Command Palette
Search for a command to run...
ArtHOI : Synthèse d'interactions homme-objet articulées par reconstruction 4D à partir de priors vidéo
ArtHOI : Synthèse d'interactions homme-objet articulées par reconstruction 4D à partir de priors vidéo
Zihao Huang Tianqi Liu Zhaoxi Chen Shaocong Xu Saining Zhang Lixing Xiao Zhiguo Cao Wei Li Hao Zhao Ziwei Liu
Résumé
La synthèse d'interactions humain-objet (HOI) articulées physiquement plausibles, sans supervision 3D/4D, demeure un défi fondamental. Bien que les approches récentes « zero-shot » exploitent des modèles de diffusion vidéo pour générer des interactions humain-objet, elles restent largement limitées à la manipulation d'objets rigides et manquent de raisonnement géométrique 4D explicite. Pour combler cette lacune, nous formulons la synthèse d'interactions humain-objet articulées comme un problème de reconstruction 4D à partir de priors vidéo monoculaires : étant donné uniquement une vidéo générée par un modèle de diffusion, nous reconstruisons une scène 4D entièrement articulée sans aucune supervision 3D. Cette approche fondée sur la reconstruction traite la vidéo 2D générée comme une supervision pour un problème de rendu inverse, permettant de récupérer des scènes 4D géométriquement cohérentes et physiquement plausibles qui respectent naturellement les contacts, les articulations et la cohérence temporelle. Nous présentons ArtHOI, le premier cadre « zero-shot » pour la synthèse d'interactions humain-objet articulées via une reconstruction 4D à partir de priors vidéo. Nos contributions clés sont : 1) une segmentation par parties basée sur le flot optique, qui exploite le flot optique comme indice géométrique pour dissocier les régions dynamiques des régions statiques dans une vidéo monoculaire ; 2) un pipeline de reconstruction découplé : l'optimisation conjointe du mouvement humain et de l'articulation de l'objet étant instable sous l'ambiguïté monoculaire, nous récupérons d'abord l'articulation de l'objet, puis synthétisons le mouvement humain conditionné par les états de l'objet reconstruits. ArtHOI fait le lien entre la génération basée sur la vidéo et la reconstruction consciente de la géométrie, produisant des interactions à la fois sémantiquement alignées et ancrées dans la physique. Sur une diversité de scènes articulées (par exemple, l'ouverture de réfrigérateurs, d'armoires ou de fours à micro-ondes), ArtHOI surpasse nettement les méthodes antérieures en termes de précision des contacts, de réduction des pénétrations et de fidélité des articulations, étendant ainsi la synthèse d'interactions « zero-shot » au-delà de la manipulation rigide grâce à une synthèse informée par la reconstruction.
One-sentence Summary
Researchers from NTU S-Lab introduce ArtHOI, the first zero-shot framework synthesizing articulated human-object interactions by reformulating the task as a 4D reconstruction problem from monocular video priors. Unlike prior end-to-end generation methods limited to rigid objects, ArtHOI employs flow-based segmentation and a decoupled two-stage pipeline to recover physically plausible dynamics for complex articulated scenes like opening cabinets.
Key Contributions
- Existing zero-shot methods struggle to synthesize physically plausible interactions with articulated objects because they rely on rigid-body assumptions and lack explicit 4D geometric reasoning.
- ArtHOI introduces a novel two-stage reconstruction pipeline that treats monocular video generation as supervision for inverse rendering, using flow-based segmentation and decoupled optimization to recover articulated object dynamics and human motion without 3D supervision.
- Experiments on diverse scenarios like opening fridges and cabinets demonstrate that ArtHOI significantly outperforms prior approaches in contact accuracy, penetration reduction, and articulation fidelity.
Introduction
Synthesizing physically plausible human interactions with articulated objects, such as opening cabinets or doors, is critical for advancing robotics, virtual reality, and embodied AI. Prior zero-shot methods relying on video diffusion models struggle in this domain because they treat objects as rigid bodies and lack explicit 4D geometric reasoning, leading to physically implausible results and an inability to model complex part-wise kinematics. To address these limitations, the authors introduce ArtHOI, the first zero-shot framework that formulates articulated interaction synthesis as a 4D reconstruction problem from monocular video priors. Their approach leverages a decoupled pipeline that first recovers object articulation using optical flow cues and then synthesizes human motion conditioned on the reconstructed object states, ensuring geometric consistency and physical plausibility without requiring 3D supervision.
