Command Palette
Search for a command to run...
GUI-Libra : Entraînement d'agents GUI natifs à raisonner et agir grâce à une supervision consciente des actions et à un apprentissage par renforcement partiellement vérifiable
GUI-Libra : Entraînement d'agents GUI natifs à raisonner et agir grâce à une supervision consciente des actions et à un apprentissage par renforcement partiellement vérifiable
Résumé
Les agents GUI natifs open-source peinent encore derrière les systèmes propriétaires sur les tâches de navigation à long terme. Ce fossé s'explique par deux limites principales : un manque de données de raisonnement de haute qualité alignées sur les actions, et l'adoption directe de pipelines de post-entraînement génériques, qui négligent les défis spécifiques aux agents GUI. Nous identifions deux problèmes fondamentaux dans ces pipelines : (i) l'entraînement supervisé standard (SFT) avec raisonnement en chaîne de pensée (CoT) nuit souvent au repérage spatial (grounding), et (ii) l'entraînement pas à pas du type RLVR souffre d'une vérifiabilité partielle, où plusieurs actions peuvent être correctes, mais seule une action démontrée est utilisée pour la vérification. Cela rend les métriques hors ligne pas à pas de faibles prédicteurs de succès en ligne. Dans ce travail, nous présentons GUI-Libra, une recette d'entraînement spécifiquement conçue pour relever ces défis. Premièrement, pour atténuer la rareté des données de raisonnement alignées sur les actions, nous proposons un pipeline de construction et de filtrage de données, et publions un ensemble de données soigneusement sélectionné de 81 000 exemples de raisonnement GUI. Deuxièmement, pour réconcilier raisonnement et repérage spatial, nous proposons un SFT conscient des actions, qui combine des données de type « raisonnement puis action » et des données d'action directe, tout en réajustant les poids des tokens pour accentuer l'action et le repérage. Troisièmement, pour stabiliser l'apprentissage par renforcement (RL) sous vérifiabilité partielle, nous mettons en évidence l'importance négligée de la régularisation KL dans le cadre du RLVR, et montrons qu'une région de confiance KL est essentielle pour améliorer la prédictibilité du passage hors ligne vers en ligne ; nous introduisons également une mise à l'échelle adaptative au succès, afin de réduire l'impact des gradients négatifs peu fiables. Sur divers benchmarks web et mobiles, GUI-Libra améliore de manière cohérente à la fois la précision pas à pas et le taux de réussite global des tâches. Nos résultats suggèrent qu'une conception soignée du post-entraînement et une curatelle de données peuvent débloquer des capacités de résolution de tâches nettement plus fortes, sans nécessiter de collecte coûteuse de données en ligne. Nous mettons à disposition notre ensemble de données, notre code source et nos modèles afin de favoriser des recherches ultérieures sur le post-entraînement efficace en données pour les agents GUI capables de raisonnement.
One-sentence Summary
Researchers from UIUC, Microsoft, and UNC-Chapel Hill introduce GUI-Libra, a tailored training framework that enhances open-source GUI agents by curating 81K reasoning data, refining SFT with action-aware supervision, and stabilizing RL via KL regularization—boosting task completion across Android, web, and mobile benchmarks without costly online data.
Key Contributions
- To address the scarcity of high-quality reasoning data for GUI agents, GUI-Libra introduces a scalable data construction and filtering pipeline, releasing a curated 81K dataset that aligns reasoning traces with executable actions for more effective supervision.
- The framework proposes action-aware supervised fine-tuning that mixes reasoning-then-action and direct-action supervision, reweighting tokens to prioritize grounding and action tokens, thereby mitigating the grounding accuracy drop typically caused by long chain-of-thought reasoning.
- For reinforcement learning under partial verifiability, GUI-Libra stabilizes training with KL regularization and success-adaptive scaling, improving offline-to-online predictability and achieving significant gains on AndroidWorld, Online-Mind2Web, and WebArena-Lite-v2 benchmarks.
