Command Palette
Search for a command to run...
Mobile-O : Compréhension et génération multimodale unifiées sur appareil mobile
Mobile-O : Compréhension et génération multimodale unifiées sur appareil mobile
Résumé
Les modèles multimodaux unifiés sont capables à la fois de comprendre et de générer du contenu visuel au sein d’une seule architecture. Toutefois, les modèles existants restent très gourmands en données et trop lourds pour être déployés sur des dispositifs embarqués. Nous présentons Mobile-O, un modèle compact de vision-langage-diffusion qui apporte l’intelligence multimodale unifiée à un appareil mobile. Son module central, le Mobile Conditioning Projector (MCP), fusionne les caractéristiques vision-langage avec un générateur de diffusion en utilisant des convolutions séparables par profondeur et une alignement couche par couche. Ce design permet une conditionnement croisés entre modalités efficace, au coût computationnel minimal. Entraîné sur seulement quelques millions d’échantillons et post-entraîné dans un nouveau format à quadruplet (prompt de génération, image, question, réponse), Mobile-O améliore simultanément les capacités de compréhension visuelle et de génération. Malgré son efficacité, Mobile-O atteint des performances compétitives ou supérieures à celles d’autres modèles unifiés, obtenant 74 % sur GenEval, dépassant Show-O et JanusFlow de 5 % et 11 % respectivement, tout en étant 6 fois et 11 fois plus rapide. Pour la compréhension visuelle, Mobile-O surpasse ses prédécesseurs de 15,3 % et 5,1 % en moyenne sur sept benchmarks. En exécutant en seulement ~3 secondes par image de 512x512 sur un iPhone, Mobile-O établit le premier cadre pratique pour une compréhension et une génération multimodale unifiée en temps réel sur des dispositifs embarqués. Nous espérons que Mobile-O facilitera les recherches futures dans le domaine de l’intelligence multimodale unifiée en temps réel, entièrement exécutée sur appareil, sans dépendance au cloud. Notre code, nos modèles, nos jeux de données et l’application mobile sont disponibles publiquement à l’adresse suivante : https://amshaker.github.io/Mobile-O/
One-sentence Summary
Researchers from MBZUAI, CMU, and Linköping University propose Mobile-O, a compact vision-language-diffusion model with a Mobile Conditioning Projector that enables real-time unified multimodal understanding and generation on mobile devices, outperforming prior models in speed and accuracy while requiring minimal data and no cloud dependency.
Key Contributions
- Mobile-O introduces a compact vision-language-diffusion model optimized for edge devices, addressing the inefficiency and data hunger of existing unified multimodal models through a lightweight architecture and training on just a few million samples.
- Its core innovation, the Mobile Conditioning Projector (MCP), uses depthwise-separable convolutions and layerwise alignment to fuse vision-language features with diffusion generation efficiently, while a novel quadruplet training format (prompt, image, question, answer) jointly improves understanding and generation.
- Mobile-O achieves state-of-the-art results with 74% on GenEval, outperforming Show-O and JanusFlow by 5% and 11% respectively, and runs up to 11x faster, while also surpassing them by 15.3% and 5.1% on average across seven understanding benchmarks, all while generating 512x512 images in ~3s on an iPhone.
Introduction
The authors leverage unified multimodal models that combine visual understanding and image generation in a single architecture, aiming to bring this capability to edge devices like smartphones where compute and memory are limited. Prior models are too large and data-hungry, often requiring billions of parameters and hundreds of millions of training samples, making them impractical for on-device deployment. Mobile-O addresses this by introducing a lightweight Mobile Conditioning Projector that fuses vision-language features with a diffusion generator using depthwise-separable convolutions, enabling efficient cross-modal conditioning. It also introduces a novel quadruplet training format (prompt, image, question, answer) to jointly optimize understanding and generation with only 105k samples. As a result, Mobile-O achieves state-of-the-art performance on both tasks while running up to 11x faster than prior unified models and completing 512x512 image generation in ~3 seconds on an iPhone.
Method
The authors leverage a unified mobile-optimized architecture that jointly supports multimodal visual understanding and text-to-image generation. The framework integrates a vision-language encoder-decoder for understanding tasks with a diffusion-based image decoder for generation, connected via a lightweight Mobile Conditioning Projector (MCP) that enables efficient cross-modal alignment without introducing additional token sequences.
