Command Palette
Search for a command to run...
Le Vision Wormhole : Communication dans l’espace latent des systèmes multi-agents hétérogènes
Le Vision Wormhole : Communication dans l’espace latent des systèmes multi-agents hétérogènes
Xiaoze Liu Ruowang Zhang Weichen Yu Siheng Xiong Liu He Feijie Wu Hoin Jung Matt Fredrikson Xiaoqian Wang Jing Gao
Résumé
Les systèmes multi-agents (MAS) alimentés par des grands modèles linguistiques ont permis une avancée significative dans le raisonnement collaboratif, mais ils restent freinés par l’inefficacité des communications textuelles discrètes, qui engendrent un surcroît important de temps d’exécution et une perte de précision liée à la quantification de l’information. Bien que le transfert d’états latents offre une alternative à large bande passante, les approches existantes supposent soit des architectures émetteur-récepteur homogènes, soit s’appuient sur des traducteurs appris spécifiquement pour chaque paire d’agents, ce qui limite leur évolutivité et leur modularité face à des familles de modèles hétérogènes aux variétés disjointes. Dans ce travail, nous proposons le Vision Wormhole, un cadre novateur qui réutilise l’interface visuelle des modèles vision-langage (VLM) pour permettre une communication sans texte, indépendante du modèle. En introduisant un codeur visuel universel, nous projetons des trajectoires de raisonnement hétérogènes dans un espace latent continu partagé, que nous injectons directement dans la voie visuelle du récepteur, traitant ainsi efficacement l’encodeur visuel comme un port universel pour une télépathie inter-agents. Notre cadre adopte une topologie en étoile (hub-and-spoke), réduisant la complexité d’alignement pair à pair de O(N²) à O(N), et exploite une méthode de distillation enseignant-étudiant sans étiquettes pour aligner le canal visuel à haute vitesse avec les schémas de raisonnement robustes de la voie textuelle. Des expérimentations étendues sur des familles de modèles hétérogènes (par exemple, Qwen-VL, Gemma) montrent que le Vision Wormhole réduit le temps réel d’exécution global dans des comparaisons contrôlées tout en préservant une fidélité au raisonnement comparable à celle des MAS basés sur le texte. Le code est disponible à l’adresse suivante : https://github.com/xz-liu/heterogeneous-latent-mas
One-sentence Summary
Purdue, CMU, and Georgia Tech researchers propose Vision Wormhole, a model-agnostic framework using visual interfaces to enable text-free, high-bandwidth communication in multi-agent systems, reducing runtime while preserving reasoning fidelity across heterogeneous LLMs like Qwen-VL and Gemma.
Key Contributions
- The Vision Wormhole addresses the inefficiency of text-based communication in multi-agent systems by repurposing the visual interface of Vision-Language Models to enable model-agnostic, continuous latent transfer, bypassing discrete tokenization overhead and quantization loss.
- It introduces a Universal Visual Codec that maps heterogeneous reasoning traces into a shared latent space and injects them via the vision encoder, using a hub-and-spoke topology to reduce alignment complexity from O(N²) to O(N) and a label-free distillation objective to align visual and text reasoning pathways.
- Evaluated across diverse model families including Qwen-VL and Gemma, the framework reduces end-to-end wall-clock time while preserving reasoning fidelity comparable to standard text-based MAS, demonstrating scalable, plug-and-play communication without pairwise adapters.
Introduction
The authors leverage Vision-Language Models’ visual encoders to enable high-bandwidth, text-free communication between heterogeneous LLMs in multi-agent systems. Traditional text-based messaging imposes runtime overhead and quantization loss, while prior latent-space methods either assume homogeneous models or require expensive pairwise translators that don’t scale. Their key contribution is the Vision Wormhole: a universal visual codec that maps diverse model outputs into a shared latent space, then injects them via the VLM’s visual pathway—bypassing tokenization entirely. This hub-and-spoke design reduces alignment complexity from O(N²) to O(N) and uses teacher-student distillation for label-free training, enabling plug-and-play integration across model families like Qwen-VL and Gemma while preserving reasoning fidelity and cutting wall-clock time.