Introduction
The authors leverage native GUI agents—end-to-end vision-language models that directly map instructions to executable actions—to tackle long-horizon navigation tasks where reasoning and precise grounding must coexist. Prior work struggles with two key issues: scarce, noisy reasoning data that weakens policy learning, and generic post-training pipelines that fail to account for GUI-specific challenges like partial verifiability, where multiple valid actions exist but only one is labeled, leading to reward ambiguity and unstable RL. Their main contribution is GUI-Libra, a unified training framework that introduces a curated 81K action-aligned reasoning dataset, action-aware supervised fine-tuning that prioritizes grounding tokens to prevent CoT-induced degradation, and conservative RL with KL regularization and success-adaptive gradient scaling to stabilize learning under partial feedback. This approach boosts task completion across mobile and web benchmarks without requiring costly online interaction, proving that smarter data curation and training design can close performance gaps with closed-source systems.
Dataset

), (2) structured action in JSON (wrapped in ...).
-
13 action types supported: Click, Write, Terminate, Swipe, Scroll, NavigateHome, Answer, Wait, OpenAPP, NavigateBack, KeyboardPress, LongPress, Select.
-
Action_target (natural-language UI element description) and action_description (brief rationale) are included for filtering and context.
-
Reasoning Augmentation:
- Uses GPT-4.1 (selected after comparing GPT-4o, o4-mini, GPT-4.1) with an enhanced prompt that includes GUI-specific guidelines for structured reasoning.
- Generator can override original action if justified; coordinates from original dataset are retained as point_2d.
- Mismatches (e.g., wrong target or action) are filtered post-generation.
-
Use in Training:
- SFT dataset trains the model to map visual + textual context to reasoning + action.
- RL dataset refines policy with balanced step and domain coverage.
- Bounding-box annotations from filtering support RL reward computation.
-
Evaluation Benchmarks:
- Grounding: ScreenSpot-V2 (1,269 tasks) and ScreenSpot-Pro (1,555 tasks, high-res) measure click accuracy within ground-truth bounding boxes.
- Navigation:
- MM-Mind2Web-v2 (3,349 samples across 3 subsets) uses natural-language rewritten action histories; success requires correct grounding + exact-match action execution.
- AndroidControl-v2 (398 cleaned samples) validates action type, value, and coordinate correctness using accessibility tree mapping — avoids fixed distance thresholds.
This pipeline enables training of GUI agents that reason step-by-step, act accurately, and generalize across platforms — while addressing the scarcity of high-quality, reasoning-rich interaction data.
Method
The authors leverage a two-stage training framework, GUI-Libra, to build native GUI agents capable of both reasoning and acting within a single model. The framework addresses key challenges in existing pipelines, including grounding degradation from long chains of thought (CoT) and the partial verifiability of step-wise rewards in reinforcement learning. The overall architecture is designed to produce agents that are not only accurate in action prediction but also robust to distribution shifts and reward ambiguity during long-horizon navigation.