At the core, the visual understanding pathway begins with an image encoder and an autoregressive language model. Given an image and a question, the model generates an answer through an I2T (image-to-text) loss computed over the language model’s output tokens. For generation, a text prompt is processed by the same language model, whose hidden states are projected via the MCP into conditioning features for a DiT-style diffusion decoder. The generated image is then reconstructed via a VAE decoder, with training guided by a T2I (text-to-image) loss based on flow matching.
Refer to the framework diagram, which illustrates the dual pathways and their shared components. The Mobile Conditioning Projector, shown in detail on the right, fuses the final K layers of the VLM using temperature-scaled softmax weights, compresses the fused representation via a linear layer, and refines it using depthwise-separable 1D convolutions and lightweight channel attention. The output is projected to match the diffusion decoder’s conditioning dimension, enabling end-to-end alignment without query tokens.
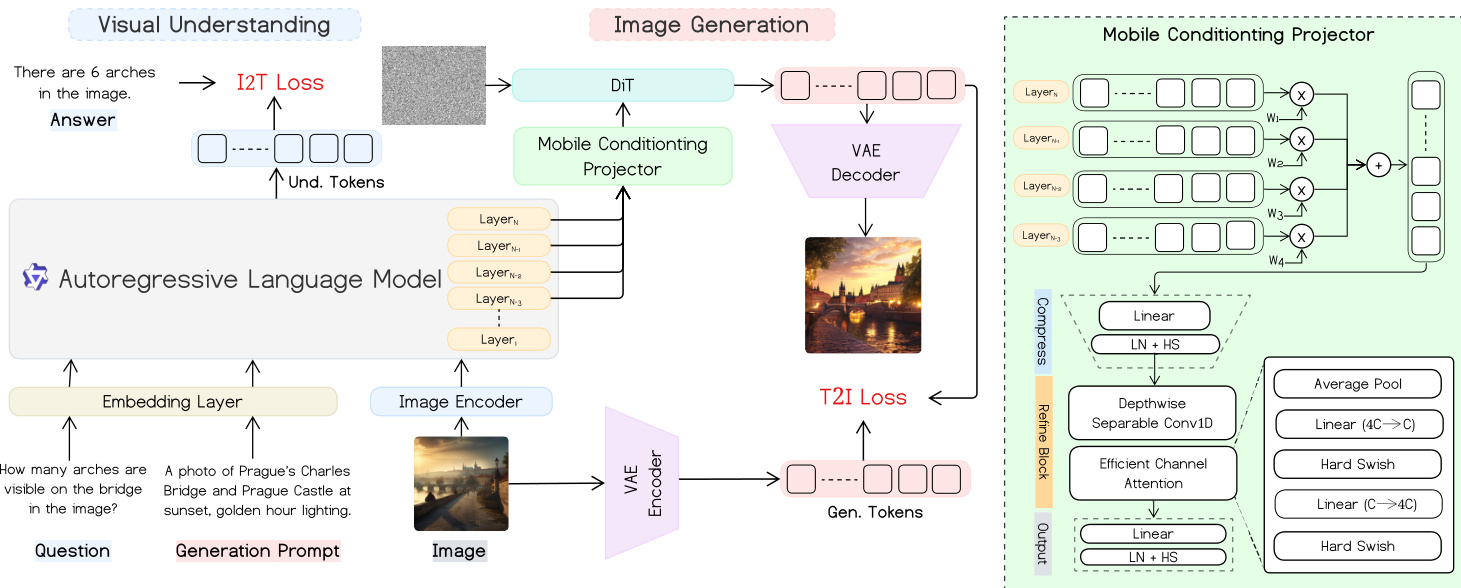
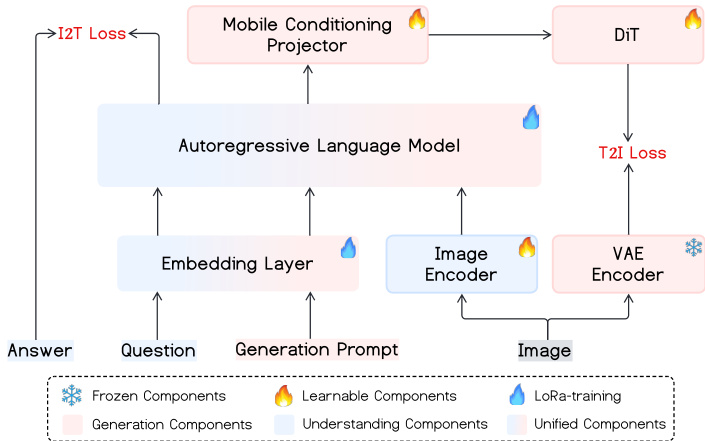
The training proceeds in three stages. In Stage 1, the visual encoder and language model are frozen while the DiT and MCP are trained on large-scale image-text pairs to establish cross-modal alignment. Stage 2 performs supervised fine-tuning on curated prompt-image pairs to address domain-specific weaknesses. Stage 3 introduces a unified multimodal post-training phase, where quadruplet samples (generation prompt, image, question, answer) are used to jointly optimize both I2T and T2I objectives. This stage enables bidirectional learning: the same embedding layer and language model support both understanding and generation, with the MCP serving as the shared conditioning interface.
