Command Palette
Search for a command to run...
Utiliser les progressions d'apprentissage pour orienter les rétroactions par IA dans l'apprentissage des sciences
Utiliser les progressions d'apprentissage pour orienter les rétroactions par IA dans l'apprentissage des sciences
Xin Xia Nejla Yuruk Yun Wang Xiaoming Zhai
Résumé
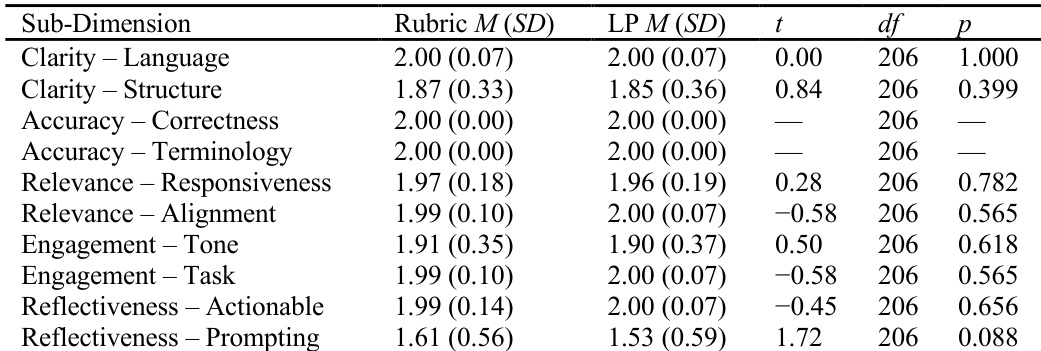
L'intelligence artificielle générative (IA) offre un soutien évolutif à la rétroaction formative ; toutefois, la plupart des rétroactions générées par IA reposent sur des grilles d'évaluation spécifiques à la tâche, rédigées par des experts du domaine. Bien qu'efficaces, l'élaboration de ces grilles est chronophage et limite l'évolutivité de leur application dans divers contextes pédagogiques. Les séquences d'apprentissage (Learning Progressions, LP) constituent une représentation théoriquement fondée de la compréhension en développement des élèves et pourraient offrir une solution alternative. Cette étude examine si un pipeline de génération de grilles fondé sur des séquences d'apprentissage peut produire des rétroactions générées par IA dont la qualité soit comparable à celle des rétroactions guidées par des grilles de tâche élaborées par des experts humains. Nous avons analysé les rétroactions générées par IA pour des explications scientifiques écrites produites par 207 élèves du collège dans le cadre d'une tâche de chimie. Deux pipelines ont été comparés : (a) des rétroactions guidées par une grilles de tâche spécifique conçue par un expert humain, et (b) des rétroactions guidées par une grilles de tâche spécifique dérivée automatiquement d'une séquence d'apprentissage préalablement à la notation et à la génération de la rétroaction. Deux codeurs humains ont évalué la qualité de la rétroaction à l'aide d'une grille multidimensionnelle mesurant six axes : Clarté, Précision, Pertinence, Engagement et Motivation, et Réflexivité (décomposés en 10 sous-dimensions). La fiabilité inter-codeurs était élevée, avec des pourcentages d'accord variant de 89 % à 100 % et des valeurs de kappa de Cohen pour les dimensions estimables allant de 0,66 à 0,88. Des tests t appariés n'ont révélé aucune différence statistiquement significative entre les deux pipelines pour la Clarté (t₁ = 0,00, p₁ = 1,000 ; t₂ = 0,84, p₂ = 0,399), la Pertinence (t₁ = 0,28, p₁ = 0,782 ; t₂ = -0,58, p₂ = 0,565), l'Engagement et la Motivation (t₁ = 0,50, p₁ = 0,618 ; t₂ = -0,58, p₂ = 0,565), ni pour la Réflexivité (t = -0,45, p = 0,656). Ces résultats suggèrent que le pipeline de génération de grilles fondé sur des séquences d'apprentissage peut constituer une solution alternative viable.
One-sentence Summary
Researchers from the University of Georgia and Gazi University propose an LP-driven rubric pipeline that generates AI feedback for middle school chemistry explanations as effectively as expert-authored rubrics, enabling scalable, theory-grounded formative assessment without task-specific human rubric design.