Refer to the framework diagram, which illustrates the end-to-end pipeline. The process begins with the construction of high-quality reasoning data, followed by an action-aware supervised fine-tuning (ASFT) stage that mixes reasoning-then-action and direct-action supervision. This is succeeded by a conservative reinforcement learning (RL) stage that incorporates KL regularization and success-adaptive negative gradient scaling to stabilize policy optimization under partially verifiable rewards.
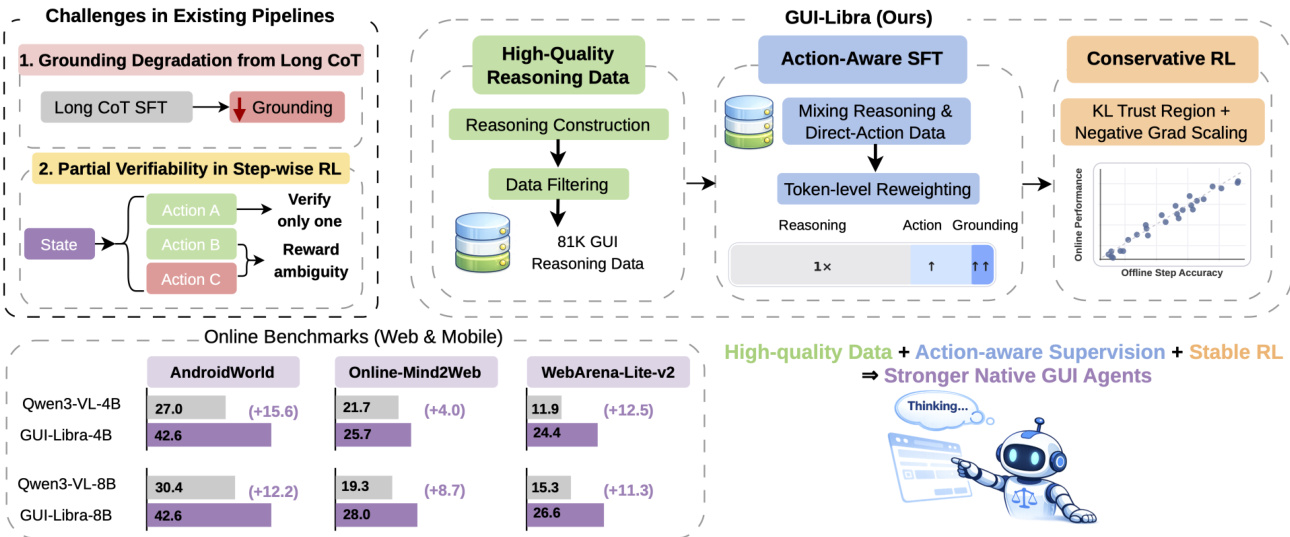
In Stage 1, the authors introduce Action-Aware SFT, which trains on a mixture of data with and without explicit reasoning traces. The mixed dataset includes both reasoning-then-action samples, where the model generates a thought process before outputting an action, and direct-action samples, where only the structured action output between and is retained. This dual-mode supervision increases the learning signal for action prediction while reducing reliance on verbose intermediate reasoning, thereby mitigating grounding degradation. The training objective further incorporates token-level reweighting, assigning higher weights to action and grounding tokens. Concretely, tokens inside ... are treated as the action output and split into action tokens (excluding the point_2d field) and grounding tokens (associated with point_2d). The ASFT objective is formulated as a weighted cross-entropy loss:
LASFT(θ)=−E(xt,ct,at,gt)∼Dmix∣ct∣+αa∣at∣+αg∣gt∣logπθ(ct∣xt)+αalogπθ(at∣xt,ct)+αglogπθ(gt∣xt,ct,at),where αa and αg control the relative importance of action and grounding tokens. This flexible weighting scheme allows the model to emphasize action-centric learning while preserving reasoning capability.
As shown in the figure below, Stage 2 employs Conservative RL, which builds upon the ASFT-initialized policy. The authors adopt a group-relative policy optimization (GRPO) framework under partially verifiable step-wise rewards. To address the challenges of distribution shift and reward ambiguity, they introduce two key components: KL regularization and success-adaptive negative gradient scaling (SNGS). KL regularization constrains policy drift by maintaining a trust region relative to a reference policy, typically the SFT initialization. This helps control the occupancy mismatch C(π) and the off-demo validity mass ηˉπ, ensuring that offline matching scores remain predictive of online success. SNGS further refines the policy gradient updates by downweighting gradients induced by ambiguous "negative" outcomes. Specifically, for each state, the empirical group success rate p^g(s) is computed from a group of G candidate actions, and a scaling factor λg(s) is applied only to negative advantages:
A~k≜{Ak,λg(s)Ak,Ak≥0,Ak<0.where λg(s)=min(λ0+κp^g(s),1). This conservative update strategy preserves reliable positive signals while attenuating updates driven by potentially valid but uncredited alternatives, leading to more robust policy optimization.