Method
The authors address the problem of synthesizing physically plausible articulated human-object interactions from monocular video priors by formulating it as a 4D reconstruction problem. To resolve the ambiguity between human movement and object articulation under weak 2D supervision, they employ a decoupled two-stage reconstruction framework. As illustrated in the framework diagram, the pipeline takes a monocular video and reconstructs a full 4D articulated scene using 3D Gaussians. The architecture separates the optimization into Stage I, which recovers object articulation with kinematic constraints, and Stage II, which refines human motion conditioned on the reconstructed geometry.
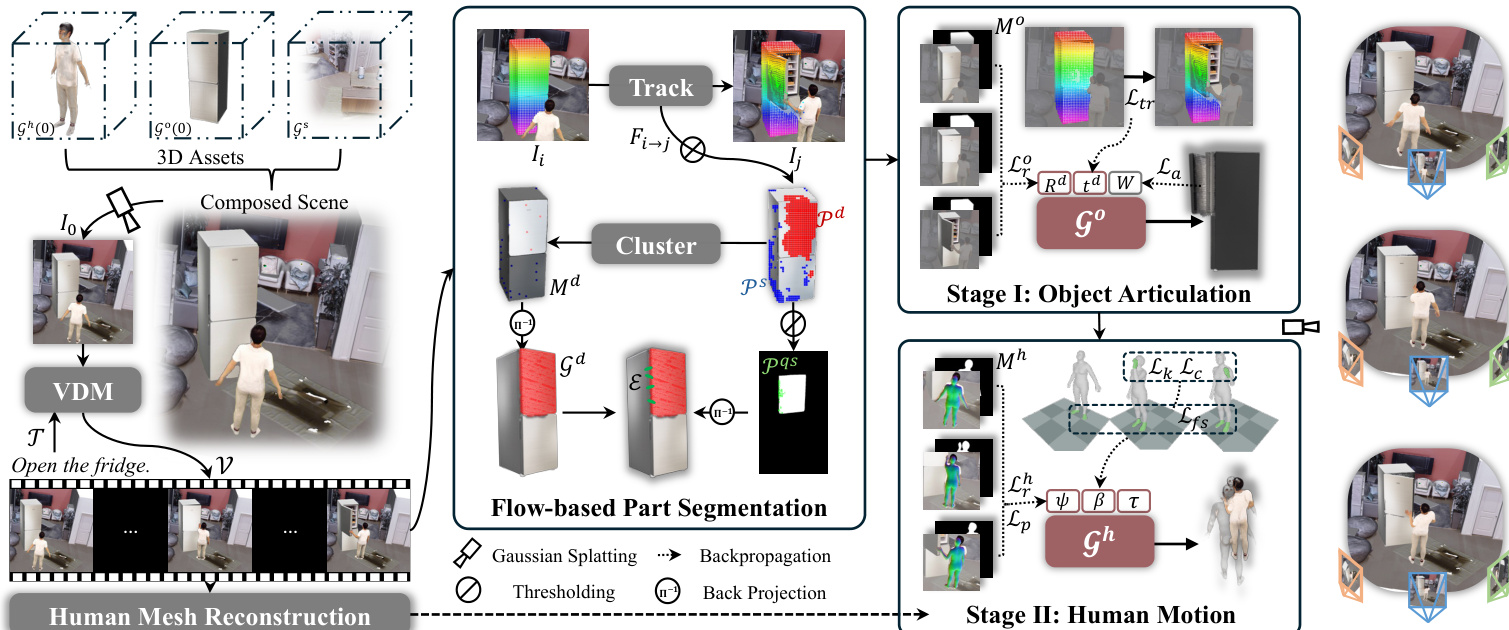
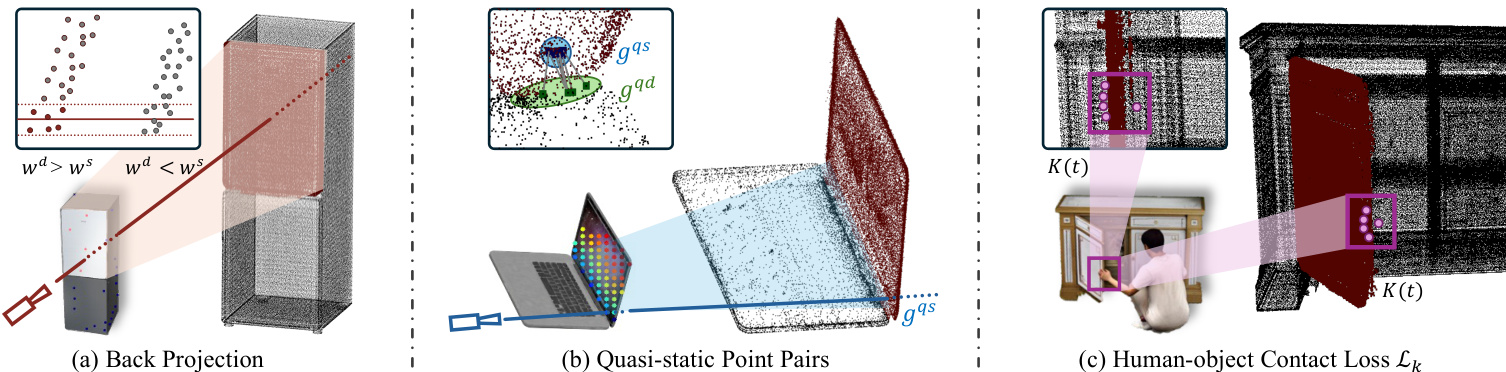
To enable kinematic modeling, the system first identifies which object regions are articulated through a flow-based part segmentation pipeline. This module combines point tracking, SAM-guided masks, and back projection to 3D. The system tracks dense 2D trajectories to classify points as dynamic or static, then uses the Segment Anything Model to produce binary masks. These masks are transferred to the 3D Gaussian representation via back projection, where pixel influences are accumulated to assign Gaussians to dynamic or static sets. To enforce rigid-body constraints, quasi-static point pairs are identified at the articulation boundary to link dynamic and static regions. The key components for this articulated interaction under monocular supervision are detailed in the figure below, which depicts back projection mapping masks to 3D, quasi-static point pairs linking regions, and the contact loss mechanism.
In Stage I, the system reconstructs object articulation by optimizing SE(3) transformations Td(t) for the dynamic parts while keeping static parts fixed. The optimization objective integrates a reconstruction loss to match the video prior, a tracking loss to align with point trajectories, and an articulation loss to maintain connectivity between binding pairs. The total loss is formulated as:
{Rd,td}minLro+λaLa+λsLs+λtrLtr.The articulation loss La penalizes changes in distance between binding pairs (gd,gs)∈E, ensuring the object parts move as a rigid body. This stage establishes a geometrically consistent 4D object scaffold.