Key Contributions
- The study addresses the scalability bottleneck in AI-generated feedback by replacing labor-intensive expert-authored rubrics with rubrics automatically derived from learning progressions, which map students’ conceptual development in science.
- It introduces an LP-driven pipeline that generates feedback for middle school chemistry explanations and compares its quality against expert-rubric-guided feedback across five dimensions using human coder evaluations of 207 student responses.
- No statistically significant differences were found between the two feedback pipelines across Clarity, Relevance, Engagement and Motivation, or Reflectiveness, supporting LP-derived rubrics as a viable, scalable alternative to expert-designed ones.
Introduction
The authors leverage learning progressions (LPs) — empirically grounded models of how students’ understanding develops — to automatically generate task-specific rubrics for AI feedback in science education. This addresses a key bottleneck in current AI feedback systems, which rely on time-intensive, expert-authored rubrics that limit scalability across diverse classroom tasks. While prior work shows AI can generate useful feedback when guided by detailed rubrics, building those rubrics for every new task is impractical. The authors demonstrate that LP-derived rubrics produce AI feedback statistically indistinguishable in quality from expert-authored ones across dimensions like clarity, relevance, and reflectiveness — suggesting LPs can serve as a reusable pedagogical backbone to automate rubric creation and scale feedback without sacrificing quality.

Dataset
-
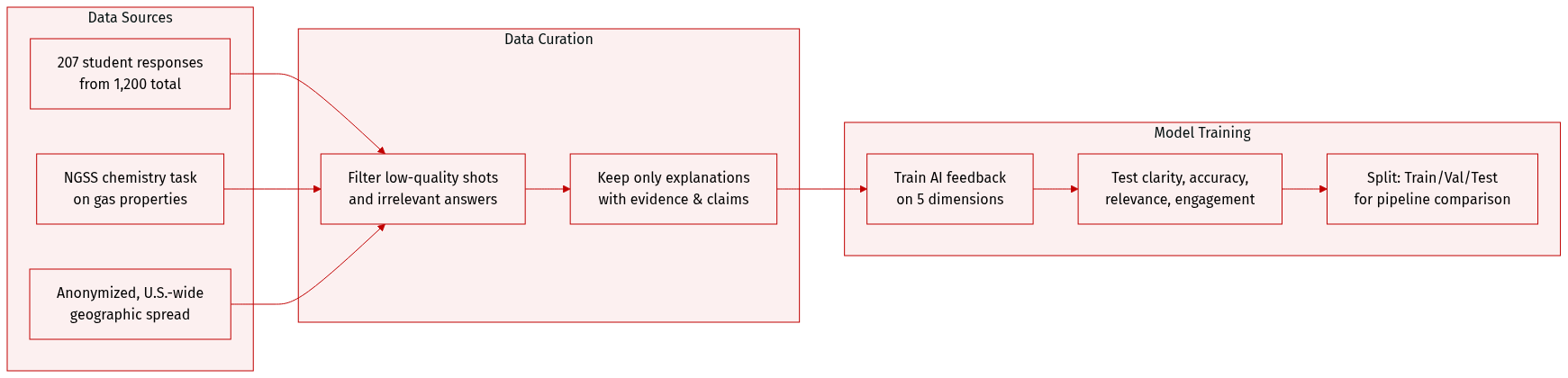
The authors use 207 anonymized middle school student responses drawn randomly from a larger pool of 1,200 responses collected via an NGSS-aligned online assessment system. No demographic data is available due to anonymization, but the sample reflects a broad U.S. geographic distribution.
-
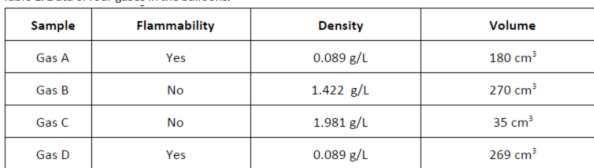
All responses stem from a single open-ended chemistry task focused on gas properties, sourced from the Next Generation Science Assessment task set. Students analyzed data on flammability, volume, and density across four gas samples and explained which gases could be the same, justifying their reasoning with evidence.
-
The task is designed to assess scientific explanation skills—specifically, connecting evidence to claims using appropriate terminology—and serves as the sole context for evaluating AI-generated formative feedback.