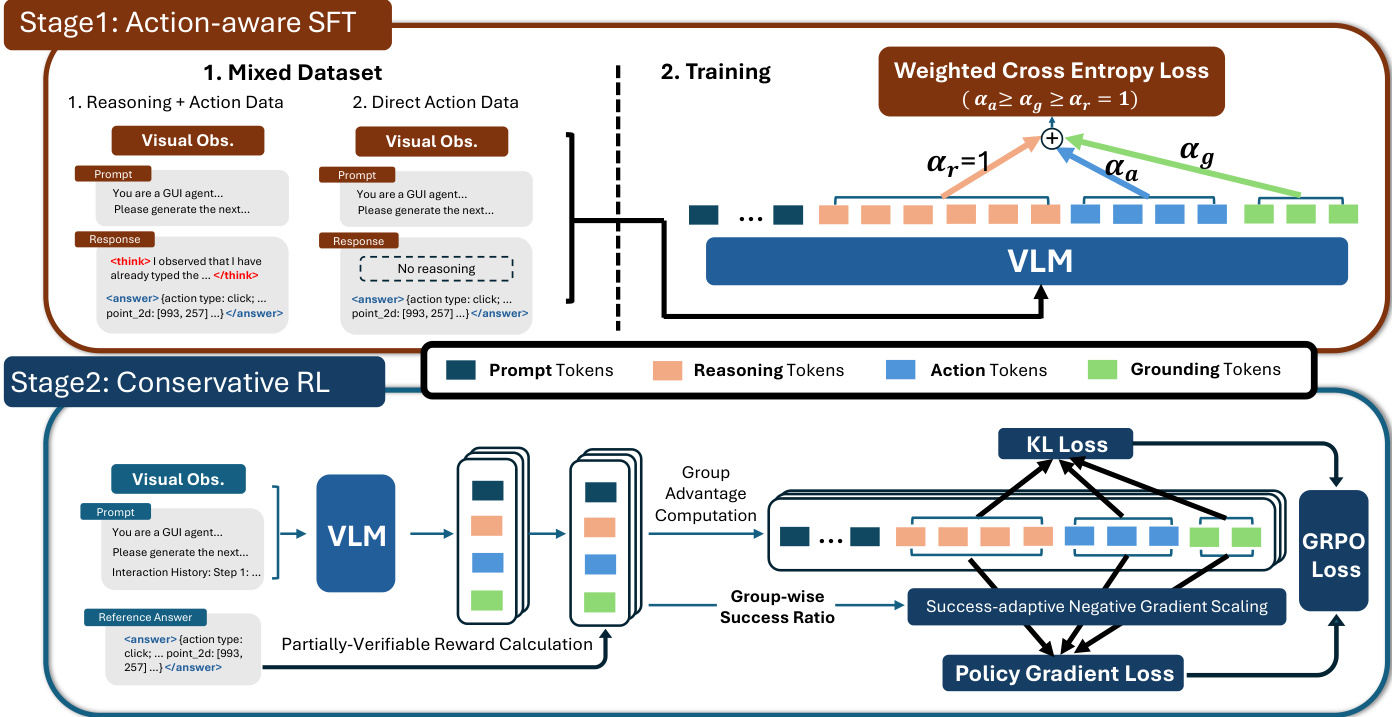
The reward function implemented in the RL stage is a weighted sum of format and accuracy rewards, with the latter being the primary focus. The accuracy reward evaluates semantic correctness by checking action type, value (using word-level F1), and grounding (whether the predicted point falls within the demonstrated bounding box). This design aligns with the partial-verifiability setting, where positive rewards indicate reliably correct predictions, while low rewards may arise from either incorrect actions or valid but uncredited alternatives.
Experiment
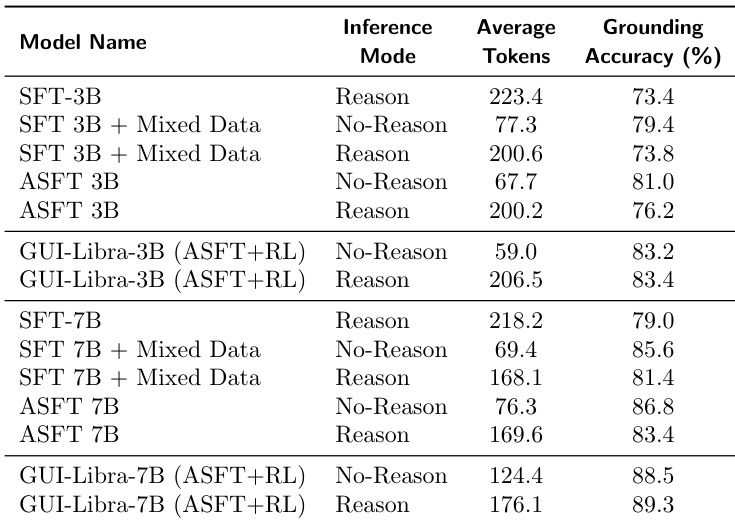
- Long CoT reasoning degrades GUI grounding accuracy, with performance declining as response length increases; removing CoT or using grounding-only training mitigates this but limits reasoning benefits.
- Action-aware SFT and RL training effectively counteract grounding degradation from long CoT by aligning reasoning with action execution, enabling high accuracy even with extended outputs.
- GUI-Libra consistently outperforms base models and many larger proprietary systems across offline and online benchmarks, particularly in long-horizon, real-world environments like AndroidWorld and live websites.
- KL regularization in RL stabilizes training, improves policy entropy, and strengthens the correlation between offline metrics and online task success, reducing reward hacking.
