Command Palette
Search for a command to run...
Valet : une plate-forme de test standardisée pour les jeux de cartes traditionnels à information imparfaite
Valet : une plate-forme de test standardisée pour les jeux de cartes traditionnels à information imparfaite
Mark Goadrich Achille Morenville Éric Piette
Résumé
Les algorithmes d'intelligence artificielle conçus pour les jeux à information imparfaite sont généralement évalués à l'aide de métriques de performance sur des jeux individuels, ce qui rend difficile l'appréciation de leur robustesse dans le contexte d'un choix varié de jeux. Les jeux de cartes constituent un domaine naturel pour l'étude des jeux à information imparfaite, en raison de la présence de mains cachées et de tirages stochastiques. Afin de faciliter la recherche comparative portant sur les algorithmes et les systèmes de jeu pour les jeux à information imparfaite, nous présentons Valet, un banc d'essai diversifié et exhaustif regroupant 21 jeux de cartes traditionnels à information imparfaite. Ces jeux couvrent un large éventail de genres, de cultures, de nombre de joueurs, de structures de paquets, de mécanismes de jeu, de conditions de victoire ainsi que de méthodes de dissimulation et de révélation de l'information. Pour standardiser les implémentations à travers différents systèmes, nous avons encodé les règles de chaque jeu dans RECYCLE, un langage de description dédié aux jeux de cartes. Par des simulations aléatoires, nous caractérisons empiriquement le facteur debranchement et la durée moyenne de chaque jeu. Nous rapportons également des distributions de scores de référence produites par un agent de recherche arborescente Monte Carlo (Monte Carlo Tree Search, MCTS) affrontant des adversaires aléatoires, afin de démontrer la pertinence de Valet en tant que suite d'étalonnage (benchmarking suite) pour l'évaluation des algorithmes de jeux à information imparfaite.
One-sentence Summary
Mark Goodrich (Hendrix College) and Achille Moreville & Éric Piette (UCLouvain) introduce Valet, a standardized testbed of 21 diverse traditional card games encoded in RECYCLE, enabling fair, reproducible benchmarking of AI algorithms like MCTS across varied information structures, branching factors, and cultural origins.
Key Contributions
- Valet introduces a standardized testbed of 21 traditional imperfect-information card games, encoded in the RECYCLE language to enable consistent cross-system evaluation and address the lack of shared benchmarks in AI research.
- The testbed captures diverse game mechanics, player counts, and information structures, and includes empirical characterizations of branching factor, game duration, and baseline MCTS performance against random agents to validate its suitability for algorithm comparison.
- By enabling systematic evaluation across varied game properties, Valet reduces overreliance on narrow benchmarks and supports reproducible, generalizable insights into how algorithm performance correlates with game design features.
Introduction
The authors leverage the need for standardized, diverse benchmarks in imperfect-information game AI to introduce Valet—a testbed of 21 traditional card games encoded in the RECYCLE language. Prior frameworks like RLCard, OpenSpiel, and CardStock offer card games but lack consistent implementations across systems, making cross-framework comparisons unreliable and performance claims fragile to game selection bias. Valet addresses this by providing fixed, standardized rule sets spanning multiple genres, player counts, and information mechanics, enabling fairer, reproducible evaluation of algorithms like Monte Carlo Tree Search. Its empirical characterization of branching factors and score distributions further supports systematic analysis of how game structure influences AI performance.