As shown in the training dynamics diagram, components are selectively frozen or updated across stages. During Stage 1 and 2, only the generation components (DiT and MCP) are learnable, while the understanding backbone remains frozen. In Stage 3, the unified components—including the MCP and parts of the language model—are fine-tuned via LoRa, enabling joint optimization without destabilizing the pretrained representations.
The unified loss function combines the I2T language modeling loss and the T2I flow-matching loss with learnable weights:
Lunified=λlangLlang+λdiffLdiffThe I2T loss is standard cross-entropy over answer tokens conditioned on image and question. The T2I loss minimizes the weighted MSE between the predicted velocity field and the ground-truth flow, enabling stable and efficient training compared to traditional noise prediction objectives. The MCP’s design ensures minimal computational overhead, with complexity dominated by O(kdh+dh2) per token, avoiding expensive 2D convolutions or attention over new tokens.
Experiment
- Mobile-O validates efficient unified multimodal understanding and generation on mobile devices, outperforming prior models like Show-O and Janus in both speed and quality while fitting under 2GB memory.
- It achieves superior text-to-image generation and visual understanding via a shared Mobile Conditioning Projector and multi-task post-training, improving both capabilities without architectural changes.
- Image editing is enabled with minimal fine-tuning data, preserving scene structure while applying localized edits, demonstrating emergent capability from unified design.
- Ablation studies confirm the MCP’s effectiveness in cross-modal alignment and the value of joint quadruplet training for boosting both generation and understanding.
- Scaling to larger backbones (Mobile-O-1.5B) shows the framework generalizes, enhancing both understanding and generation beyond component baselines.
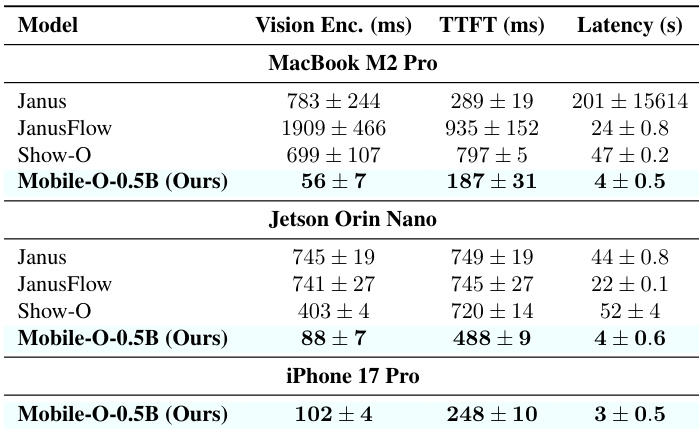
- Edge deployment on iPhone, Jetson, and MacBook proves real-time performance, with 3-second image generation and sub-0.5s text responses, enabling offline, privacy-preserving mobile AI.
- Qualitative results highlight superior fine detail rendering, prompt fidelity, and robust OCR/scene understanding, even under challenging real-world conditions.
- Limitations include constrained text representation due to shared lightweight LLM, trading expressiveness for deployability on resource-limited devices.
The authors evaluate different configurations of the Mobile Conditioning Projector (MCP) and find that using four layers with learnable fusion and a refinement block achieves the highest accuracy at 70.4% while keeping parameters under 2.4M. Results show that aggregating multiple VLM layers improves cross-modal alignment, and adding learnable weights and a refinement block further enhances performance without requiring excessive computational overhead.

The authors use a unified post-training strategy with quadruplet samples to jointly optimize both understanding and generation tasks. Results show that this approach improves average understanding accuracy by 1.6 percentage points and generation accuracy by 0.8 percentage points compared to using only image-text pairs or standard supervised fine-tuning. This demonstrates that multi-objective post-training enhances cross-modal alignment without requiring large-scale pre-training.