-
Feedback evaluation focuses on five dimensions: Clarity, Accuracy, Relevance, Engagement and Motivation, and Reflectiveness. The dataset is used exclusively to test how different AI feedback pipelines respond to student explanations and to compare feedback quality across these dimensions.
Method
The authors leverage a unified large language model—GPT-5.1—to generate feedback across both evaluation pipelines, ensuring methodological consistency. For each student response, the model is prompted to perform two core tasks: first, to evaluate the response against a specified rubric, and second, to produce formative feedback that directly aligns with the evaluation outcome. The feedback is intentionally crafted to be developmentally appropriate, supportive in tone, and pedagogically focused on guiding students toward improved scientific explanation skills.
To isolate the impact of rubric origin on feedback quality, both pipelines employ identical prompting strategies and output constraints. The only variable introduced is the source of the rubric—either human-authored or derived from a learning progression framework. This controlled design enables a direct comparison of how rubric provenance influences the quality and utility of the generated feedback.
As shown in the figure below:
Experiment
- Gas-filled balloon experiment validated measurement of gas properties under controlled conditions, focusing on flammability, volume, mass, and density.
- Two AI feedback pipelines (Expert-Rubric and Learning-Progression) were compared using a within-subjects design; both produced high-quality feedback across all dimensions.
- Feedback quality was assessed via a 5-dimension rubric (Clarity, Accuracy, Relevance, Engagement, Reflectiveness); both pipelines scored near ceiling, with perfect accuracy in scientific content.
- No statistically significant differences were found between the two pipelines across any feedback dimension, indicating equivalent effectiveness.
- Reflectiveness prompting showed slightly lower and more variable scores, suggesting room for improvement in encouraging student reflection.
- Results confirm that structured, task-aligned AI feedback can reliably deliver scientifically accurate, clear, and motivating guidance at scale.
The authors use a multi-dimensional rubric to evaluate AI-generated feedback across five quality dimensions, with human coders achieving high percent agreement and moderate to strong inter-rater reliability for most dimensions. Results show that both expert-rubric and learning-progression pipelines produce consistently high-quality feedback, with no statistically significant differences between them across any evaluable sub-dimension. Feedback was uniformly accurate, clear, relevant, and engaging, though reflectiveness prompting showed greater variability in quality.
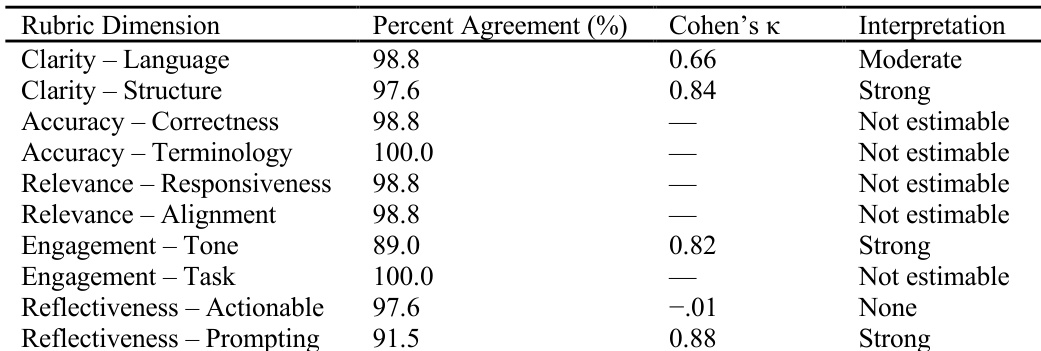
The authors compared two AI feedback pipelines—one using expert-designed rubrics and the other using learning progression-derived criteria—and found no statistically significant differences in feedback quality across any evaluated dimension. Both approaches consistently produced high-quality, scientifically accurate, and pedagogically sound feedback under controlled conditions. Results suggest that structuring AI feedback with either expert or progression-based criteria can yield similarly effective outcomes for student support.
The authors use a controlled experiment to compare gas properties across four samples, measuring flammability, density, and volume under identical conditions. Results show that flammability does not correlate with density or volume, as both flammable and non-flammable gases appear across the full range of measured values. The data indicate that these physical properties must be evaluated independently to characterize each gas accurately.