Command Palette
Search for a command to run...
La recherche de modes rencontre la recherche de moyennes pour une génération rapide de vidéos longues
La recherche de modes rencontre la recherche de moyennes pour une génération rapide de vidéos longues
Résumé
L’extension de la génération vidéo de quelques secondes à plusieurs minutes rencontre un goulot d’étranglement critique : si les données vidéo courtes sont abondantes et de haute fidélité, les données vidéo longues et cohérentes sont rares et restreintes à des domaines étroits. Pour remédier à ce problème, nous proposons un paradigme d’apprentissage où la recherche de modes s’associe à la recherche de la moyenne, découplant la fidélité locale de la cohérence à long terme grâce à une représentation unifiée via un Transformer de diffusion découplé. Notre approche utilise un head de correspondance de flux global entraîné par apprentissage supervisé sur des vidéos longues afin de capturer la structure narrative, tout en employant simultanément un head de correspondance de distribution locale qui aligne des fenêtres glissantes sur un modèle enseignant vidéo courte figé, via une divergence KL inverse orientée vers les modes. Cette stratégie permet de générer des vidéos de l’ordre de la minute, apprenant la cohérence à longue portée et les mouvements à partir de très peu de vidéos longues via une correspondance de flux supervisée, tout en conservant une réalisme local en alignant chaque segment fenêtre glissante du modèle étudiant sur un modèle enseignant vidéo courte figé, aboutissant à un générateur rapide de vidéos longues en quelques étapes. Les évaluations montrent que notre méthode permet efficacement de réduire l’écart entre fidélité et horizon en améliorant conjointement la netteté locale, la qualité du mouvement et la cohérence à longue portée. Site du projet : https://primecai.github.io/mmm/.
One-sentence Summary
Researchers from Stanford and NVIDIA propose a Decoupled Diffusion Transformer that combines supervised flow matching for long-term coherence and reverse-KL alignment to short-video teachers for local realism, enabling fast, minute-scale video generation with improved fidelity and temporal consistency.
Key Contributions
- We introduce a decoupled training paradigm that aligns sliding-window segments of a long-video generator to a frozen short-video teacher via mode-seeking reverse-KL divergence, preserving local fidelity without additional short-video data.
- Our Decoupled Diffusion Transformer uses separate Flow Matching and Distribution Matching heads to jointly learn long-range narrative structure from limited long videos and local realism from the teacher, both decoded from a shared representation.
- By leveraging only the Distribution Matching head at inference, we enable fast few-step generation of minute-scale videos that maintain sharp local motion and long-range consistency, effectively closing the fidelity–horizon gap.
Introduction
The authors leverage a decoupled training paradigm to tackle the challenge of generating minute-scale videos, where long-term coherence and local fidelity are typically at odds due to data scarcity. Prior methods that mix short and long videos assume temporal scaling is like spatial resolution scaling — an analogy the authors debunk, showing that long videos require extrapolating new events and causal structures, not just interpolating frames. Existing approaches either sacrifice local sharpness for longer duration or rely on expensive, scarce long-video datasets. Their key contribution is a Decoupled Diffusion Transformer with two heads: a Flow Matching head trained on real long videos to learn global narrative structure, and a Distribution Matching head that aligns sliding-window segments to a frozen short-video teacher using mode-seeking reverse-KL divergence — enabling fast, few-step inference while preserving both local realism and long-range consistency.