Dataset

-
The authors use nine benchmark datasets spanning math/science reasoning (GSM8K, AIME 2024/2025, GPQA, MedQA), commonsense reasoning (ARC-Easy, ARC-Challenge), and code generation (MBPP-Plus, HumanEval-Plus), evaluating with accuracy or pass@1 as appropriate.
-
For codec training, they construct anchor corpora from three sources: cos_e, OpenCodeReasoning, and PRM800K. The default setting uses 1,000 examples per source (3,000 total); a weakly supervised variant uses 30 per source (90 total). Anchors are shuffled with a fixed seed and loaded via streaming to avoid full materialization.
-
At training time, they sample mini-batches of size 2 uniformly at random across 400 optimization steps (800 total draws), yielding ~0.27x coverage for the default setting and ~8.9x for the weakly supervised variant.
-
The codec architecture uses 6 transformer layers, 8 attention heads, dropout 0.10, and maps latent states to a fixed 512-dim space with 1024 universal tokens and 256 image-side injection tokens. Training uses AdamW (lr=2e-4), with a loss combining hidden-state MSE (weight 1.0), KL-style logit alignment (weight 0.25), and injection-statistics regularization (weight 0.1).
-
For multi-model inference, they merge per-model codecs via closed-form ridge regression to align universal spaces — avoiding end-to-end retraining — and keep architecture, optimizer, and sampling strategy fixed across variants.
-
The model uses frozen off-the-shelf backbones (Qwen, Google Gamma, SmolVLM2, LFM2.5-VL) in heterogeneous MAS setups, alternating roles (Planner → Critic → Refiner → Judger) across 2 or 4 models. Vision Wormhole encodes reasoning traces into visual tokens injected via the vision pathway, enforcing bounded bandwidth and fixed latent-step budget.
-
Baseline comparisons are against TextMAS (text-mediated communication) under identical roles and prompts; other latent methods (Cache-to-Cache, LatentMAS) were unstable under their heterogeneous backbones and excluded from main results.
Method
The authors leverage a novel latent communication framework called the Vision Wormhole, which enables heterogeneous vision-language models (VLMs) to exchange continuous semantic messages via their image-token spans—without modifying backbone parameters or requiring text-based intermediaries. The architecture is modular, comprising three stages: per-agent codec training, cross-model affine alignment, and inference-time message passing—all designed to preserve the frozen VLM’s semantic fidelity while enabling high-bandwidth, bounded-cost inter-agent communication.
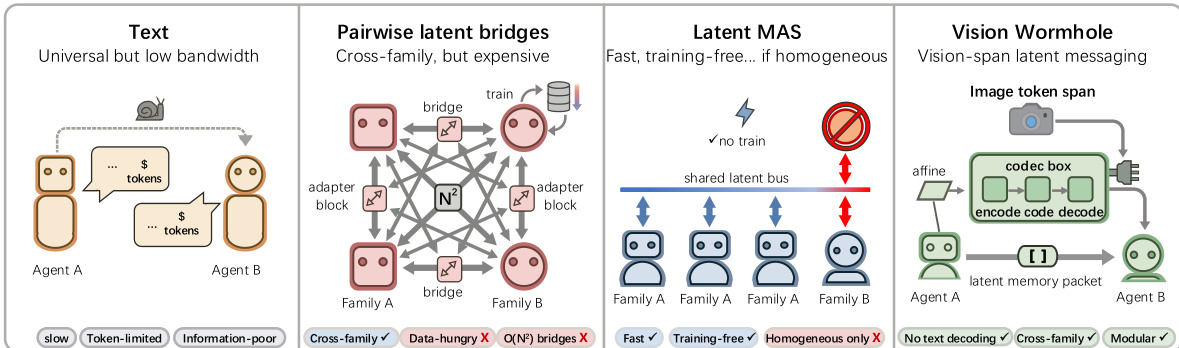
Refer to the framework diagram, which contrasts the Vision Wormhole with prior approaches such as text-based messaging, pairwise latent bridges, and homogeneous latent MAS. The Vision Wormhole uniquely combines cross-family compatibility, training-free inference, and modularity by repurposing the VLM’s native visual interface as a continuous prompt channel.