- Data filtering during SFT and RL enhances generalization by focusing on high-quality, balanced samples, yielding significant gains in both Pass@1 and Pass@4 metrics.
- Mixing direct grounding supervision into RL improves spatial localization but harms navigation performance, revealing a trade-off between grounding precision and reasoning capability.
- Explicit reasoning during both training and inference is critical for strong online generalization, especially in dynamic environments; removing CoT at inference degrades performance despite training with it.
- GUI-Libra’s gains stem primarily from improved grounding accuracy rather than action-type prediction, as shown by fine-grained offline metric analysis.
The authors find that longer reasoning outputs during inference consistently degrade grounding accuracy in GUI agents, but this effect is mitigated by action-aware supervised fine-tuning and further resolved through reinforcement learning. Models trained with mixed data and RL achieve high grounding accuracy even when generating long reasoning traces, outperforming both base models and standard SFT variants. Results show that RL enables models to maintain or exceed grounding performance in reasoning mode while producing significantly more tokens, indicating improved alignment between reasoning and action execution.
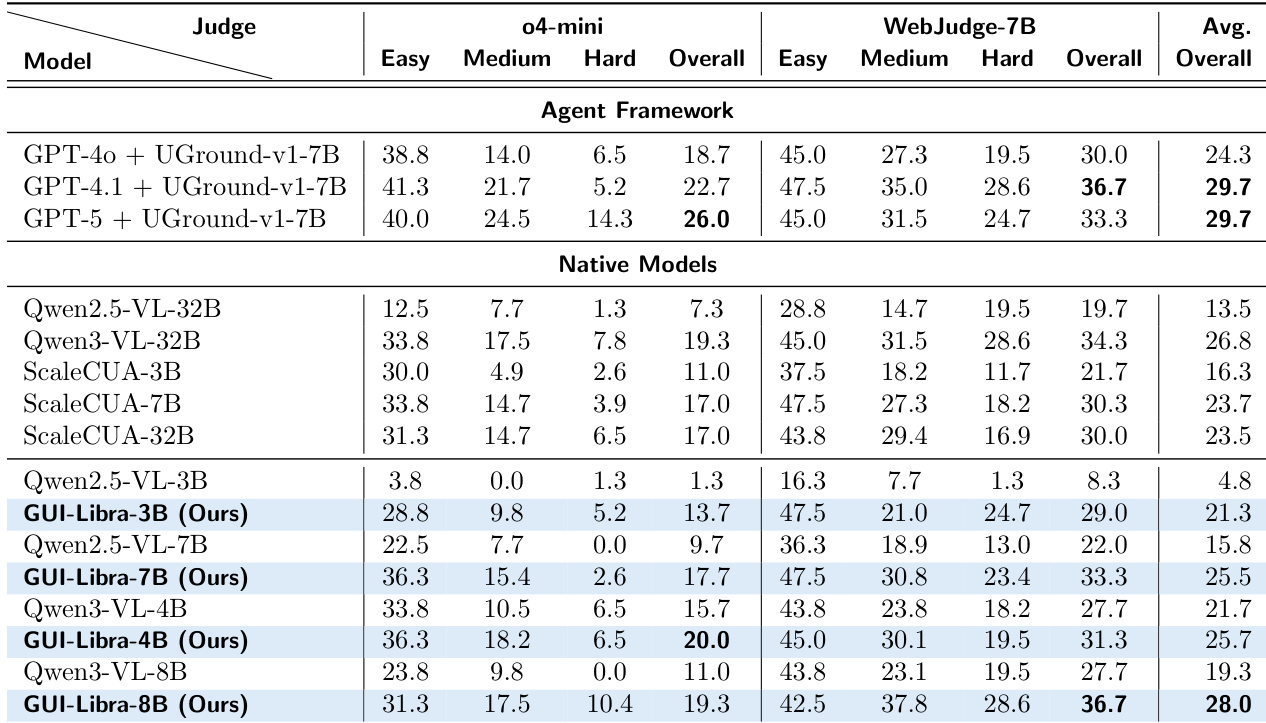
The authors find that GUI-Libra consistently outperforms both open-source and proprietary models across multiple benchmarks, achieving state-of-the-art results even with smaller parameter counts. Their method effectively mitigates the grounding degradation typically caused by long reasoning traces through action-aware SFT and RL, enabling robust performance in both offline and online settings. Results show that explicit reasoning during training and inference is critical for generalization, particularly in dynamic environments.