Dataset
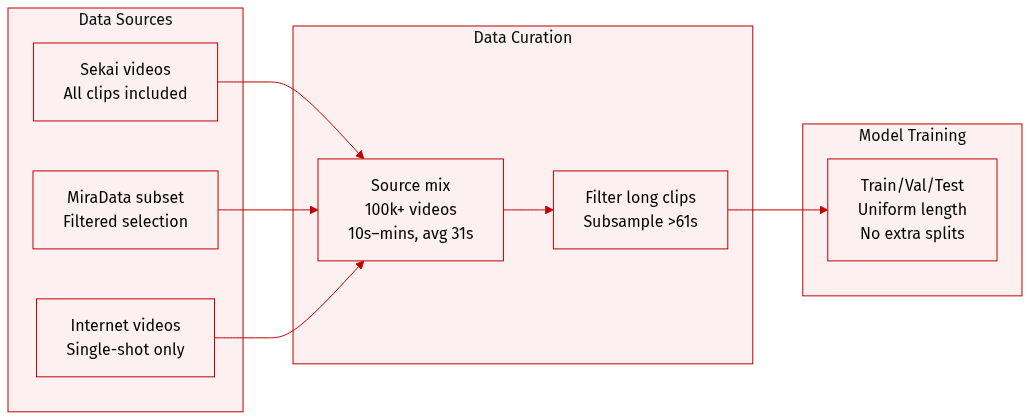
- The authors use data from multiple sources: all videos from the Sekai dataset and a filtered subset from MiraData, plus internet videos with single-shot filtering.
- The combined dataset spans over 100k videos, each 10 seconds to several minutes long, averaging 31 seconds per clip.
- Videos longer than 61 seconds are temporally subsampled to meet the upper bound.
- The data is used as-is for training, with no mention of mixture ratios or additional splits—processing focuses on uniform length via subsampling.
Method
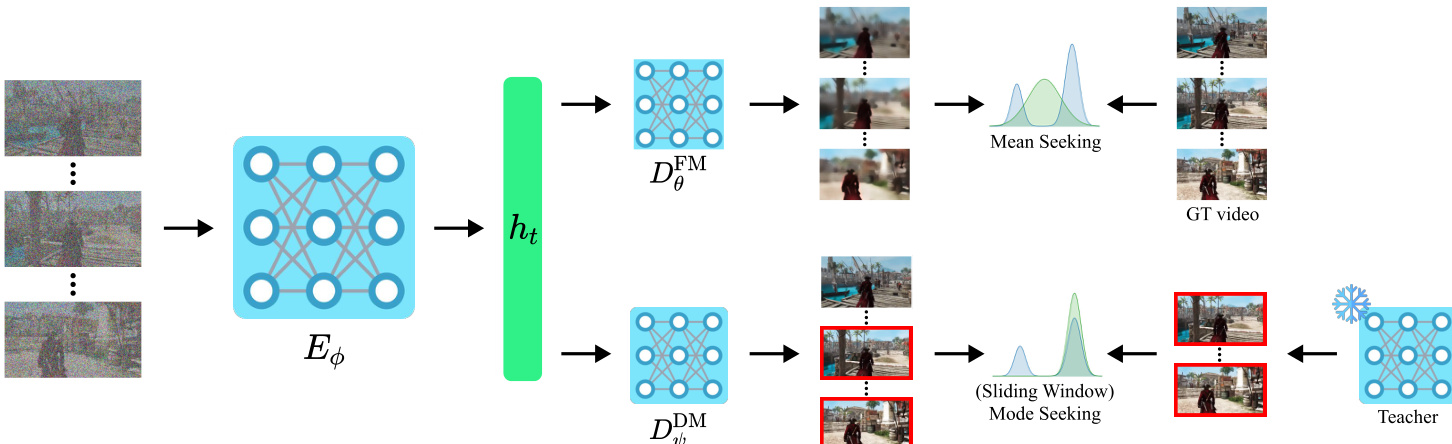
The authors leverage a decoupled architecture to reconcile the competing objectives of long-horizon coherence and local realism in video generation. The core design centers on a shared condition encoder that processes noisy long-video latents and feeds two distinct decoder heads, each optimized for a separate training signal. This structure enables the model to simultaneously learn global temporal structure from scarce long videos and preserve high-fidelity local dynamics via alignment with a short-video teacher.