In the first stage, each agent’s codec is trained independently via label-free self-distillation. Given an anchor text message m, the frozen VLM backbone generates a latent rollout Hi∈RT×di by iteratively feeding back norm-calibrated pseudo-token embeddings derived from hidden states, using cached attention context. This rollout serves as a compact, continuous summary of the agent’s internal reasoning state. The encoder Ei, implemented as a Perceiver-style resampler, compresses Hi into Ku=K+2 universal tokens Ui∈RKu×D, where K tokens encode semantics and two special tokens capture global and style statistics. The decoder Di then maps Ui to a vision-span perturbation Δi∈RKimg×di and a scalar gate gi∈(0,1), which modulates injection strength. The perturbation is written residually into the agent’s image-token span relative to a fixed dummy-image baseline Xˉimg(i):
Ximg(i)=Xˉimg(i)+gi⋅Resample(Δi;Limg(i))Training minimizes a distillation loss that aligns the student (vision-injected) hidden state and next-token logits with the teacher (text-injected) outputs, while also regularizing the RMS magnitude of the injected perturbation to remain near the visual embedding manifold.
In the second stage, the authors align codecs across heterogeneous agents using a hub-and-spoke affine mapping strategy. Instead of training O(N2) pairwise adapters, each agent learns two lightweight affine transforms—Aiout to map its universal tokens into a shared reference space U, and Aiin to map back. These maps are fitted via ridge regression on a small set of anchor texts, leveraging the fact that the encoder already compresses messages into a structured, low-dimensional token set that is amenable to linear alignment. The affine maps are defined as:
Uref=Aiout(Ui)=UiWiout+1(biout)⊤,Ui=Aiin(Uref)=UrefWiin+1(biin)⊤,where Wiout,Wiin∈RD×D and biout,biin∈RD.
As shown in the figure below, the inference pipeline operates entirely in the reference universal space. During collaboration, a sender agent extracts a latent rollout, encodes it into universal tokens, and maps them to the reference space via Asout. The receiver agent maps the tokens back via Aiin, decodes them into a vision-span perturbation, and injects it into its image-token span. Memory aggregation concatenates multiple received messages along the token dimension before decoding, ensuring bounded communication cost regardless of message verbosity. The final agent emits the natural-language answer, while intermediate roles only produce latent rollouts.

This design enables plug-and-play inference across model families, avoids pairwise training overhead, and exploits the VLM’s pre-trained capacity to interpret continuous visual embeddings as semantic context—thereby transforming the image-token span into a high-fidelity, modality-agnostic communication channel.
Experiment
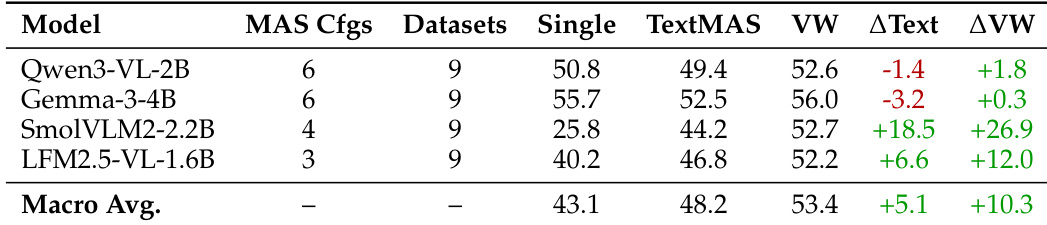
- Vision Wormhole (VW) consistently accelerates inference and often improves accuracy over TextMAS across heterogeneous multi-agent setups, with macro-average gains of +6.3pp accuracy and 1.87x speedup.
- Strongest improvements occur in code generation tasks, where VW delivers +13.2pp accuracy gains alongside 1.21x speedup, though performance varies by role assignment and backbone pairing.