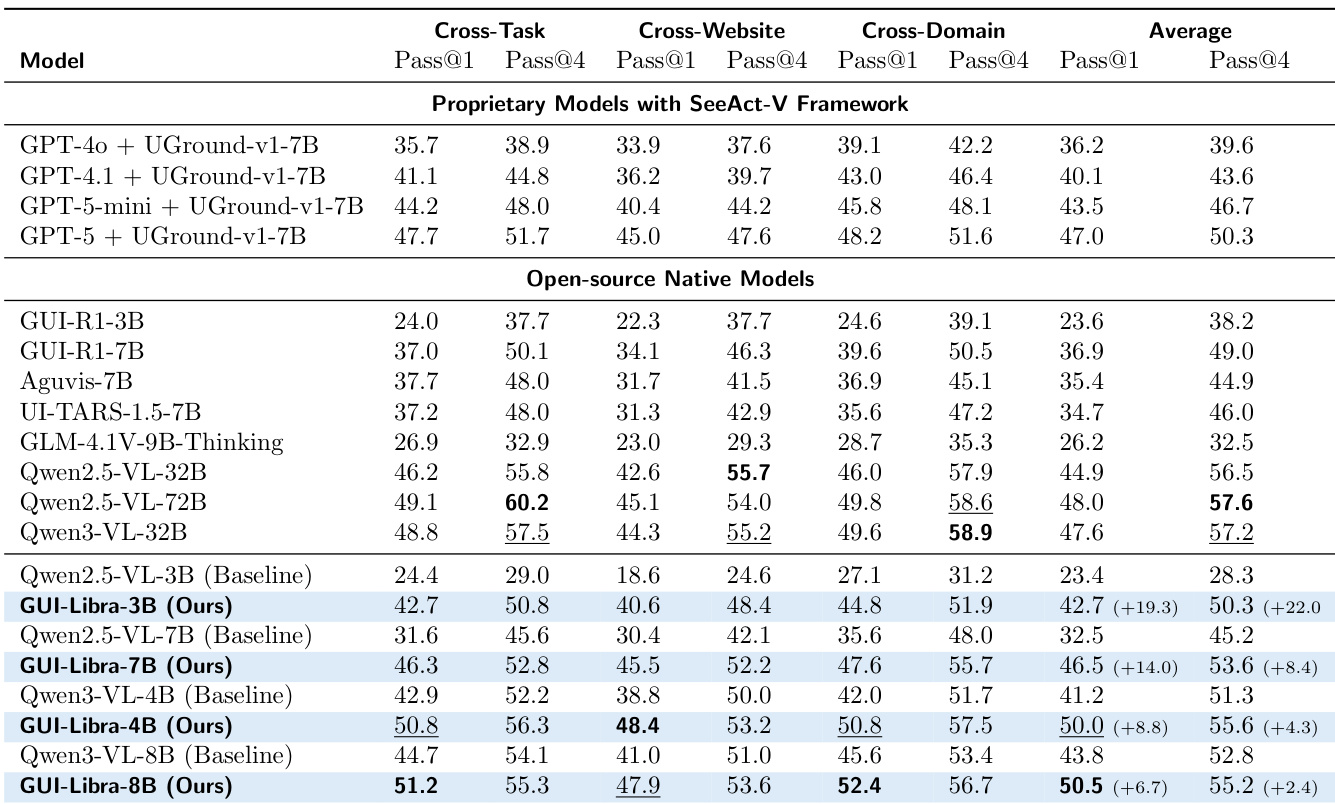
The authors show that GUI-Libra models consistently outperform both their base counterparts and other open-source and proprietary models across multiple benchmarks, achieving top-tier performance even at smaller scales. Results indicate that the method effectively closes the gap between smaller models and larger systems, particularly in cross-domain and cross-website settings, while maintaining strong average performance. The gains are attributed to the training pipeline’s ability to enhance reasoning and grounding without requiring large-scale or domain-specific data.