The condition encoder Eϕ ingests a noisy long-video latent xtlong, along with timestep t and conditioning c, to produce a spatiotemporal feature tensor ht. Architecturally, Eϕ is implemented as a video diffusion transformer with full-range temporal attention, forming the backbone that both heads share. This shared representation ensures that long-context features are learned and reused across objectives, promoting consistency between global and local modeling.
On top of ht, two lightweight transformer decoders are attached. The first, DθFM, parameterizes the Flow Matching (FM) head, which outputs the global velocity field uθ(xtlong,t,c). This head is trained via supervised flow matching on real long videos, minimizing the mean-squared error between predicted velocity and the ground-truth marginal velocity x0long−zlong. This objective anchors the model to real long-video trajectories, encouraging minute-scale temporal coherence and narrative structure.
The second head, DψDM, implements the Distribution Matching (DM) objective. It outputs a local velocity field vψ(xtlong,t,c), which is used to generate sliding-window segments. These segments are aligned with an expert short-video teacher via a reverse-KL loss, implemented through a DMD/VSD-style gradient surrogate. Specifically, for each window k, the model crops the predicted velocity and compares it against the teacher’s velocity on the corresponding noised window. The gradient is computed as the difference between the student’s “fake” score estimator and the teacher’s velocity, scaled by a time-dependent weight λ(t), and backpropagated only through the generated window x^0(k). This mode-seeking signal encourages the student to concentrate on high-fidelity local modes of the teacher, preserving short-horizon realism without requiring access to the teacher’s training data.
Refer to the framework diagram, which illustrates how the shared encoder Eϕ feeds both the mean-seeking FM head and the mode-seeking DM head. The FM head is supervised by ground-truth long videos, while the DM head is regularized by the short-video teacher through sliding-window comparisons. This decoupling allows each head to specialize: the FM head learns global dynamics, and the DM head refines local quality.
Experiment
- Validated that SFT-only methods (LongSFT, MixSFT) establish basic temporal coherence but suffer from blurriness and loss of fine detail due to data scarcity and averaging effects.
- Confirmed that teacher-only methods (CausVid, Self-Forcing, InfinityRoPE) preserve local realism initially but degrade over time due to error accumulation and lack of long-context grounding, often resulting in static or overly conservative motion.
- Demonstrated that the proposed method outperforms baselines by decoupling global long-context learning (via SFT) from local fidelity alignment (via teacher distribution matching), achieving superior motion smoothness, scene consistency, and visual quality.
- Ablation studies confirmed the necessity of the dual-head architecture, sliding-window teacher matching, and long-video SFT — each component uniquely contributes to long-horizon coherence and short-term realism without gradient interference.
- Qualitative and quantitative evaluations across multiple metrics and Gemini-3-Pro assessments consistently support the method’s ability to generate temporally coherent, visually rich, and narratively stable long videos.
The authors use a decoupled dual-head architecture to separately handle long-range consistency and short-range fidelity, combining supervised fine-tuning on real long videos with sliding-window teacher distribution matching. Results show that removing any of these components degrades performance, confirming that both global structure learning and local texture preservation are essential for high-quality long video generation. The full model achieves the best balance across consistency, motion, and quality, outperforming ablated variants and baseline methods.
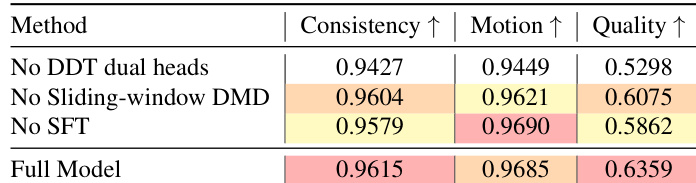
The authors use a decoupled dual-head architecture combining supervised fine-tuning on long videos with local teacher distribution matching to generate minute-scale videos. Results show this approach outperforms both SFT-only and teacher-only baselines by maintaining long-range narrative coherence while preserving high-fidelity motion and visual detail. Ablation studies confirm that each component—global SFT, local mode-seeking, and architectural separation—is essential for the observed gains in consistency and quality.
