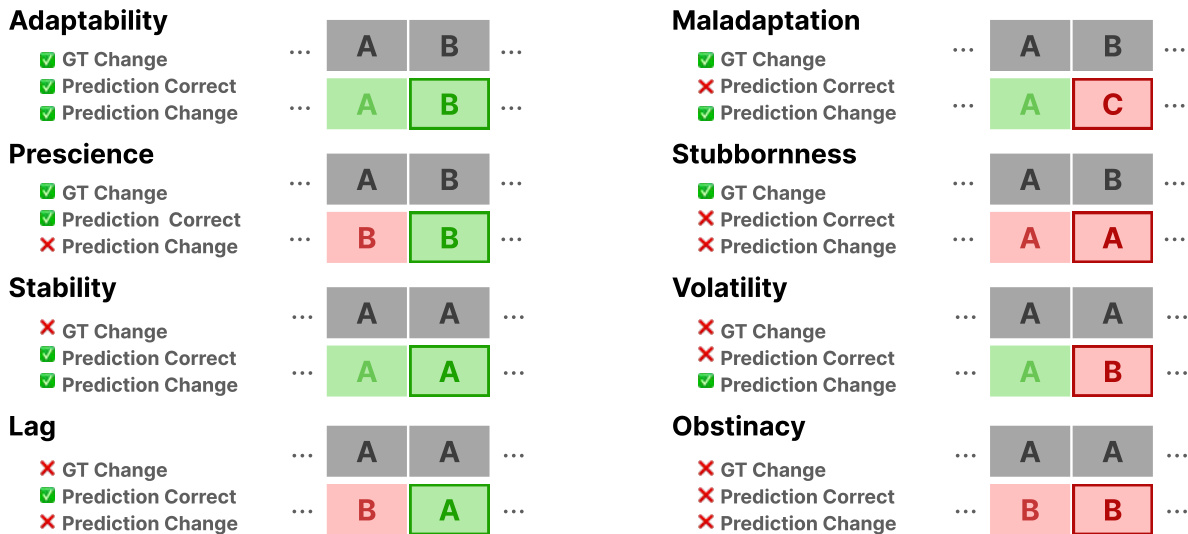 These patterns include Adaptability, where the model successfully updates its prediction following a change in Ground Truth, and Stability, where it correctly maintains a prediction when the Ground Truth is unchanged. Conversely, categories such as Lag, Volatility, and Stubbornness identify specific failure modes where the model either delays updates, fluctuates incorrectly, or persists with outdated information despite new evidence.
These patterns include Adaptability, where the model successfully updates its prediction following a change in Ground Truth, and Stability, where it correctly maintains a prediction when the Ground Truth is unchanged. Conversely, categories such as Lag, Volatility, and Stubbornness identify specific failure modes where the model either delays updates, fluctuates incorrectly, or persists with outdated information despite new evidence.
Experiment
- Evaluation of 14 large language models on the OAKS benchmark validates that online adaptation to continually evolving knowledge remains a significant challenge, with even top-tier proprietary models achieving limited accuracy.
- Experiments comparing model scales confirm that performance generally improves with larger base models and that stronger foundational architectures consistently yield better results than weaker ones.
- Analysis of knowledge transition frequency reveals that tasks involving frequent answer changes are substantially more difficult, as models struggle to balance timely updates with the retention of previously valid information.
- Tests on naive Retrieval Augmented Generation (RAG) demonstrate that simple retrieval strategies are insufficient for dynamic contexts, often failing to improve performance due to retrieval ambiguity and the model's inability to process complex, overlapping contexts.
- Inference-time scaling via explicit thinking modes is shown to significantly enhance performance on complex reasoning tasks requiring multi-hop integration, though it offers marginal gains for simpler tracking questions.
- Evaluations of advanced agentic memory systems indicate that while they can match or slightly exceed naive RAG on specific subsets, they still underperform overall, highlighting the difficulty of fine-grained, continual knowledge updates.
- Behavioral analysis identifies a persistent trade-off where models frequently detect true knowledge transitions but also exhibit high rates of unnecessary updates, leading to instability and distraction as context length increases.
- Comparative studies across question types show that bridge questions suffer most from distraction due to multi-state tracking requirements, while tracking questions face high failure rates due to frequent state changes.
- Longitudinal analysis confirms that accuracy degrades over time intervals, particularly in datasets where evidence appears only once, indicating that error accumulation is a critical failure mode not solved by standard long-context capabilities alone.