In Stage II, the human motion is refined conditioned on the fixed object geometry. The authors derive 3D contact keypoints by identifying frames where the human mask overlaps the object silhouette but the object mask is absent, indicating occlusion by the human hand. These 2D regions are lifted to 3D using the depth of the nearest dynamic object Gaussians. The human parameters (SMPL-X) are then optimized to minimize a kinematic loss that pulls hand joints toward these 3D targets, alongside reconstruction, prior, foot sliding, and collision losses. The kinematic loss is defined as:
Lk=t=1∑Tj∈Kt∑∥Jj(θ(t))−Kj(t)∥22,where Kj(t) represents the derived 3D contact targets. This ensures physically plausible interactions without requiring multi-view input.
Experiment
- Comprehensive experiments on zero-shot articulated human-object interaction synthesis validate that the proposed method achieves superior geometric consistency, physical plausibility, and temporal coherence compared to state-of-the-art baselines.
- Interaction quality evaluations demonstrate that the approach generates more realistic foot contact, higher hand-object contact rates, and lower physical penetration than existing methods, while maintaining competitive motion smoothness.
- Articulated object dynamics tests confirm the framework's ability to accurately recover joint rotations from monocular video, significantly outperforming specialized methods designed for articulated object estimation.
- Experiments on rigid objects show that the reconstruction-informed synthesis generalizes effectively, producing better contact accuracy and physical plausibility than methods relying on depth priors or video diffusion alone.
- A user study with diverse participants reveals a strong preference for the proposed method over all baselines, particularly regarding the realism of interactions and the quality of contact.
- Ablation studies verify that the two-stage decoupled optimization, articulation regularization, and kinematic loss are critical components, as their removal leads to unstable convergence, geometric drift, and misaligned human-object contact.