- Under weak supervision (fewer than 100 anchor texts), VW maintains robust performance with +6.5pp accuracy gain and 2.67x speedup, confirming the visual interface’s effectiveness as a continuous communication port.
- Compared to single-agent baselines, VW better preserves strong-model performance while enhancing weaker models, indicating reduced cross-role interference from bounded latent communication.
- In mid-sized models (4B–12B), VW achieves high speedups (5.92x macro-average, exceeding 10x on some tasks) but shows accuracy drops on complex tasks, suggesting default bandwidth limits for stronger backbones.
- Runtime analysis reveals VW produces faster, more stable inference with tighter latency distributions, as fixed visual token spans reduce variability inherent in variable-length text messaging.
- These efficiency and stability benefits persist across main, weakly supervised, and mid-sized settings, supporting VW’s adaptability and robustness under diverse conditions.
The authors use Vision Wormhole to replace text-based communication in multi-agent systems, observing consistent speedups across datasets while maintaining or improving accuracy in most cases. Results show that the visual interface reduces runtime variability and enables efficient collaboration, especially for code generation tasks, though accuracy can degrade on complex reasoning benchmarks when using larger models under fixed communication bandwidth. The approach proves robust under weak supervision and helps preserve strong model performance in heterogeneous teams compared to text-only coordination.
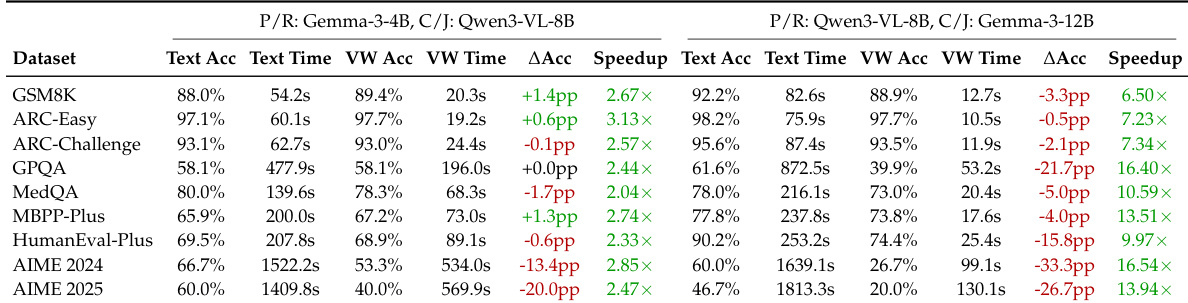
The authors compare single-agent baselines with multi-agent system (MAS) configurations using TextMAS and Vision Wormhole (VW) communication. Results show that VW consistently outperforms TextMAS in preserving or enhancing accuracy relative to single-agent performance, especially for weaker models, while also delivering substantial gains in system efficiency. For stronger models, VW mitigates the accuracy drops typically seen in TextMAS, indicating greater robustness to orchestration effects in heterogeneous agent teams.
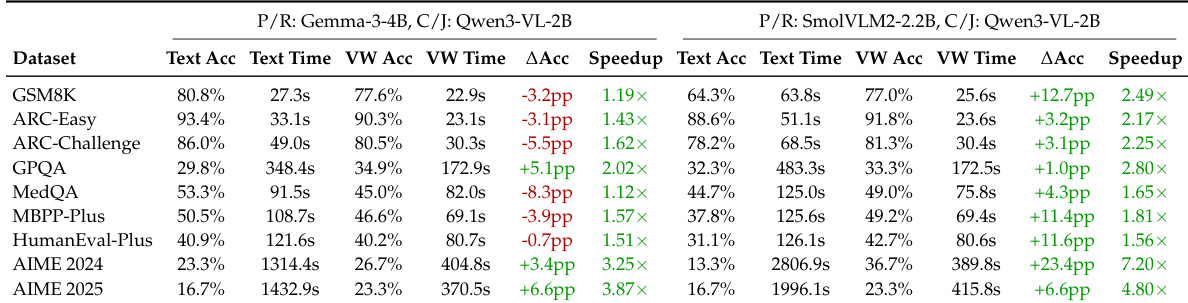
The authors compare Vision Wormhole against TextMAS across multiple heterogeneous multi-agent setups, finding that Vision Wormhole consistently reduces inference time while often maintaining or improving accuracy, especially for weaker backbones. Results show that Vision Wormhole better preserves the performance of strong single models in collaborative settings and exhibits more stable runtime behavior due to its bounded communication interface. In larger models, while speedups remain substantial, accuracy can degrade if the fixed communication bandwidth becomes a bottleneck for richer reasoning states.