Mobile-O-0.5B achieves significantly faster inference speeds across all tested edge devices compared to prior unified models, with latency reductions of up to 46x for image generation on MacBook M2 Pro and under 3 seconds on iPhone 17 Pro. The model maintains efficient memory usage below 2GB while delivering real-time performance suitable for on-device deployment. Results confirm that architectural optimizations enable high-speed multimodal operations without compromising functional capabilities.
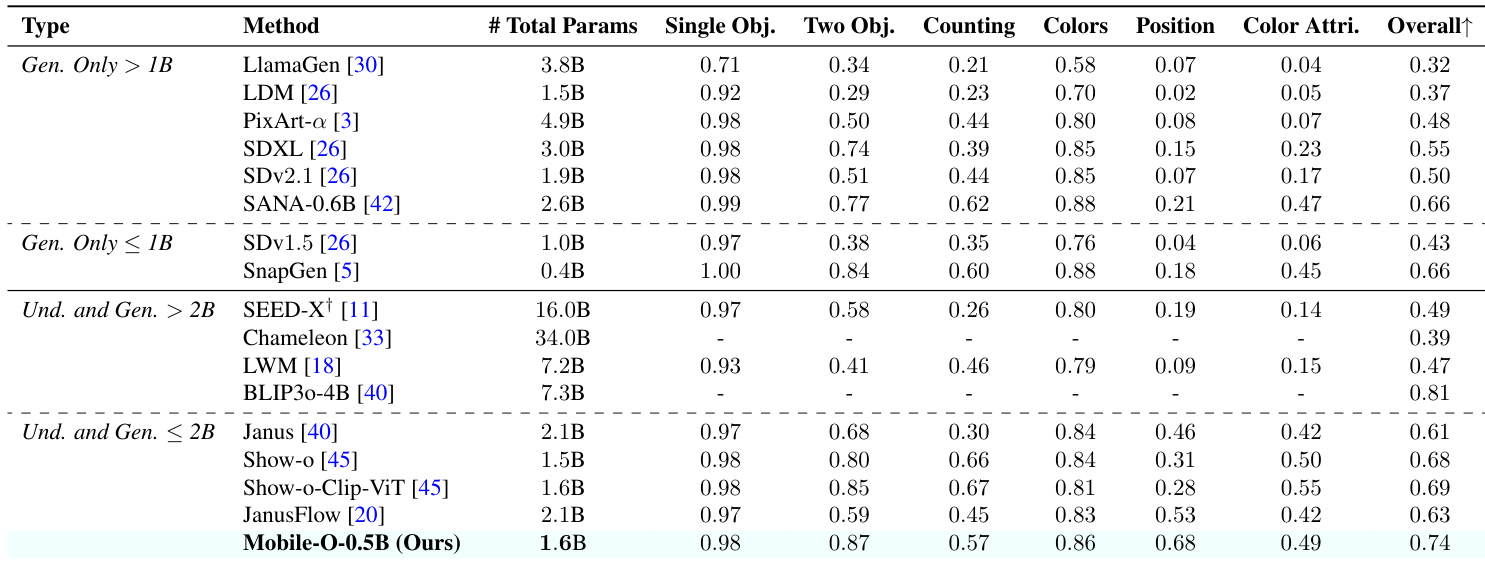
The authors evaluate Mobile-O-0.5B against other unified and generation-only models on text-to-image generation benchmarks, showing it achieves the highest overall score among models under 2B parameters. Results indicate Mobile-O-0.5B excels in generating images with accurate object counts, precise color attributes, and correct spatial positioning, outperforming comparable unified models like Show-O and JanusFlow. This performance is achieved while maintaining a compact parameter count and efficient inference, supporting its suitability for edge deployment.
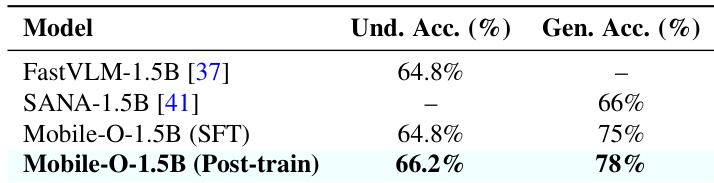
The authors use a larger backbone configuration to scale Mobile-O to 1.5B parameters and evaluate its performance after supervised fine-tuning and post-training. Results show that post-training improves both understanding accuracy and generation quality, with the final model outperforming its individual component backbones. This confirms that the Mobile-O framework effectively enhances unified multimodal capabilities even when scaled to larger architectures.