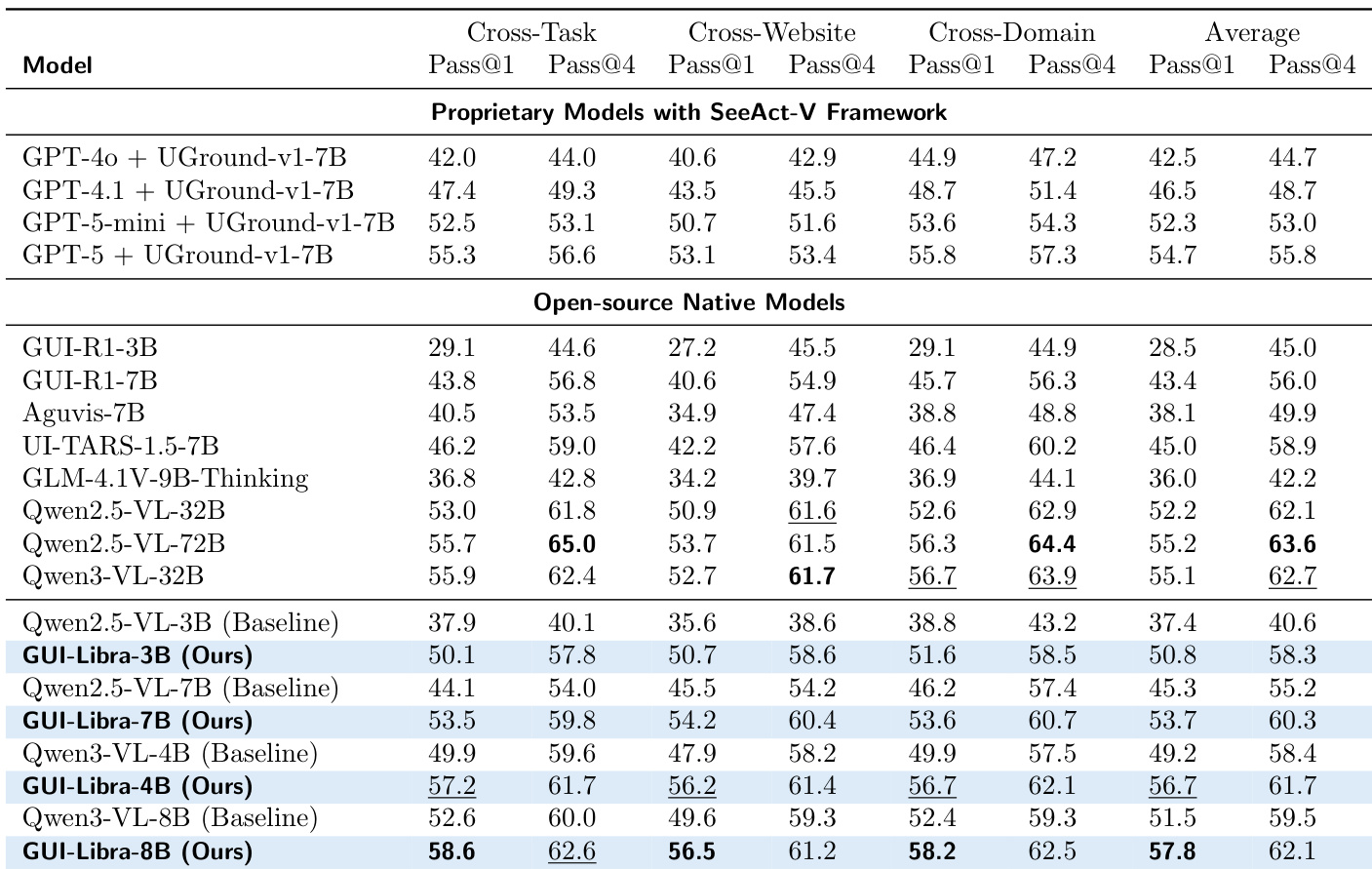
The authors find that adding step-wise summary modules to base models improves task success rates, with larger models generally achieving higher accuracy. However, GUI-Libra models without such modules still match or exceed the performance of these augmented systems, indicating that their training approach enhances native decision-making capability. This suggests that architectural simplicity combined with targeted training can rival more complex agent frameworks.

The authors find that GUI-Libra models consistently outperform both native and agent-framework baselines on Online-Mind2Web, achieving top scores under both o4-mini and WebJudge-7B evaluators. Performance scales with model size, with GUI-Libra-8B delivering the highest overall score among native models, surpassing larger open-source and proprietary systems. The results highlight GUI-Libra’s ability to generalize across difficulty levels and evaluator types while maintaining strong performance without relying on multi-module architectures.