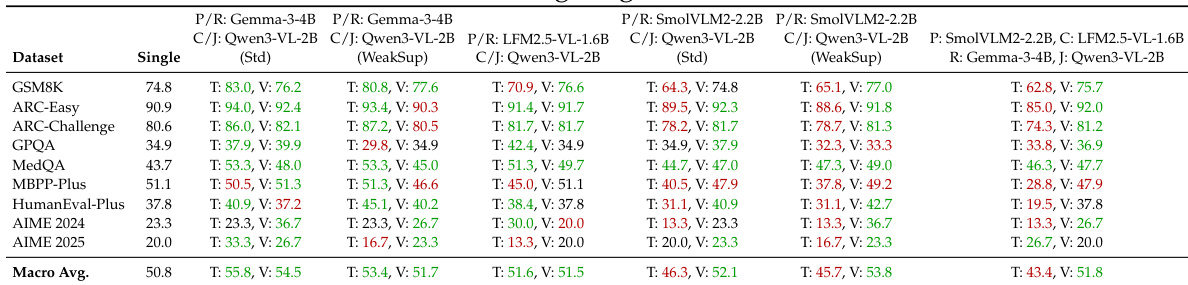
The authors use Vision Wormhole to replace text-based communication in multi-agent systems, finding it consistently reduces inference time while often improving accuracy across diverse model configurations. Results show the approach is particularly effective for code generation tasks and remains robust even under weak supervision, with speedups up to 2.67x and accuracy gains averaging +6.5pp. However, on larger models with fixed communication bandwidth, accuracy can degrade on complex tasks, suggesting bandwidth must scale with model capacity to maintain performance.
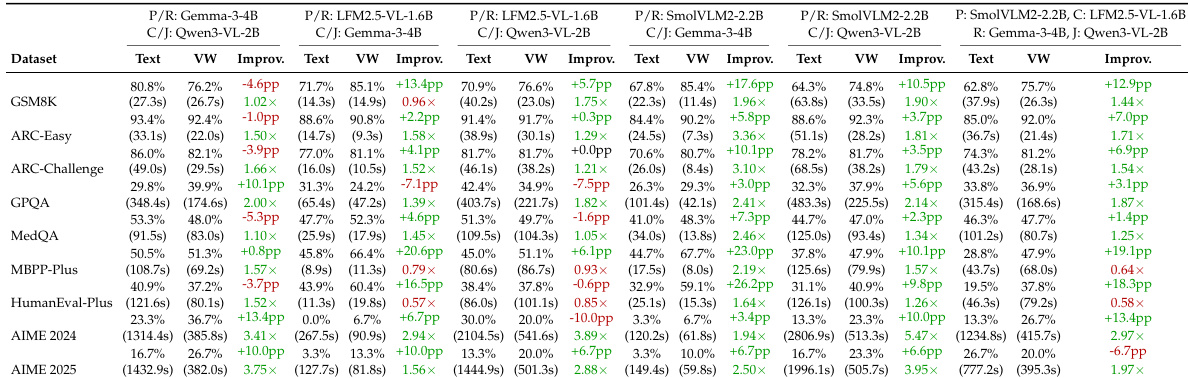
The authors use Vision Wormhole to replace text-based communication in multi-agent systems, observing that it consistently reduces inference time while often improving accuracy across diverse model pairings. Results show that performance gains vary by task and model strength, with stronger backbones sometimes experiencing accuracy tradeoffs under fixed communication bandwidth. The method proves robust under weak supervision and maintains more stable runtime distributions compared to text-based exchange.