Dataset
-
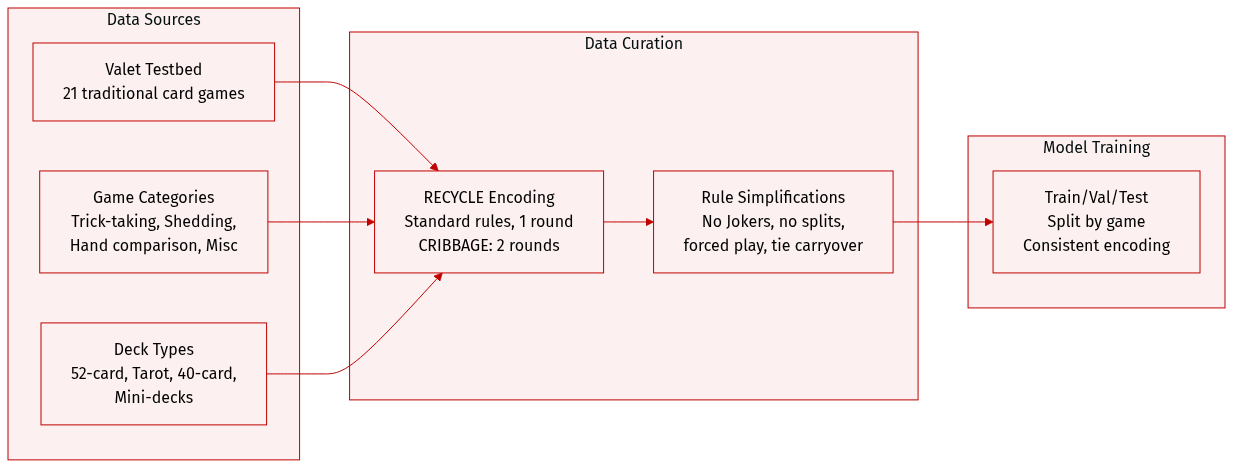
The authors use the Valet testbed, a curated collection of 21 traditional card games, selected to represent diverse genres, cultural origins, and historical development while favoring simpler rule sets. They exclude widely studied commercial or complex games like BRIDGE or TEXAS HOLD’EM in favor of foundational variants such as WHIST, KLAVERJASSEN, and LEDUC HOLD’EM.
-
The dataset spans four major game categories:
• Trick-taking (8 games): AGRAM, WHIST, EUCHRE, SUECA, HEARTS, PITCH, KLAVERJASSEN, SCARTO — varying in trump rules, scoring, and partnerships.
• Hand management/shedding (5 games): CRAZY EIGHTS, PRESIDENT, GO FISH, RUMMY, SKITGUBBE — ranging from matching to strategic planning.
• Hand comparison/exchange (4 games): BLACKJACK, LEDUC HOLD’EM, CUCKOO, SCHWIMMEN — involving betting-like decisions or hand swaps.
• Miscellaneous (4 games): GOOFSPIEL, SCOPA, GOLF-6, CRIBBAGE — introducing mechanics like simultaneous play, capture, hidden ownership, or multi-phase scoring. -
Games originate from 12 countries and use varied decks:
• Standard 52-card French deck (most common).
• 78-card Tarot deck (SCARTO).
• 40-card Spanish/Italian decks (SUECA, SCOPA).
• Reduced French-derived decks (e.g., AGRAM, EUCHRE, KLAVERJASSEN, SCHWIMMEN).
• 6-card mini-deck (LEDUC HOLD’EM). -
To ensure consistency, all games are encoded in the RECYCLE language for standardized rule implementation. Most games are limited to one round to simplify the decision space for AI; CRIBBAGE includes two rounds to balance dealer advantage. Specific rule variants are chosen for playability and clarity — e.g., American Euchre without Jokers, no card passing in HEARTS/SCARTO, simplified BLACKJACK with insurance but no splitting, Block Rummy ending when the draw deck is empty, and forced play in CRAZY EIGHTS. Ties in GOOFSPIEL carry over to the next round.
Experiment
- Experiments evaluated game diversity and decision complexity across Valet using simulations with random and MCTS agents, confirming distinct profiles in information flow, branching factor, game length, and score distribution.
- Information flow varies significantly: games differ in how public, private, and hidden information is managed, with some using multiple card backs or shared private info (e.g., crib in Cribbage), while deduction-based cues (e.g., trick-taking) remain implicit.
- Branching factor analysis reveals most games offer moderate complexity, but Go Fish, President, Skitgubbe, and Scarto show higher complexity due to game mechanics; trick-taking games share a consistent pattern with constrained later-player choices.
- Game length varies widely, with Rummy and Skitgubbe notably longer due to low-impact actions favored by random agents; most games fall between 10–100 decision points, with trick-taking games often fixed-length.
- Score distributions differ markedly: Klaaverjassen spans wide ranges, Agram and Cuckoo yield binary outcomes; MCTS outperforms random play in most games, except Cuckoo, where first-player advantage is limited, and Go Fish/Crazy Eights show minimal gain due to lack of action-history modeling.